





В статье описан алгоритм устранения дубликатов записей в базе данных при наличии нескольких источников информации и ошибок операторского ввода. Предложен алгоритм вычисления функции релевантности на основании метода N-gram.
Ключевые слова
Нечеткий поиск; N-gram; релевантность строк; поиск данных; приблизительное сравнения строк; порог идентификации; база данных; код Хаффмана; сжатие данных без потерь; код переменной длины; Теория информации; префиксный код.
Author described the algorithm of duplicate records elimination under condition of several data sources and errors of operator input. The algorithm based on relevance function using N-grame method.
Keyword
Fuzzy search; N-gram; string relevance; data search; approximate string matching; identification limit; database; Huffman coding; lossless data compression; variable-length code; Information theory; prefix code.
Администратор баз данных рано или поздно сталкивается с проблемой управления качеством данных, то есть необходимостью приведения информации к состоянию, которое удовлетворяет требованиям по критериям достоверности, актуальности, логической полноты и непротиворечивости.
Для выполнения всех перечисленных требований понадобится целый комплекс мер, одной из составляющих которого будет обеспечение отсутствия дубликатов.
В любой базе данных можно выделить два основных типа дублирования информации:
имеющая жестко заданную структуру (формат) содержания;
слабоструктурированная, не имеющая жестко заданной структуры содержания.
В первом случае речь идет о различных кодах из различных справочников и классификаторов, идентификаторах сущностей, используемых в качестве ключевых атрибутов поиска. Во втором случае рассматривается вариант работы с разнообразными именами собственными, используемыми для идентификации людей: фамилий, имен, отчеств; адресов; наименований государственных учреждений; организаций и т. д.
Проблема дублирования жестко структурированных атрибутов решается ограничением на ввод данных в соответствующие поля. Поиск дубликатов в этом случае ведется по точному совпадению и не вызывает сложностей.
Ситуация со слабоструктурированными полями несколько сложнее, так как нет возможности использовать ограничения формата, а также нельзя применять словари-справочники, поскольку их требуемый объем может выйти за допустимые пределы и многократно превысить объем основной информации базы данных.
Для устранения ошибок операторского ввода и проверки дублирования слабоструктурированной информации предложен алгоритм нечеткого поиска, позволяющий находить дубликаты на основании неполного совпадения и оценки их релевантности – количественного критерия схожести.
Следует учитывать, что данный алгоритм не дают 100% гарантии от ошибок, то есть сохраняется вероятность того, что будут пропущены дублирующие данные или данные будут распознаны как дубликаты, не являясь таковыми. Поэтому для принятия окончательного решения необходимо участие человека.
Словарная n-граммная индексация основана на следующем свойстве: если слово u получается из слова w в результате не более чем k элементарных операций редактирования (за исключением перестановок символов), то при любом представлении u в виде конкатенации из k+1-ой строки, одна из строк такого представления будет точной подстрокой w. Это свойство можно усилить, заметив, что среди подстрок представления существует такая, что разность между её позицией в строках w и u не больше k. Таким образом, задача поиска сводится к задаче выборки всех слов, содержащих заданную подстроку.
Функция сравнения подстрок
Функция нечёткого сравнения использует в качестве аргументов две строки и параметр сравнения – максимальную длину сравниваемых подстрок. Подстроки содержат буквы кириллического алфавита и пробел. Результатом работы функции является число, лежащее в пределах от 0 до 1, где 0 соответствует полному несовпадению двух строк, а 1 - полной их идентичности. Сравнение строк происходит по следующей схеме: функция сравнения составляет все возможные комбинации подстрок с длиной вплоть до указанной и подсчитывает их совпадения. Количество совпадений, разделённое на число вариантов, объявляется коэффициентом схожести строк для фиксированного N и выдаётся в качестве результата работы функции, далее берется среднее значение для всех коэффициентом. Формула релевантности будет выглядеть следующем образом:
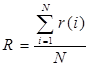 (1), где
(1), где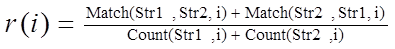 (2),
(2),
Count(Str,i) = (len(Str) - i + 1); len(S) - длина строки S; Match(S1, S2 , i) = сумма совпадений всех подстрок длиной i из S1 в строке S2.
Пусть, например, в качестве аргументов заданы две строки «Привет» и «Превед» и некоторая максимальная длина подстрок, скажем, 4, тогда получаем значения коэффициента, равные 0,75, при n=1; 0,4 при n=2; 0 при n=3 и n=4.
Таким образом, общая релевантность двух строк: R=(0,75+0,4+0+0)/4=0,2875=28,75%
Увеличение длины максимальной подстроки приводит к увеличению времени работы функции. С другой стороны, поиск становится более чётким.
Устранение дубликатов
Общий принцип применения функции для поиска дубликатов следующий:
1. Производится вычисление релевантности.
2. Данный показатель приводится к относительной шкале соответствия в интервале от 0 до 1 (0 – полное несовпадение, 1 – полное совпадение).
3. Экспериментальным путем для тестового массива данных определяется нижний порог автоматической обработки (Па), за которым количество ошибок распознавания дубликатов становится неприемлемым и нижний порог ручной обработки (Пр), за которым поиск выдает практически одни ошибки.
4. Па может быть использован для дальнейшей уточняющей обработки дубликатов в автоматическом режиме, оставляя найденные элементы со значениями соответствия ниже Па, но выше Пр для обработки человеком.
Основными способами внесения и изменения информации в базу данных являются:
· непосредственный ввод пользователями;
· импорт данных из внешних источников
Так как система распознавания не может предоставить 100% точность, пользователь должен также иметь возможность игнорировать подсказку системы и ввести данные. При таких условиях в базу данных неизбежно будет попадать часть некачественной информации, которая должна быть обнаружена в дальнейшем. Таким образом, задачу выявления и устранения дубликатов можно разбить на три этапа:
1.Выявление дубликатов на уровне ввода информации и их отклонение.
2.Выявление дубликатов путем сравнения и анализа уже введенных данных в соответствии с заданным Па
3.Автоматическое удаление дублирующей информации.
4.Анализ и обработка человеком результатов п.2, которые не могут быть обработаны автоматически (показатель соответствия ниже Па, но выше Пр).
Алгоритм работы блока представлен на рисунке 1.
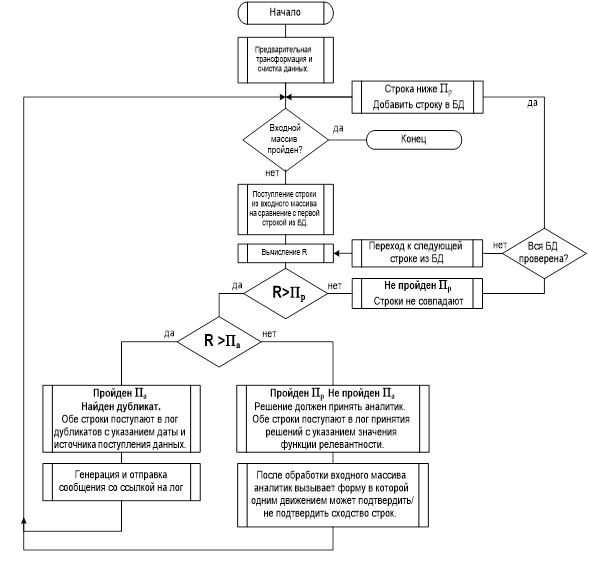
Рис 1. Алгоритм проверки на дубликаты
Заключение
Полученные в ходе тестирования алгоритма результаты позволяют сделать следующие выводы:
1. Предложенную функцию релевантности целесообразно использовать в условиях больших объемов данных.
2. Характерной особенностью всех полученных результатов является относительная стабильность в точности.
3. Устойчивость в точности дает возможность создания различных модификаций алгоритма с целью увеличения логической полноты.
Для дальнейших исследований представляет интерес проведение тестирования, с включением в алфавит спецсимволов. В рамках данного тестирования необходимо провести сравнительный анализ эффективности нахождения дубликатов по одной и по нескольким базам данных. Кроме того, становится актуальной задача создания тестовой коллекции, содержащей наборы «идеальных» пар дубликатов по отдельным полям, что позволит проводить исследования эффективности алгоритмов по различным критериям.
Литература:
1. Web site of the Computer science department of Maryland University. Research on N-Grams in Information Retrieval. http://www.cs.umbc.edu/ngram/
2. А.В. Левитин. Алгоритмы: введение в разработку и анализ . «Вильямс», 2006. С. 392-398.
3. H. Shang, T.H. Merret. Tries for Approximate String Matching. In IEEE Transactions on Knowledge and Data Engineering, volume 8(4), pages 540 – 547, 1996.
4. E. Ukkonen. Algorithms for approximate string matching. In Information and Control, volume (64), pages 100-118, 1985.
5. E. Ukkonen. Finding approximate patterns in strings, O(k * n) time. In Journal of Algorithms volume 6, pages 132-137, 1985.
6. E. Ukkonen. Approximate String Matching with q- Grams and maximal matches. In Theoretical Computer Science, volume 92(1), pages 191-211, 1992.
