





Алгоритм обработки аудиозаписи для определения дубликата.
Алгоритм основан на вычислении отпечатков (fingerprints) аудиозаписей для дальнейшего их анализа, то есть представлении аудиосигнала в виде набора значений, описывающих его физические свойства.
Отпечаток содержит в себе некую информацию об аудиозаписи, причем объем этой информации сильно меньше, чем у исходного файла. Одинаковые аудиозаписи будут иметь одинаковые отпечатки, у отличных по звучанию песен отпечатки не будут совпадать.
Для вычисления акустического отпечатка нужно начать с декодирования аудиосигнала, который упакован в аудиофайл. Как правило аудиофайл (например, в формате MP3) представляет собой цепочку фреймов (блоков), в которых содержатся закодированные данные об аудио. Для декодирования файла можно использовать, например, библиотеку с открытым исходным кодом FFmpeg. В результате декодирования получается массив значений, описывающих изменение амплитуды сигнала по времени.
Далее необходимо определить спектрограмму полученного декодированного сигнала. Проще всего использовать алгоритм быстрого преобразования Фурье (FFT), исходный код алгоритма можно легко найти в сети Интернет, а некоторые его реализации включены в пакеты наподобие Matlab.
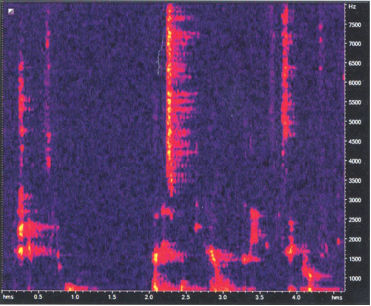
Рис. 1. Пример спектрограммы аудиосигнала
В спектрограмме ось абсцисс представляет время сигнала, по оси ординат отложена частота сигнала в определенный момент времени, а цвет определяет интенсивность данной частоты в данный момент времени, то есть амплитуду.
Многолетняя практика показала, что частота наиболее хорошо характеризует аудиозапись, поэтому именно частоту возьмем за основу вычисления отпечатка. Для этого разобьем всю временную область на несколько частей длиной dt, то есть всего получаем ![]() частей. В каждом таком промежутке будем вычислять n пиков амплитуды, каждый пик будем характеризовать временем и частотой. Далее отсортируем пики по времени и добавим в один список длины n. Таким образом, получим
частей. В каждом таком промежутке будем вычислять n пиков амплитуды, каждый пик будем характеризовать временем и частотой. Далее отсортируем пики по времени и добавим в один список длины n. Таким образом, получим ![]() списков, которые объединим в один массив длины
списков, которые объединим в один массив длины ![]() . Этот массив и будет нашим отпечатком аудиозаписи.
. Этот массив и будет нашим отпечатком аудиозаписи.

Рис. 2. Выделение пиков на спектрограмме
Для оценки схожести аудиозаписей необходимо определять длину общей подпоследовательности их отпечатков. Сдвигая поэлементно отпечатки относительно друг друга будет видно, что в некоторый момент будет всплеск числа совпадающих элементов. Это означает, что части аудиозаписей совпадают. Для различных же аудиозаписей такого всплеска наблюдаться не будет. Сдвиг отпечатков нужен, например, для того, чтобы учесть тишину в начале трека или в конце.
Улучшение устойчивости алгоритма.
Для нахождения отпечатков аудиозаписи был проведен анализ основных частот сигнала в определенный момент времени. В большинстве случаев точного совпадения частот наблюдаться не будет, но они будут близки друг к другу. То есть необходимо разработать алгоритм поиска найденных пиков с некоторым допуском, или, иначе, искать K ближайших соседей (K-means) к данной частоте с некоторой максимальной разницей.
Для этого введем пространство метрик. Метрикой в данном случае будем считать модуль разницы между двумя частотами. Такая функция удовлетворяет всем свойствам метрики:
![]() (аксиома тождества)
(аксиома тождества)
![]() (аксиома симметрии)
(аксиома симметрии)
![]() (аксиома треугольника)
(аксиома треугольника)
Для хранения значений и поиска воспользуемся такой структурой данных как VP-дерево (vantage-point tree). Из первоначального множества берется одна из точек («опорная точка») и выбирается «радиус» R для этой точки. Остальные точки делятся на два подмножества — с расстоянием меньше R до опорной точки, и расстоянием больше R. В каждом из получившихся подмножеств выбирается следующая опорная точка и новый радиус, и т. д., пока количество элементов в каждом из оставшихся подмножеств не станет меньше определенного порогового значения. Опорные точки и «радиусы» сфер разбиения выбираются так, чтобы дерево получилось максимально сбалансированным [1].
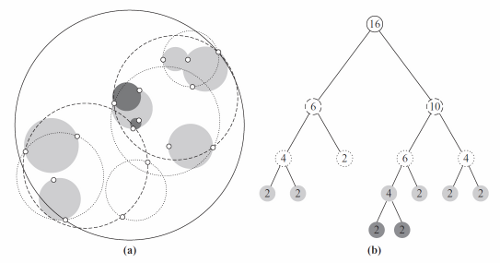
Рис. 3. Графическое изображение VP дерева
Применение VP дерева позволяет находить ближайшие точки взамен нахождения полного совпадения, что дает преимущество в анализе зашумленных или искаженных аудиозаписей. Однако для этого пришлось пожертвовать скоростью. Сложность поиска в VP дереве — ![]() .
.
Кластеризация ишардирование базы ввиде VP дерева.
Постараемся оценить размер базы данных. Разобьем все аудиозаписи на отрывки равной длины и возьмем из каждого n измерений. Для конкретики возьмем длину промежутка в 1 секунду, а количество измерений 30. Для средней аудиозаписи длины 4 минуты получим 7200 значений частот. Для базы в миллион аудиозаписей это число достигает 7 200 000 000 измерений, что соответствует 230 гигабайтам при размере одного значения 32 бита. Для ускорения поиска желательно хранить базу данных в оперативной памяти сервера, но при таких объемах это становится проблематично, кроме того, для поиска будут задействоваться все ресурсы машины. Поэтому необходимо разработать механизмы кластеризации и шардирования данных. Шардирование — разделение (партиционирование) базы данных на отдельные части (шарды) так, чтобы каждую из них можно было вынести на отдельный сервер для увеличения производительности системы.
Вернемся к структуре VP дерева. Это бинарное дерево, каждый его узел имеет 2 потомка. Нарушим условие сбалансированности дерева. Выберем радиус таким образом, что левое поддерево всегда меньше правого. Кластеризовать шарды будем по принципу VP-дерева. Каждый шард хранит в себе левое поддерево, а правое поддерево — ссылка на следующий шард. “Листовой” сервер хранит и левое и правое поддерево в себе.
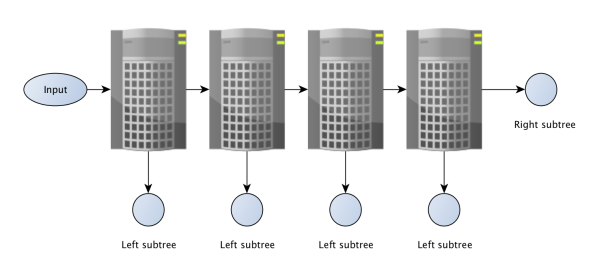
Рис. 4. Схема шардирования
Легко заметить, что каждый следующий шард кроме последнего, содержит в себе меньше данных, чем предыдущий. Так, для отношения размера левого поддерева к правому как один к трем, первый шард содержит ![]() данных, второй
данных, второй ![]() , третий
, третий ![]() и так далее. Для выравнивания нагрузки выберем различное число реплик в соответствии с отношением данных в каждом шарде.
и так далее. Для выравнивания нагрузки выберем различное число реплик в соответствии с отношением данных в каждом шарде.
Второй подход — в каждом шарде динамически вычислять отношение размеров левого и правого поддерева. Так, для первого отношение будет 1 к 3, для второго — 1 к 2 и так далее. Это позволит хранить на каждом сервере одинаковый объем данных, что даст возможность равномерного реплицирования.
Ускорение обработки аудиозаписи.
Рассмотрим процесс загрузки аудиозаписи с сети и последующего ее анализа:
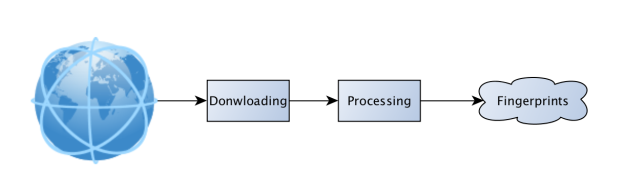
Рис. 5. Схема последовательной загрузки и обработки
В такой схеме общее время работы с аудиозаписью складывается из времени загрузки и времени обработки. Однако вернемся к алгоритму вычисления отпечатка. Аудиозапись анализируется последовательно, выделяются некоторые кванты времени и далее обрабатываются. То есть для вычисления очередного кванта не нужно наличие всей аудиозаписи. Постараемся сделать процесс загрузки и обработки параллельным. При загрузке и декодировании очередного кванта сразу отправляем его на обработку. В то время как обрабатывается первый отрезок, следующий уже успевает загрузиться и отправляется на обработку сразу после окончания загрузки. Это позволяет сократить общее время вычисления отпечатка до времени загрузки и времени обработки одного кванта. Кроме того, в предположении, что сеть работает в n раз медленнее вычисления отпечатка, без дополнительных затрат можно обрабатывать параллельно n аудиозаписей.

Рис 6 Схема параллельной обработки при условии отношения времени обработки к времени загрузки 1 к 2
Заключение.
Изложенные методы позволяют увеличить устойчивость алгоритма поиска дубликатов аудиозаписей к различным искажениям. Кроме того, схема шардирования в виде VP дерева позволяет построить устойчивую к высоким нагрузкам систему вычисления акустических отпечатков. Все это было использовано при разработке системы антиплагиата в веб-приложении, на которое был получен грант в Фонде содействия развитию малых форм предприятий в научно-технической сфере.
Литература:
- VP-дерево // Википедия. URL: https://ru.wikipedia.org/wiki/VP-дерево.
- Архитектура и алгоритмы индексации аудиозаписей ВКонтакте // Хабрахабр. URL: https://habrahabr.ru/company/vkontakte/blog/330988/.
