Одним из ключевых направлений в развитии искусственного интеллекта в последнее время становятся большие языковые модели (large language models, LLM) — нейронные сети, разрабатываемые для понимания и генерации текста, похожего на человеческий. Ставшие прорывом в области генеративного ИИ, LLM используются для широкого спектра NLP-задач. Наибольшую популярность приобрели основанные на LLM интеллектуальные помощники (агенты), способные заменять человека в задачах коммуникации с клиентами, сбора информации и предоставления типовых консультаций. Такие агенты сейчас активно внедряются во многие информационные системы.
LLM модели обладают внушительными размерами, имеют более миллиарда параметров, обучаются на огромных массивах данных и требует больших вычислительных затрат и ресурсов. Создание полноценной LLM — это трудоемкий, дорогостоящий и ресурсоемкий процесс, который обычно требует значительных усилий целой команды людей.
В связи с трудностью обучения LLM популярность стали набирать малые языковые модели (small language models, SLM). Они имеют на порядок меньше параметров, что делает возможным их обучение и использование в ситуации ограниченности ресурсов для решения узкоспециализированных задач, связанных с обработкой естественного языка. Однако снижение размерности параметров модели ведет к значительным потерям в точности, особенно в части задач, требующих обобщения информации и сложных многоступенчатых рассуждений.
Одним из перспективных подходов к преодолению данного ограничения является дистилляция знаний — процесс передачи знаний от большой модели-учителя к компактной модели-ученику [1]. Схема дистилляции знаний приведена на Рисунке 1.
![Дистилляция знаний при обучении моделей [2]](https://articles-static-cdn.moluch.org/articles/j/132395/images/132395-1.png)
Рис. 1. Дистилляция знаний при обучении моделей [2]
Классическая дистилляция знаний предполагает обучение модели-ученика на выходных данных модели-учителя. В простейшем варианте ученик обучается воспроизводить конечный ответ учителя, что эффективно для задач классификации, но недостаточно для генеративных задач. В более общем случае используется soft-дистилляция, при которой минимизируется расхождение между распределениями вероятностей, генерируемыми учителем и учеником, например, с помощью KL-дивергенции.
Дальнейшее развитие получили методы Chain-of-Thought (CoT) [3] дистилляции, в которых в обучающую выборку включаются промежуточные шаги рассуждений, сформированные моделью-учителем. Такой подход позволяет ученику усваивать структуру логического вывода и улучшает качество решения сложных задач. Вместе с тем классическая CoT-дистилляция обладает существенным недостатком — ошибки и неточности, допущенные моделью-учителем на промежуточных этапах, переносятся в обучающую выборку, что негативно сказывается на итоговом качестве малой модели.
В рамках данной работы предлагается и описывается метод дистилляции, ориентированный на передачу не только конечных ответов, но и промежуточных шагов рассуждений с использованием модуля обратной связи. Подробная схема подхода обучения SLM модели для алгоритма дистилляции с обратной связью представлена на Рисунке 2.

Рис. 2. Алгоритм обучения малой языковой модели методом дистилляции с обратной связью
Эксперименты проводились на наборе данных GSM8K [4], содержащем 8500 текстовых математических задач для учеников начальной школы с ответами в несколько этапов рассуждений. Датасет был предварительно предобработан, очищен и разбит на тренировочную, валидационную и тестовую выборки с учётом сложности задач для избежания дисбаланса классов.
В качестве модели-учителя для исследования была выбрана предобученная LLM — google/flan-t5-large, в качестве модели-ученика google/flan-t5-small. Flan-T5 отличаются хорошей точностью в сочетании с небольшим количеством параметров и простотой архитектуры, что делает их удобными для использования в алгоритме дистилляции знаний.
В рамках исследования были реализованы и сравнены три подхода: baseline-дистилляция, CoT-дистилляция и предложенный метод дистилляции с обратной связью. Все алгоритмы были реализованы на языке программирования Python, в качестве фреймворков для работы с нейросетевыми моделями использовались PyTorch и Transformers.
Графики функций потерь, полученных во время обучения, приведены на Рисунке 4.
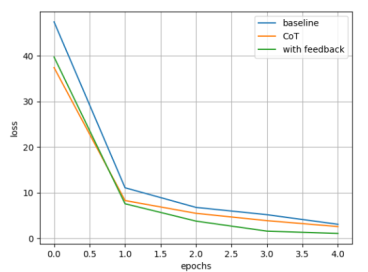
Рис. 4. Графики функций потерь на валидационной выборке
Результирующие значения точности для алгоритмов представлены в Таблице 1.
Таблица 1
Метрика качества работы моделей нейронной сети, обученных с помощью различных алгоритмов дистилляции
|
Точность (accuracy) | |||
|
Тренировочная выборка |
Валидационная выборка |
Тестовая выборка | |
|
Baseline |
0,62 |
0,58 |
0,59 |
|
CoT |
0,70 |
0,66 |
0,71 |
|
С обратной связью |
0,81 |
0,72 |
0,75 |
Полученные в ходе эксперимента результаты показали, что предложенный метод дистилляции с обратной связью превосходит классические подходы по показателям точности на всех выборках. Существенным преимуществом является также сокращение средней длины цепочек рассуждений, что свидетельствует о том, что некоторые шаги, генерируемые моделью-учителем, являются избыточными или некорректными и могут быть опущены при обучении SML.
Анализ результатов подтверждает, что дистилляция промежуточных шагов с обратной связью позволяет снизить шум обучающей выборки и повысить устойчивость обучения малой языковой модели. Однако существуют и минусы в этом подходе, например, использование дополнительных модулей увеличивает вычислительную сложность алгоритма и значительно влияет на скорость обучения. Поэтому выбор оптимального алгоритма дистилляции для обучения малой языковой модели должен исходить из компромисса между качеством и затратами ресурсов.
Литература:
- Hinton, G. Distilling the Knowledge in a Neural Network / G. Hinton, O. Vinyals, J. Dean. — DOI: arXiv:1503.02531 // ArXiv. — 2015. — Vol. abs/1503.02531.
- What is LLM Distillation? // GeeksForGeeks. — [Б. м.], 2025. — URL: https://www.geeksforgeeks.org/nlp/what-is-llm-distillation/ (дата обращения: 08.01.2026).
- Ho, N. Large language models are reasoning teachers / N. Ho, L. Schmid, SY. Yun. // In Proceedings of the 61st annual meeting of the association for computational linguistics. — 2023. — Vol. 1. — P. 14852–14882.
- Dataset Card for GSM8K // Hugging Face. — [Б. м.], 2025. — URL: https://huggingface.co/datasets/openai/gsm8k/ (дата обращения: 08.01.2026).

