The paper investigates the possibility of using Gold sequence segments for error-correcting coding in discrete channels with a probability of bit error. The algorithms of encoding (changing the phase of the segment) and decoding (the method of the verification segment with decimations) are proposed. The probability of correct reception as a function of the probability of error in the channel is obtained for different code lengths n (70, 90, 110 bits) and values of the decimation index σ (0, 1, 2). It is shown that for n = 90 bits, σ = 2, and the number of check symbols
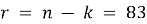
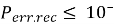
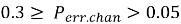
Keywords: error-correcting coding (ECC), Gold sequences, decimation, verification segment.
Введение
Современные системы профессиональной подвижной радиосвязи работают в условиях, когда плотность радиоэлектронных средств растёт, источники непреднамеренных помех множатся, а средства радиоэлектронного подавления становятся доступнее. Абонентские терминалы должны оставаться лёгкими и экономичными — сложные алгоритмы декодирования (турбокоды, LDPC) применять неэффективно. Особенно остро проблема стоит при
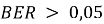
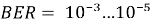
Альтернатива — коды Голда. Они формируются сложением по модулю 2 двух М-последовательностей, обладают хорошими корреляционными свойствами и допускают декодирование с линейной вычислительной сложностью [1, 2]. Однако их поведение при
Цель работы — разработать имитационную модель для исследования помехоустойчивого кодирования на сегментах последовательностей Голда в условиях
Исходные параметры и модель канала
В качестве базовых приняты параметры, характерные для стандартов профессиональной подвижной радиосвязи. Скорость передачи данных
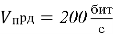
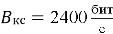
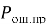
Теоретически ЛРР с данной степенью полинома генерирует М-последовательность максимальной длины
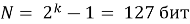
Порождающие полиномы подобраны как двойственная пара:
P 1 (x) =x ⁷ + x ⁶ + 1
P 2 (x) = x ⁷ + x + 1
Максимальная длина кодового слова n (сегмента) определяется из условия согласования пропускной способности канала и скорости передачи:
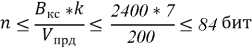
Для исследования взяты три значения различных длин кода: 70, 90 и 110. Полная вероятность ошибки кодовой комбинации в канале без кодирования оценивается по формуле:
P
ош
=
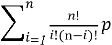
где n — длина кода;
i — количество искажённых символов (переменная суммирования);
p — вероятность искажения одного символа;
(1– p ) — вероятность правильного приёма одного символа;
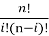
Алгоритмы кодирования и декодирования
Кодер работает по следующей схеме. Два генератора на линейных рекуррентных регистрах с обратными связями формируют сегменты М-последовательности. Первый генератор кодирует информацию отправителя изменением фазы сегмента. Второй генератор вместе с датчиком начального заполнения задаёт цикл обработки в декодере. Два сегмента складываются по модулю 2 — получается последовательность Голда, которая отправляется в канал.
Декодирование базируется на математическом аппарате конечных полей [4]. Любой член рекуррентной последовательности можно выразить через корни характеристического многочлена и коэффициенты из расширенного поля. Для последовательности Голда, полученной из двух М-последовательностей, характеристический многочлен P ( x ) = P ₁( x )· P ₂( x ) имеет степень 14.
Вычислены коэффициенты αᵢ и βᵢ . Они позволяют по любому безошибочному участку длины 2 k = 14 бит восстановить начальную фазу последовательности Голда. Это свойство используется в методе зачётного отрезка.
Декодер работает так. Принятая последовательность поступает в регистр RG 1 (линия задержки на 14 бит). Производящие матрицы F 1 пр и F 2 пр преобразуют 14-битовый параллельный код в k -битовые последовательности, которые сравниваются с выходами однотактовых умножителей T 1 и T 2 . Схема сравнения фиксирует совпадения, счётчик считает подряд идущие совпадения до порога m. Условие m > k гарантирует надёжное выделение зачётного участка. Длина зачётного отрезка n ₀ = k + m . Как только m достигнуто, декодер переходит в автономный режим. Когда схема сравнения фиксирует совпадение с цикловым фазированием, процесс завершается, и выдаётся декодированная комбинация.
Имитационная модель и программная реализация
Для исследования разработано программное средство на языке программирования Python . Оно реализует следующие функции:
вычисляет корни характеристического многочлена, производную, обратные элементы в поле GF (2 7 ).
реализует кодер с выбором значений состояния ДНЗ, длины кода n (70, 90, 110 бит) и информационного блока.
реализует декодер с вносимой ошибкой с заданной вероятностью (от 0,001 до 0,5).
Моделирование проводилось в дискретном стационарном канале без памяти. Ошибки вносились независимо с вероятностью p , распределение биномиальное (соответствует аддитивному белому гауссовскому шуму) [5].
Результаты моделирования
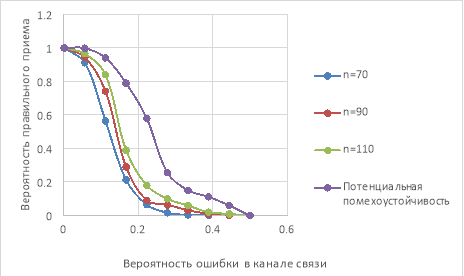
Рис. 1. График зависимости вероятности правильного приёма от вероятности ошибки в канале связи
На рисунке 1 показана зависимость вероятности правильного приёма от вероятности ошибки в канале для разных длин кода n : 70, 90 и 110 бит. При p = 0,2 ( BER = 0,2) вероятность правильного приёма для n = 70 бит падает ниже 0,6, для n = 90 бит — держится около 0,75, для n = 110 бит — превышает 0,85. Увеличение длины кода повышает помехоустойчивость — ценой роста избыточности ( r = n — k увеличивается). 90 — разумный компромисс.
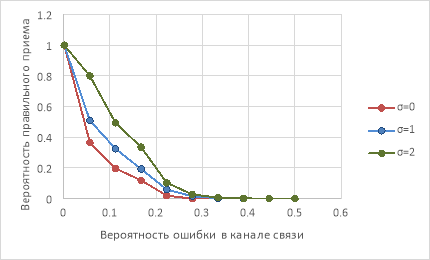
Рис. 2. График зависимости вероятности ошибки на приёме от вероятности ошибки в канале связи при заданном коэффициенте децимации
На рисунке 2 — зависимость от индекса децимации σ при фиксированной длине кода.
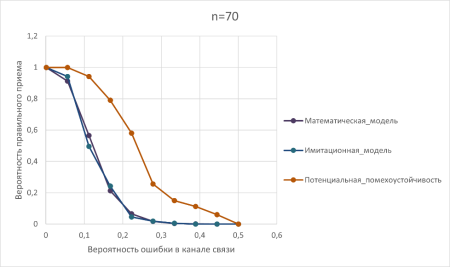
Рис. 3. График зависимости вероятности правильного приёма от вероятности ошибки в канале связи при исследовании математической и имитационной модели
На рисунке 3 сравниваются математическая и имитационная модели. Расхождение не превышает 5–7 %, что подтверждает адекватность модели.
Ещё один важный результат: при использовании децимации с σ = 2 код способен корректно восстанавливать информацию при кратности ошибок Δ = N — n ₀ , где n ₀ = k + m . Для выбранных параметров N = 127, k = 7, m = 10…15, получаем Δ порядка 100–105 бит. Декодеру нужен не весь сегмент, а всего 14 безошибочных бит в правильном месте.
Заключение
Разработана имитационная модель системы помехоустойчивого кодирования на основе сегментов последовательностей Голда, адаптированная для
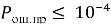
Линейная вычислительная сложность алгоритмов подтверждена. Результаты могут использоваться при модернизации абонентских терминалов.
Литература:
1. Лосев В. В. Обнаружение последовательностей Голда при помощи быстрых преобразований // Радиотехника и электроника. — 1981. — Т. 26, № 8. — С. 1660–1665.
2. Majhi S., Shelke K., Mitra P., Biswas U. Improving Channel Estimation Through Gold Sequences // arXiv preprint arXiv:2512.00509. — 2025.
3. Питерсон Ч., Уэлдон Э. Коды, исправляющие ошибки / Пер. с англ. — М.: Мир, 1976. — 594 с.
4. Когновицкий О. С. Теория, методы и алгоритмы решения задач в телекоммуникациях на основе двойственного базиса и рекуррентных последовательностей: монография. — СПб: СПбГУТ, 2011. — 340 с.
5. Морлос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение / Пер. с англ. В. Б. Афанасьева. — М.: Техносфера, 2006. — 319 с.

