





1. Introduction
In last ten years the web-development has faced a lot of new challenges and changes. Starting with the transition from web 1.0 to web 3.0 the transformation continued and JavaScript became the de facto language of the Web. It also meant the raise of JavaScript based frameworks as React JS, Angular, Vue JS, as well as the end of the epoch of JavaScript libraries as JQuery. Nowadays the change is still going on, and Rest APIs became obsolete and too overloaded when the new mechanism for data fetching GraphQL was introduced.
With these many changes in the sphere of front-end development the main trend remains the same: now the front-end, or the client side is not only responsible for rendering data in the browser, but for the logic as well.
The modern process of front-end development usually starts with the prototype development conducted by the UX/UI designers. The next step is to implement the user interface but not the hole — first broken into chunks called components. These components are the user interface elements that share the same appearance and the same behavior. This stage requires a lot of HTML/CSS knowledge from the developer.
However, the entire research proposes that this step can be skipped with the introduction of new revolutionary methods based on machine learning, neural networks, and deep learning algorithms. Automating the routine of writing code describing the layout of elements with HTML/CSS lets the developers focus their attention on functional part of development responsible for the logic of interaction instead of appearance. This can have a lot of economical outcomes as shortened time to market of online products and websites, rapid prototyping and idea validation, decreased amount of work hours of front-end developers as well as personnel optimization.
In the continuation of the chapter several recent researches on the code generation from prototypes and mockups will be considered. In the last 10 years the application of machine learning algorithms to different spheres of human life increased dramatically, that was caused by the rapid growth of cheap computer power available to conduct the massive calculations. Even though the most machine learning algorithms were introduced as early as 50’s of the last century, the opportunity to finally use their enormous power to make predictions, classifications and clasterization work emerged only in the second decade of 21st century. Machine learning found application in the spheres from medicine to marketing maximizing both profits for businesses and usefulness for customers. Machine learning can be classified based on the data set being used for the model training as supervised, unsupervised and semi-supervised. Based on the purpose it can also be related to one of the following groups: artificial intelligence, computer vision, natural language processing, etc.
The different researchers use different approach to data handling and data preparation. Thus, some of them use unmarked data and use unsupervised learning algorithms, while others exploit the power of semi-supervised learning which is applicable and effective in the cases when only limited amount of data is marked and the rest of it is not.
1.1. About Pix2Code
The work “Pix2Code” (Beltramelli, 2017) makes use of semi-supervised learning to generate code from the image of user interface. The program takes the image of interface as the only input data. The program is capable of producing codes for both multi-platform HTML/CSS use, or native Android or iOS applications. Pix2Code project makes the use of convolutional neural network (CNN) to map unlabeled data with learned representation using unsupervised learning. In the second step, the recurrent neural network (RNN) performs the text generation on the raw image input data. Both models are using gradient descent for optimization and preciser predictions.
The author of the research breaks the process of code generation from raw image input into three stages: the first one is computer vision stage, then uses CNN to define the presence and positions as well as color, size and styling features of the graphical user interface. The second step makes the use of RNN and Long short-term memory neural network (LSTM) to produce token-level language output. The third step is decoding when the mapping between the encoded into vector representation image input and the output language tokens takes place. The decoder is implemented as a stack of two LSTM layers containing 512 cells each. The accuracy of the model is 77 %. Usage of one-hot encoding is not capable to provide useful insights about the relationship between language tokens since the method simply assigns an arbitrary vector representation to each token. Hence, preliminary training of the language model to study vector representations would allow between the tokens in the DSL that will be displayed (that is, the study of word embeddings such as word2vec) and as a result, eliminate the semantic error in the generated code. In addition, one-hot encoding does not scale to a very large vocabulary and thus limits the amount of characters that DSL can support.
1.2. Next is RealMix
The same semi-supervised learning approach is utilized by V. Nair, J. F. Alonso and T. Beltramelli in their very recent research “RealMix: Towards Realistic Semi-Supervised Deep Learning Algorithms”. In their work RealMix the authors introduce a modern semi supervised learning approach that can improve classification performance. It performs effectively even when there is a considerable misproportion between the distributions of the unlabeled and the labeled data. RealMix is, according to the authors, the only SSL approach that can maintain baseline performance when there is a total detachment in the labeled and unlabeled distributions. This is important contribution especially when considering the application and usage of semi supervised learning in non-academic settings where datasets are noisy and include limited number of samples. The authors proved RealMix achieved state-of-the-art performance on common semi-supervised learning benchmarks such as SVHN and CIFAR10, notably achieving an error rate of 9.79 % on CIFAR10 using 250 labels. Additionally, we showed that using transfer learning techniques compliments our method to further reduce the error on CIFAR10 with 250 labels to just 8.48 %.
1. The methodological basis of the research
Research work starts with a thorough planning. Diving into the development of algorithm requires several steps of preparation. This chapter describes the steps done for the research, the methodology of research, the preparation of data, the preparation of development tools necessary for the research project.
The preparation started with the selection of the best suitable model to achieve the stated aim. The first part of the chapter discusses different machine learning approaches from supervised to unsupervised learning and neural networks. Then, the development tools are described in terms of their relevance and suitability for the project. Next, current trends of machine learning libraries are described. The fourth part of the current chapter describes the process of data preparation necessary to start the model training.
2.1. Analysis of algorithms
Machine learning algorithms provide a wide range of tasks that can be solved with their help.
Machine Learning is an extensive subsection of artificial intelligence that studies methods for constructing learning-capable algorithms. There are two types of training. Case-law training, or inductive training, is based on the identification of general patterns from empirical data. Deductive learning involves formalizing expert knowledge and transferring it to a computer in the form of a knowledge base. Deductive learning is usually referred to the field of expert systems, so the terms machine learning and case studies can be considered synonymous.
Machine learning is at the intersection of mathematical statistics, optimization methods, and classical mathematical disciplines, but also has its own specifics associated with problems of computational efficiency and retraining. Many inductive training methods have been developed as an alternative to classical statistical approaches. Many methods are closely related to data mining and data mining.
The most theoretical sections of machine learning are combined in a separate direction, the Computational Learning Theory (COLT).
Machine learning is not only mathematical, but also a practical, engineering discipline. Pure theory, as a rule, does not immediately lead to methods and algorithms that are applicable in practice. To make them work well, additional heuristics have to be invented to compensate for the discrepancy between the assumptions made in the theory of assumptions and the conditions of real problems. Almost no research in machine learning is complete without an experiment on model or real data, confirming the practical operability of the method.
2.1.1. Supervised learning
Teaching with a teacher (Supervised learning) is one of the sections of machine learning dedicated to solving the following problem. There are many objects (situations) and many possible answers (responses, reactions). There is some correlation between answers and objects, but it is unknown. Only the final set of precedents is known — the “object, response” pairs, called the training set. Based on these data, it is required to restore the dependence, that is, to construct an algorithm capable of producing a fairly accurate answer for any object. To measure the accuracy of answers, a quality functional is introduced in a certain way. The tables 1, 2 displays the typical input type and output data of supervised learning algorithms.
Table 1
Input types for supervised learning algorithms
|
Input Types |
Description |
|
A featured description or a matrix of feature objects is the most common case |
Each object is described by a set of its characteristics, called features. Attributes can be numeric or non-numeric. |
|
The matrix of distances between objects |
Each object is described by the distances to all other objects of the training set. Few methods work with this type of input data the method of nearest neighbors, the method of the Parzen window, the method of potential functions. |
|
Image or video |
|
|
A time series or signal is a sequence of measurements over time |
Each dimension can be represented by a number, a vector, and, in the general case, by a characteristic description of the object under study at a given time. |
|
Graphs, texts, results of queries to the database, etc. |
As a rule, they are reduced to the first or second case by preprocessing the data and extracting the attributes. |
Table 2
Output of supervised learning algorithms
|
Output type |
Description |
|
Classification tasks |
Many possible answers. They are called class identifiers (names, labels). |
|
Regression Tasks |
Answers are real numbers or vectors |
Supervised learning algorithms can be applied in many different spheres. The figure 1 shows some of them.
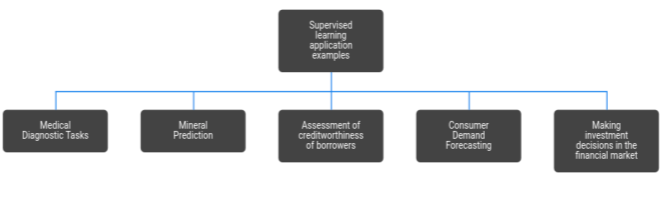
Fig. 1. Examples of application of supervised learning algorithms
a) Medical Diagnostic Tasks. The objects are patients. Signs characterize the results of examinations, symptoms of the disease and the methods of treatment used. Examples of binary signs: gender, headache, weakness. An ordinal sign is the severity of the condition (satisfactory, moderate, severe, extremely severe). Quantitative signs — age, pulse, blood pressure, hemoglobin in the blood, dose of the drug. The characteristic description of the patient is, in fact, a formalized medical history. Having accumulated enough precedents in electronic form, it is possible to solve various problems:
– classify the type of disease (differential diagnosis)
– determine the most appropriate method of treatment
– predict the duration and outcome of the disease
– assess the risk of complications
– to find syndromes — the most characteristic set of symptoms for a given disease.
The value of such systems is that they can instantly analyze and generalize a huge number of precedents — an opportunity not available to a specialist doctor.
b) Mineral Prediction. The signs are geological exploration data. The presence or absence of certain breeds in the district is encoded by binary signs. The physicochemical properties of these rocks can be described both quantitatively and qualitatively. The training sample is made up of precedents of two classes: areas of known deposits and similar areas in which the mineral of interest was not found. When searching for rare minerals, the number of objects can be much less than the number of signs. In this situation, classical statistical methods do not work well. The problem is solved by searching for patterns in the existing data array. In the process of solving, short sets of features are selected that have the most informativeness — the ability to best separate classes. By analogy with the medical task, we can say that “syndromes” of deposits are being sought. This is an important by-product of the study, of considerable interest to geophysicists and geologists.
c) Assessment of creditworthiness of borrowers. This problem is solved by banks when issuing loans. The need to automate the process of issuing loans first arose during the boom of credit cards of the 60–70s in the USA and other developed countries. The objects in this case are individuals or legal entities applying for a loan. In the case of individuals, an indicative description consists of a questionnaire that the borrower fills out, and possibly additional information that the bank collects about it from its own sources. Examples of binary signs: gender, telephone availability. Nominal signs — place of residence, profession, employer. Ordinal signs — education, position held. Quantitative signs — loan amount, age, work experience, family income, amount of debts in other banks. The training sample is made up of borrowers with a known credit history. In the simplest case, decision-making boils down to classifying borrowers into two classes: “good” and “bad”. Loans are granted only to first-class borrowers. In a more complex case, the total number of points (score) of the borrower scored based on a set of informative features is estimated. The higher the rating, the more reliable the borrower is considered. Hence the name — credit scoring. At the training stage, the synthesis and selection of informative features is carried out and it is determined how many points to assign for each feature so that the risk of decisions being made is minimal. The next task is to decide on what conditions to grant a loan: determine the interest rate, maturity, and other parameters of the loan agreement. This problem can also be solved by teaching methods on precedents.
d) Consumer Demand Forecasting. It is solved by modern supermarkets and retail chains. For effective management of the distribution network, it is necessary to predict the sales volumes for each product for a given number of days in advance. Based on these forecasts, procurement planning, assortment management, pricing policy development, and planning of promotions (advertising campaigns) are carried out. The specifics of the problem is that the number of goods can be in the tens or even hundreds of thousands. Predicting and making decisions on each product “manually” is simply unthinkable. The initial data for forecasting are time series of prices and sales volumes for goods and for individual stores. Modern technology allows you to remove this data directly from cash registers. To increase the accuracy of forecasts, it is also necessary to consider various external factors affecting consumer demand: inflation, weather conditions, advertising campaigns, socio-demographic conditions, and activity of competitors. Depending on the objectives of the analysis, the objects are either goods, or stores, or “store, product” pairs.
e) Making investment decisions in the financial market. In this task, the ability to forecast well turns into profit in the most direct way. If the investor assumes that the share price rises, he buys the shares, hoping to sell them later at a higher price. Conversely, predicting a fall in prices, the investor sells shares in order to subsequently buy them back at a lower price. The task of the investor-speculator is to correctly predict the direction of future price changes — growth or fall. Very popular are automatic trading strategies, algorithms that make trading decisions without human intervention. The development of such an algorithm is also a task of training with a teacher. The objects are situations, in fact, time instants. Description of the object — this is the whole history of changes in prices and trading volumes, fixed to this moment. In the simplest case, objects must be classified into three classes that correspond to possible solutions: buy, sell, or wait. The training sample for setting up trading strategies is historical data on the movement of prices and volumes over a certain period. The quality criterion in this problem differs significantly from the standard functional of the average error, since the investor is not interested in the accuracy of forecasting, but in maximizing the total profit. Modern stock market technical analysis has hundreds of parametric trading strategies, the parameters of which are customary to adjust according to the criterion of maximum profit in the selected history interval.
2.1.2. Semi supervised learning
Partial learning (semi-supervised learning) is one of the methods of machine learning that uses both labeled and unallocated data in training. Usually a small amount of tagged and a significant amount of untagged data is used. Partial learning is a trade-off between learning without a teacher (without any labeled learning data) and learning with a teacher (with a fully labeled learning set). It was noted that unlabeled data, when used in conjunction with a small amount of labeled data, can provide a significant increase in the quality of training. Under the quality of training is meant a certain quality functional, for example, the standard error. Collecting tagged data for a learning task often requires a qualified expert to manually classify learning objects. The costs associated with the markup process can make the construction of a fully labeled set of use cases impossible, while collecting unallocated data is relatively inexpensive. In such situations, the value of partial training is difficult to overestimate.
An example of partial training is co-training: two or more trained algorithms use the same data set, but each training uses different — ideally uncorrelated — sets of features of objects. An alternative approach is to model the joint distribution of features and labels. In this case, for untagged data, labels can be treated as missing data. To construct the maximum likelihood estimate, the EM algorithm is usually used.
EM-algorithm (expectation-maximization) is an algorithm used in mathematical statistics to find estimates of the maximum likelihood of the parameters of probabilistic models, in the case when the model depends on some hidden variables. Each iteration of the algorithm consists of two steps. At the E-step (expectation), the expected value of the likelihood function is calculated, while the hidden variables are considered observable. At the M-step (maximization), the maximum likelihood estimate is calculated, thus increasing the expected likelihood calculated at the E-step. This value is then used for the E-step in the next iteration. The algorithm is executed until convergence.
As a rule, the EM algorithm is used to solve two types of problems.
The first type includes tasks related to the analysis of truly incomplete data, when some statistics are not available for any reason.
The second type of tasks includes those tasks in which the likelihood function has the form that does not allow convenient analytical research methods, but allows serious simplifications if additional “unobservable” (hidden, latent) variables are introduced into the task. Examples of applied problems of the second type are the problems of pattern recognition, image reconstruction. The mathematical essence of these problems consists of the tasks of cluster analysis, classification and separation of mixtures of probability distributions.
Let the distribution density on the set X have the form of a mixture of k distributions:
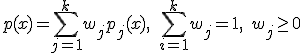
(3)
where
![]() — is the probability function of the j-th component of the mixture,
— is the probability function of the j-th component of the mixture,
![]() — is priori probability.
— is priori probability.
Let the probability functions belong to the parametric distribution family
The task of separating the mixture is that, having a sample of ![]() random and independent observations from the mixture
random and independent observations from the mixture ![]() , knowing the number k and the
, knowing the number k and the ![]() function, estimate the parameter vector
function, estimate the parameter vector
![]() (4)
(4)
The idea of the algorithm is as follows. An auxiliary vector of hidden variables G, which has two remarkable properties, is artificially introduced.
On the one hand, it can be calculated if the values of the parameter θ are known.
On the other hand, the search for maximum likelihood is greatly simplified if the values of the hidden variables are known.
The EM algorithm consists of iterative repetition of two steps.
At the E-step, the expected value of the vector of hidden variables G is calculated by the current approximation of the parameter vector θ.
2.1.3. Unsupervised learning
Unsupervised learning is one of the areas of machine learning. It studies a wide class of data processing problems in which only descriptions of a multitude of objects (training set) are known, and it is required to discover the internal relationships, dependencies, patterns that exist between objects. Learning without a teacher is often contrasted with learning with a teacher, when for each learning object the “correct answer” is set, and it is required to find the relationship between objects and answers.
2.1.4. Neural Networks
An artificial neural network (ANN), or simply a neural network, is a mathematical model, as well as its software or hardware implementations, built in a sense in the image and likeness of nerve cell networks of a living organism.
Neural networks are one of the most famous and oldest methods of machine learning. Like linear methods of classification and regression, essentially neural networks give an answer of the form:
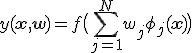
(1)
where
f — is the nonlinear activation function,
![]() — is the vector of weights,
— is the vector of weights,
![]() — are nonlinear basis functions.
— are nonlinear basis functions.
Neural network training consists in setting up weights as well as basic functions.
The first formal model of neural networks (NS) was the McCallock-Pitts model, refined and developed by Kleene. It was first established that NSs can perform any logical operations and generally any transformations implemented by discrete devices with finite memory. This model formed the basis of the theory of logical networks and finite automata and was actively used by psychologists and neurophysiologists in modeling some local processes of nervous activity. Due to its discreteness, it is quite consistent with the computer paradigm and, moreover, serves as its “neural foundation”.
Let there be n input quantities x1,..., xn of binary signs describing object x. The values of these signs will be interpreted as the magnitudes of the pulses arriving at the input of a neuron through n input synapses. We assume that, getting into the neuron, the pulses add up with the weights ω1,..., ωn.
If the weight is positive, then the corresponding synapse is exciting, if negative, then inhibitory. If the total impulse exceeds a predetermined activation threshold ω0, then the neuron is excited and outputs 1, otherwise 0 is generated.
So the neuron computes the n-ary Boolean function
![]()
(2)
where
![]() is the Heaviside step function.
is the Heaviside step function.
In the theory of neural networks, the function φ, which converts the value of the total pulse into the output value of the neuron, is usually called the activation function. Thus, the McCallock-Pitts model is equivalent to a threshold linear classifier.
Linear classifier — classification algorithm based on the construction of a linear dividing surface. In the case of two classes, the separating surface is a hyperplane, which divides the feature space into two half-spaces. In the case of a larger number of classes, the dividing surface is piecewise linear.
The theoretical foundations of neuromathematics were laid in the early 40s and in 1943 W. McCulloch and his student W. Pitts formulated the main provisions of the theory of brain activity.
They obtained the following results:
– a model of a neuron was developed as the simplest processor element that performs the calculation of the transition function of the scalar product of the vector of input signals and the vector of weight coefficients
– the design of a network of such elements for performing logical and arithmetic operations is proposed
– a fundamental assumption was made that such a network can learn, recognize images, generalize the information received.
The disadvantage of this model is the very model of the neuron “threshold” type of transition function. In the W. McCulloch-Pitts formalism, neurons have states 0, 1 and threshold logic of transition from state to state. Each neuron in the network determines a weighted sum of the states of all other neurons and compares it with a threshold to determine its own state.
The threshold form of the function does not provide the neural network with sufficient flexibility in training and tuning for a given task. If the value of the calculated scalar product, even slightly, does not reach the specified threshold, then the output signal is not formed at all and the neuron “does not work”. This means that the intensity of the output signal (axon) of a given neuron is lost and, therefore, a low-level value is formed at the weighted inputs in the next layer of neurons.
In addition, the model does not consider many features of the operation of real neurons (the pulsed nature of activity, nonlinearity of summation of input information, refractoriness).
Even though over the years, neuromathematics has gone far ahead, many of McCulock’s statements remain relevant to this day. With a wide variety of neuron models, the principle of their action, laid down by McCulloch and Pitts, remains unchanged.
2.1.5. Deep learning
Deep learning is machine learning algorithms for modeling high-level abstractions using numerous nonlinear transformations.
First, the following methods and their variations are related to deep learning:
– Certain training systems without a teacher, such as a limited Boltzmann machine for pre-training, an auto-encoder, a deep trust network, a generative adversarial network,
– Certain training systems with the teacher, such as the convolutional neural network, which brought to a new level the technology of pattern recognition,
– Recursive neural networks that allow learning on processes in time,
– Recursive neural networks to enable feedback between circuit elements and chains.
– By combining these methods, complex systems are created that correspond to various tasks of artificial intelligence.
Deep learning is an approved selection from a wide family of machine learning methods for presenting data that is most relevant to the nature of the task. An image, for example, can be represented in many ways, such as a vector of the intensity of values per pixel, or (in a more abstract form) as a set of primitives, areas of a certain shape, etc. Successful data representations make it easier to solve specific problems — for example, face recognition and facial expressions). In deep learning systems, it automates the process of selecting and setting attributes, conducting training of attributes without a teacher or with the partial involvement of a teacher, using efficient algorithms and hierarchical extraction of attributes for this.
Research in this area has improved models for working with large volumes of unmarked data. Some approaches have arisen as a result of advances in neuroscience, successes in interpreting information processing, building communication models in the nervous system, such as neural coding, associated with determining the relationship between stimulus and neural reactions and the relationship of electrical activity between neurons in the brain.
Deep learning systems have found application in areas such as computer vision, speech recognition, natural language processing, audio recognition, bioinformatics, where for several tasks significantly better results have been demonstrated than before. Despite the successes of using deep learning, it still has a fundamental limitation: deep learning models are limited in what they can represent, and most programs cannot be expressed as continuous geometric morphing of a data variety.
There remains, however, a skeptical view that deep learning is nothing but a buzzword or rebranding for neural networks.
Deep learning is characterized as a class of machine learning algorithms, which:
– uses a multilayer system of nonlinear filters to extract features with transformations. Each subsequent layer receives the output of the previous layer at the input. A deep learning system can combine learning algorithms with a teacher and without a teacher, while the analysis of the sample is training without a teacher, and the classification is training with a teacher.
– It has several layers for identifying signs or parameters of data presentation (training without a teacher). Moreover, the attributes are organized hierarchically, the attributes of a higher level are derived from the attributes of a lower level.
– is part of a broader field of machine learning for the study of data representations.
– forms in the learning process layers at several levels of representations that correspond to different levels of abstraction; layers form a hierarchy of concepts.
– the presence of several layers of nonlinear processing
– learning with or without a teacher attributes of each layer, forming a hierarchy from low to high level.
The composition of specific nonlinear layers depends on the problem being solved. Both hidden layers of the neural network and layers of complex logical transformations are used. The system may include hidden variables organized in layers in deep generative models, such as nodes in a deep trust network and a deep restricted Boltzmann machine.
Deep learning algorithms are contrasted with shallow learning algorithms in terms of the number of parameterized transformations encountered by a signal propagating from the input layer to the output layer, where a data processing unit that has learning parameters such as weights or thresholds is considered to be a parameterized transform. The chain of transformations from input to output is called CAP — through the transfer of responsibility (English credit assignment path, CAP). CAPs describe potential causal links along the network from input to output, and the path in different branches may have different lengths. For a feedforward neural network, the CAP depth does not differ from the network depth and is equal to the number of hidden layers plus one (the output layer is also parameterized). For recurrent neural networks, in which a signal can jump through layers without passing through intermediate ones, CAP due to feedback is potentially unlimited in length. There is no universally agreed threshold for the depth of division of shallow learning from deep learning, but it is generally believed that deep learning is characterized by several non-linear layers (CAP> 2). Jörgen Schmidhuber also highlights “very deep learning” when CAP> 10.
3. Conclusion
There are still many drawbacks to the pix2code project and other similar projects. The code that is generated strictly within the framework of one UI library. The styles of the elements are not precisely defined. The text is not displayed correctly. But the most important drawback is the lack of training data. On the Internet, you can parse any sites as an example, but they all have an interface differently made and it is not a fact that many of them are done correctly. If these shortcomings are corrected, then there remains only the issue of processor power.
References:
- Lacan, Jacques, Fink, Heloíse and Fink, Bruce. Ecrits: the first complete edition in English. New York: W. W. Norton & Co, 2004.
- Goertzel, Ben and Pennachin, Cassio. Gödel Machines: Fully Self-referential Optimal Universal Self-improvers. Artificial general intelligence. Berlin: Springer, 2007. Print.
- Hofstadter, Douglas R. Gödel, Escher, Bach: an eternal golden braid. New York: Basic Books, 1999. Oviduct. Translation by A. D. Melville. Introduction by E. J. Kenney. Metamorphoses. Oxford: Oxford University Press, 2008.
- Deleuze, Gilles. Logik des Sinns. Frankfurt am Main: Suhrkamp, 1993.
- Noë, Alva. Action in perception. Cambridge, Mass: MIT Press, 2004.
- Kesha Patel, Ushma, Patel, Purvag, Hexmoor, Henry and Carver, Norman. Improving behavior of computer game bots using fictitious play. International Journal of Automation and Computing, Springer Verlag NY, USA, April 2012. McDonald, Kyle. FaceOSC. Open source for face tracking and recognition.
