В задачах математической физики — радиационной магнитогидродинамики, гидродинамики, теплопроводности — широко применяются неструктурированные расчётные сетки. Такие сетки не накладывают ограничений на форму ячеек и допускают локальное измельчение в зонах повышенного интереса. Рост размера сеток до миллионов элементов при решении крупномасштабных задач делает невозможной обработку на последовательных вычислительных архитектурах и требует перехода к параллельным распределённым вычислениям на системах с раздельной памятью.
Программный комплекс MARPLE3D, разработанный в ИПМ им. М. В. Келдыша РАН, реализует вычисления на неструктурированных сетках для задач радиационной МГД [1]. Центральным элементом его сеточной инфраструктуры является система хранения бинарных отношений инцидентности между элементами сетки — классы OrntRelation (ориентированное отношение) и relation (неориентированное). Оба класса используют формат сжатых строк (CSR): массив p_array задаёт смещения, массив e_array — значения образов. При ориентированном хранении знак значения кодирует направление инцидентности.
В бакалаврской работе проведён анализ данных классов и выявлены ограничения существующей реализации. Операции изменения топологии del_from и del_to реализованы через сдвиг массива e_array и имеют сложность O(n), что критично при адаптивном измельчении сетки. Профилирование операции refineMesh показало, что указанные методы занимали 34 % суммарного процессорного времени. Кроме того, в методе read применялся оператор goto, несовместимый со стандартом C++17. Отсутствие двухуровневой нумерации элементов не позволяет организовать прозрачную работу с ghost-элементами при MPI-разбиении сетки.
В результате оптимизации массив e_array типа std::vector
Таблица 1
Сложность ключевых операций до и после оптимизации
|
Операция |
Исходная реализация (CSR) |
Оптимизированная (forward_list) |
|
Доступ к i-му списку образов |
O(1) |
O(1) |
|
Вставка нового образа |
O(n) |
O(1) |
|
Удаление образа (del_to) |
O(n) |
O(k), k ≪ n |
|
Удаление источника (del_from) |
O(n) |
O(1) |
Для поддержки распределённых параллельных вычислений разработана архитектура трёх взаимосвязанных классов, надстраивающихся над оптимизированными OrntRelation и relation. Класс GlobalID реализует двухуровневую нумерацию: преобразование локальный↔глобальный индекс выполняется за O(1) без коммуникаций через вектор прямого доступа и хэш-таблицу; глобальное смещение вычисляется однократно через MPI_Scan [2]. Класс GhostZoneManager инкапсулирует декомпозицию сетки через ParMETIS [3] и управление ghost-элементами: метод decompose() строит двойственный граф и вызывает ParMETIS_V3_PartKway, метод sync() обновляет данные ghost-элементов через неблокирующие операции MPI_Isend / MPI_Irecv / MPI_Waitall, что открывает возможность совмещения коммуникаций с вычислениями. Класс OrntRelationMPI надстраивается над OrntRelation и предоставляет прикладному коду единый прозрачный интерфейс: методы isGhost(i), isOwned(i), syncGhost(field). Общая схема взаимодействия компонентов представлена на рис. 1.
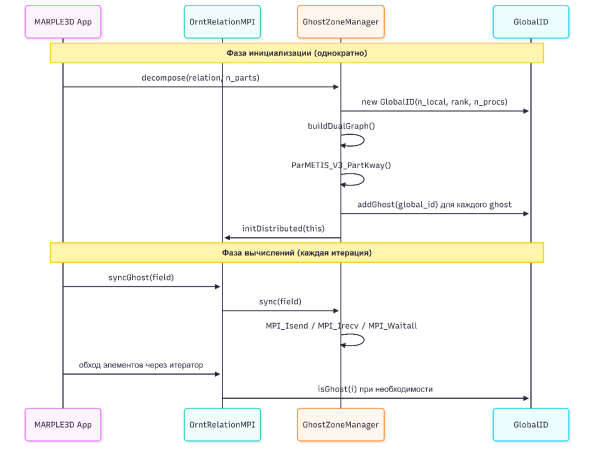
Рис. 1. UML-диаграмма взаимодействия компонентов распределённой архитектуры
При однопроцессорном запуске система работает идентично исходной реализации: GhostZoneManager::decompose() обрабатывает случай n_procs = 1 без обращения к ParMETIS, что гарантирует обратную совместимость и позволяет верифицировать корректность результатов сравнением с последовательным расчётом. Оценка коммуникационных накладных расходов: при качественном разбиении число граничных пар |∂E| ≈ O(N^(2/3)) для трёхмерных сеток, что значительно меньше общего числа рёбер |E| ≈ O(N) — коммуникационная нагрузка растёт медленнее объёма вычислений, что является необходимым условием масштабируемости.
В результате работы решены две взаимосвязанные задачи. Первая — оптимизация последовательной реализации: ускорение refineMesh на 19,1 % при полной обратной совместимости. Вторая — разработка архитектуры классов GlobalID, GhostZoneManager и OrntRelationMPI для распределённых вычислений с MPI и ParMETIS, обеспечивающей двухуровневую нумерацию и масштабируемую синхронизацию ghost-элементов. Разработанные решения могут быть применены при модернизации MARPLE3D и аналогичных исследовательских кодов. В дальнейшем планируются реализация классов в полном объёме и вычислительные эксперименты на кластерных системах.
Литература:
- Болдарев А. С., Гасилов В. А., Ольховская О. Г. и др. MARPLE: программное обеспечение для мультифизического моделирования в задачах сплошных сред // Препринты ИПМ им. М. В. Келдыша. — 2023. — № 37. — 40 с.
- Gropp W., Lusk E., Skjellum A. Using MPI: Portable Parallel Programming with the Message Passing Interface. — 3rd ed. — MIT Press, 2014. — 374 p.
- Karypis G., Kumar V. A Fast and High-Quality Multilevel Scheme for Partitioning Irregular Graphs // SIAM Journal on Scientific Computing. — 1998. — Vol. 20, № 1. — P. 359–392.
- Meyers S. Effective Modern C++. — O'Reilly Media, 2014. — 334 p.
- Василевский Ю. В. и др. INMOST — программная платформа для разработки параллельных численных моделей на сетках. — М.: Изд-во МГУ, 2013. — 144 с.

