В статье описывается популярный и простой в использовании язык программирования Python, используемый для обработки больших данных, и его основные библиотеки для обработки данных. Функции Python делают его идеальным для анализа данных, он прост в освоении, надежен, удобочитаем, масштабируем, имеет обширный набор библиотек, интеграцию с другими языками, а также активное сообщество и систему поддержки.
Ключевые слова : обработка данных, большие данные, Python, pandas, numpy.
The article describes Python, a widely used, easy-to-use programming language for large data processing, and its main libraries for data processing. Python's features make it easy to learn, reliable, readable, scalable, a wide range of libraries, integration with other languages, and ideal for data analysis for an active community and support system.
Keywords : data processing, Big Data, Python, pandas, numpy.
Большие данные — это большие объемы структурированных или неструктурированных данных. Они обрабатываются специальными автоматизированными инструментами, используемыми для статистики, анализа, прогнозирования и принятия решений.
С 2014 года ведущие университеты мира делают упор на Big Data, обучая прикладным инженерным и IT-специальностям. Затем к сбору и анализу присоединились такие ИТ-корпорации, как Microsoft, IBM, Oracle, EMC, а затем Google, Apple, Facebook и Amazon. Сегодня большие данные используются крупными компаниями во всех отраслях, а также государственными структурами [1].
Необработанные данные не имеют ценности. Для преобразования и анализа больших данных требуются инструменты и языки программирования. Существует множество специальных инструментов и языков программирования, которые помогут вам автоматизировать процесс и сэкономить время.
Несколько языков программирования были разработаны для обработки больших объемов данных и они Pandas (для анализа данных) вокруг него сложилась целая экосистема библиотек и фреймворков.
Требования к программированию науки о данных требуют очень универсального, но гибкого языка, на котором легко писать код, но который может выполнять очень сложные математические операции.
Python лучше всего подходит для таких требований, потому что он зарекомендовал себя как язык как для общих вычислений, так и для научных вычислений. Кроме того, он постоянно пополняется новыми дополнениями к большому количеству библиотек, ориентированных на различные требования программирования [1].
При анализе данных и визуализации результатов Python является обязательным наряду с R, MATLAB, SAS, Stata и т. д. можно сравнить со многими языками программирования и такими инструментами, как относительно недавнее появление продвинутых библиотек для Python (прежде всего pandas) сделало его серьезным конкурентом в решении задач манипулирования данными [2].
Для работы с данными создано несколько специальных библиотек Python:
NUMPY (для численного анализа и формирования)
MATPLOTLIB (для визуализации данных)
SCIPY (для научных вычислений)
SEABORN (для визуализации данных)
TENSORFLOW (используется в глубоком обучении)
SCIKIT-LEARN (используется в машинном обучении)

Рис. 1. Библиотеки Python
Python в целом отлично подходит для анализа данных: с помощь него можно решать задачи автоматизации сбора и обработки данных и реализовать на работе новые подходы к анализу, например решать задачи с помощью обучения нейросетей.
В Pandas можно работать с данными трех структур:
— последовательности (Series) — одномерные массивы данных;
— фреймы (Data Frames) — объединение нескольких одномерных массивов в двумерный, то есть привычная таблица из строк и столбцов. Этот формат чаще всего используют аналитики;
— панели (Panels) — трехмерная структура из нескольких фреймов.
Библиотека пригодится всем, кто работает с данными, особенно аналитикам. С помощью Pandas можно группировать таблицы, очищать и изменять данные, вычислять параметры и делать выборки.
Библиотека Pandas предоставляет функции, которые упрощают и ускоряют работу со структурированными данными. Это один из ключевых компонентов, который делает Python таким мощным инструментом для анализа данных.
Pandas — отличный инструмент для обработки данных. Он предназначен для быстрой и простой обработки, чтения, интеграции и визуализации данных.
Pandas считывает данные из файлов CSV, TSV или базы данных SQL и создает объект Python со строками и столбцами, который называется DataFrame. Основным объектом в Pandas является DataFrame, двумерная таблица с помеченными строками и столбцами. DataFrame очень похож на таблицу в статистическом программном обеспечении, скажем, в Excel или SPSS [3].
С помощью Pandas:
- Индексация, редактирование, переименование, сортировка, объединение фреймов данных;
- Обновлять, добавлять, удалять столбцы во фрейме данных;
- Восстановление отсутствующих файлов, редактирование отсутствующих данных или NAN;
Построение графиков
В Pandas есть также инструменты для простой визуализации данных. Обычный график по точкам.
Рис. 2
Гистограмма. Отобразим ту же зависимость в виде столбчатой гистограммы:
Рис. 3
Точечный график.
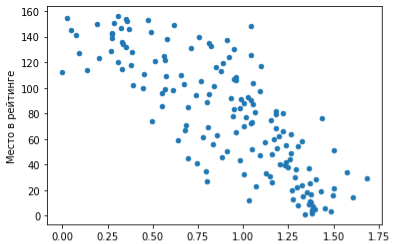
Рис. 4
Мы видим предсказуемую тенденцию: чем выше ВВП на душу населения, тем ближе страна к первой строчке рейтинга.
4. Постройте линейчатую или прямоугольную диаграмму NumPy — один из самых фундаментальных пакетов Python, универсальный пакет для работы с массивами. Он предоставляет высокопроизводительные объекты многомерного массива и инструменты массива.
NumPy — это эффективный контейнер для общих многомерных данных. Базовый объект NumPy представляет собой однородный многомерный массив. Это таблица элементов или чисел одного типа данных, индексированных набором натуральных чисел. В NumPy измерения называются осями, а количество осей — рангом. Класс массива NumPy — ndarray он же array.
NumPy используется для манипулирования массивами, в которых хранятся значения одного типа данных. NumPy упрощает выполнение математических операций с массивами и их векторизацию. Это значительно повышает производительность и, следовательно, ускоряет время выполнения.
Matplotlib — визуализация данных позволяет отображать их визуально, анализировать более подробно, чем в обычном формате, и более легко представлять их другим. Matplotlib — лучшая и самая популярная библиотека Python для этой цели. Это не так просто использовать, но вы можете научиться создавать их очень быстро с помощью наиболее распространенных 4–5 блоков кода для простых линейных диаграмм и точечных диаграмм.
Функции Python делают его идеальным для анализа данных, он прост в освоении, надежен, удобочитаем, масштабируем, имеет обширный набор библиотек, интеграцию с другими языками, а также активное сообщество и систему поддержки [3].
Python предоставляет множество библиотек и редакторов для эффективного анализа данных. Python — это самый быстрорастущий язык, используемый специалистами по обработке и анализу данных Youtube, Google и другими. Он используется с целью быстрого анализа.
Литература:
- Силен Дэви, Мейсман Арно, Али Мохамед. Основы Data Science и Big Data. Python и наука о данных. — СПб.: Питер, 2017. — 336 с.: ил. — (Серия «Библиотека программиста»).
- Ын Анналин, Су Кеннет. Теоретический минимум по Big Data. Всё, что нужно знать о больших данных. — СПб.: Питер, 2019. — 208 с.: ил. — (Серия «Библиотека программиста»).
- Мейсман Арно. Основы Data Science и Big Data. Python и наука о данных. 2016. — 322 c. Подробнее: https://www.labirint.ru/authors/181786/
- Top 10 Python Libraries for Data Science. https://towardsdatascience.com/top-10-python-libraries-for-data- science-cd82294ec266
- https://blog.skillfactory.ru/kak-nachat-analizirovat-dannye-v-pandas-pervye-shagi/
- https://practicum.yandex.ru/blog/pandas-dlya-analiza-dannyh/
продукт компании Meta, которая признана экстремистской организацией в России.

