Введение
Современные вычислительные инфраструктуры характеризуются высокой степенью изменчивости эксплуатационных параметров, что делает задачу мониторинга состояния виртуальных машин не только задачей фиксации текущих значений метрик, но и задачей выявления неблагоприятных тенденций их изменения [1]. В прикладной практике для контроля используются показатели загрузки центрального процессора, использования оперативной памяти, заполнения дисковой подсистемы и другие временные ряды, отражающие поведение объекта наблюдения во времени. При этом традиционный пороговый подход позволяет регистрировать уже наступившее превышение допустимого уровня, но не обеспечивает достаточной чувствительности к ситуациям, при которых текущее значение еще находится в допустимой области, однако демонстрирует устойчивый рост и с высокой вероятностью достигнет критического уровня в ближайшем будущем.
В условиях эксплуатации высоконагруженных инфраструктур подобное ограничение приобретает особую значимость. Позднее обнаружение роста нагрузки может привести к ухудшению качества обслуживания, исчерпанию ресурсов и возникновению отказов, тогда как своевременное прогнозирование критического состояния позволяет заранее инициировать корректирующие действия. В связи с этим актуальной становится задача построения вычислительно эффективного и интерпретируемого алгоритма предиктивного анализа, устойчивого к выбросам и пригодного для обработки эксплуатационных временных рядов.
Целью настоящей статьи является исследование применения и разработка робастного алгоритма [2] предиктивного анализа для мониторинга состояния виртуальных машин. Под робастностью в данном случае понимается устойчивость алгоритма к единичным аномальным наблюдениям и локальным колебаниям, не отражающим действительную тенденцию развития процесса.
Разработка алгоритма
В основу алгоритма положено разделение данных на базовое и краткосрочное окно. Базовое окно отражает длительную историю изменения метрики и используется для оценки типичного диапазона ее поведения. Краткосрочное окно содержит последние наблюдения и характеризует актуальную динамику показателя.
Пусть базовый ряд задается формулой (1), а краткосрочный ряд формулой (2).
|
|
(1) |
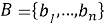
где
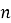
|
|
(2) |
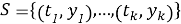
где
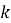
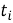
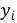
На первом этапе по базовому ряду строится робастная верхняя граница типичного поведения. Для этого после упорядочивания значений вычисляются квартили и межквартильный размах [3], представляющий разницу первого и третьего квартиля. На их основе формируется верхняя граница допустимого диапазона по формуле (3).
|
|
(3) |
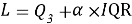
где
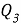
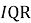
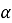
Использование межквартильного размаха позволяет ослабить влияние экстремальных значений, поскольку оценка строится на центральной части распределения, а не на среднем значении, чувствительном к выбросам.
Одновременно по базовому ряду определяется медиана, которая используется как робастная характеристика типичного уровня метрики. В отличие от среднего арифметического, медиана слабо реагирует на единичные аномальные наблюдения и потому более подходит для анализа эксплуатационных данных.
После формирования базовых характеристик выполняется быстрая проверка текущего состояния. Если последнее значение краткосрочного ряда превышает построенную верхнюю границу, фиксируется уже наступившее аномальное отклонение. Дополнительно анализируется возможность резкого скачка, где если последнее значение заметно выше предыдущего и одновременно существенно превышает типичный уровень, такое состояние интерпретируется как резкое ухудшение даже в том случае, когда формальная верхняя граница еще не была пересечена. Данный механизм позволяет выявлять кратковременные, но значимые изменения нагрузки. Если быстрые условия не выполняются, алгоритм переходит к более глубокой обработке краткосрочного ряда. Для уменьшения влияния единичных выбросов по краткосрочному интервалу рассчитываются медиана и медиана абсолютных отклонений. После этого из ряда исключаются точки, отклонение которых от медианы превышает допустимый уровень, задаваемый коэффициентом фильтрации. В результате формируется очищенный ряд, отражающий основную динамику процесса без случайных всплесков.
Следующий этап связан с построением линейной модели тренда по отфильтрованным точкам. Для этого временные координаты переводятся в числовую шкалу относительно первого наблюдения, после чего методом наименьших квадратов определяется линейная зависимость (4).
|
|
(4) |
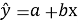
где
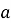
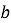
Если коэффициент наклона отрицательный, то возрастающий тренд отсутствует, и формирование предиктивного предупреждения не выполняется. Если же тренд положителен, рассчитывается прогнозное значение на заданном горизонте наблюдения и сопоставляется с ранее построенной робастной верхней границей. Если прогноз показывает, что при сохранении текущего темпа изменения показатель достигнет или превысит допустимую границу в пределах горизонта анализа, формируется предиктивное предупреждение. Для дополнительного снижения числа ложных срабатываний учитывается также минимально значимый прирост прогнозного значения относительно текущего уровня.
Важной особенностью предложенного алгоритма является сочетание нескольких классов признаков. Первый класс отражает уже наблюдаемое превышение типичного диапазона. Второй связан с локальными скачками относительно предыдущего измерения и базовой медианы. Третий базируется на сглаженной оценке тренда и позволяет выявлять потенциальное достижение критической области в будущем. Такое объединение нескольких логик анализа позволяет сделать алгоритм более устойчивым по сравнению с использованием единственного критерия.
С точки зрения математического аппарата предложенный подход представляет собой комбинирование робастной статистики и простой параметрической модели краткосрочного прогноза. Робастные характеристики используются для построения базового уровня и фильтрации аномальных точек, а линейная регрессия для описания текущего тренда. Подобная комбинация является практически оправданной, поскольку инфраструктурные временные ряды часто не удовлетворяют требованиям стационарности и могут содержать шум, делающий применение более чувствительных методов затруднительным.
Вычислительная сложность
Отдельного внимания заслуживает вычислительная сложность алгоритма. Основной вклад в трудоемкость вносят этапы сортировки данных при вычислении квартилей, медианы и медианы абсолютных отклонений. Для базового окна размером
|
|
(5) |
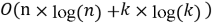
Тогда как дополнительная память определяется хранением рабочих копий данных и оценивается величиной порядка формулы (6).
|
|
(6) |
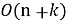
Эти свойства позволяют применять алгоритм для большого числа метрик без чрезмерной вычислительной нагрузки и подтверждают его пригодность для практического использования в системах мониторинга.
Апробация
Апробация алгоритма проводилась на данных, получаемых при мониторинге виртуальных машин. Результаты нагрузочных испытаний показали, что время выполнения предиктивной оценки одной метрики составляет порядка 1104 наносекунд в однопоточном режиме и около 469 наносекунд при параллельном запуске. При моделировании одновременной обработки 100 виртуальных машин суммарное время предиктивной оценки оставалось в пределах микросекундного диапазона.
Вывод
Предложенный алгоритм позволяет дополнить традиционный пороговый мониторинг механизмом раннего выявления неблагоприятных состояний виртуальных машин. Его математическая основа опирается на устойчивые статистические характеристики распределения и простую регрессионную модель краткосрочного прогноза, что обеспечивает приемлемый баланс между точностью, интерпретируемостью и вычислительной сложностью. Перспективы дальнейшего развития данного направления связаны с адаптацией параметров анализа к различным профилям нагрузки, расширением набора учитываемых метрик, а также с исследованием гибридных моделей, сочетающих робастные статистические процедуры с методами машинного обучения.
Литература:
- Особенности мониторинга виртуальной IT-инфраструктуры / А. А. Данильчук. — Текст: электронный // sci-article.ru: [сайт]. — URL: https://sci-article.ru/stat.php?i=osobennosti_monitoringa_virtualnoy_it-infrastruktury (дата обращения: 02.05.2026).
- Робастная оптимизация: компромисс оптимальности и валидности решения. — Текст: электронный // Habr: [сайт]. — URL: https://habr.com/ru/articles/751226/ (дата обращения: 03.05.2026).
- Межквартильный размах: измерение разброса данных в квартилях, обновление. — Текст: электронный // FasterCapital: [сайт]. — URL: https://fastercapital.com/ru/content/Межквартильный-размах--измерение-разброса-данных-в-квартилях--обновление.html (дата обращения: 03.05.2026).

