Для успешного управления сервисом, написанным на платформе Node.js, зачастую важно понимать и быстро находить “узкие”, с точки производительности, места в исходном коде продукта, а также, следить за стабильностью приложения и вовремя реагировать на внештатные ситуации.
Как многим известно, Node.js это платформа асинхронного выполнения кода. [1] Практически ни одно действие не обходится без взаимодействия с Event Loop. Event Loop (Цикл событий) — это то, что позволяет Node.js выполнять неблокирующие операции ввода/вывода (несмотря на то, что JavaScript является однопоточным языком программирования) путем выгрузки операций в ядро системы, когда это возможно. На Рис. 1 представлена схема взаимодействия внутренних компонент платформы Node.js. Чем меньше время задержки Event Loop тем фактически быстрее работает программа. Исходя из вышесказанного, одной из наиболее важных метрик для мониторинга будет Event Loop Lag (время задержки Event Loop).
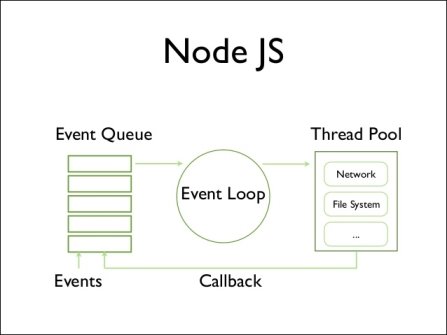
Рис. 1. Схема взаимодействия внутренних компонент Node.js
Разумеется, существуют и другие (более общие) метрики процессов, выполняющихся под контролем операционной системы. В данной статье мы рассмотрим процесс сбора и мониторинга следующих метрик:
- Uptime — время жизни Node.js процесса;
- CPU Usage, user — время, в течение которого процессор занят выполнением кода в пользовательском пространстве;
- CPU Usage, system — время, затрачиваемое процессором на функции операционной системы, связанные с Node.js процессом;
- Memory Usage, rss — часть занимаемой процессом памяти, которая хранится в основной памяти (ОЗУ);
- Memory Usage, heap total — общий размер сегмента памяти, предназначенного для хранения ссылочных типов, таких как объекты, строки и замыкания;
- Memory Usage, heap used — размер занятой памяти. Более подробно, области памяти процесса показаны на Рис. 2;
- Memory Usage, external — использование памяти объектов C++, привязанных к объектам JavaScript, управляемым V8.
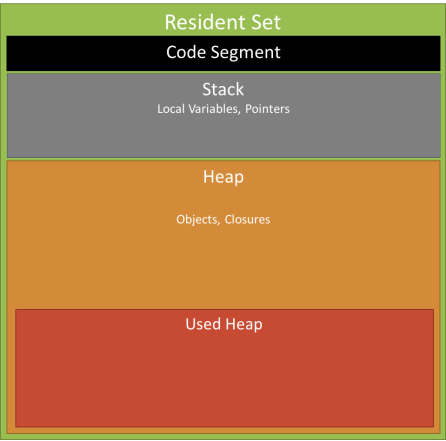
Рис. 2. Области памяти Node.js процесса
Мы будем использовать специальную библиотеку на Node.js, которая позволяет собрать все важный нам метрики в JSON формате, как показано на Рис. 3.

Рис. 3. Собираемые метрики в формате JSON
Для анализа собираемых данных чаще всего используются специальные системы мониторинга. Одной из таких систем является Zabbix. [3] Он предназначен для мониторинга и отслеживания состояния различных сетевых сервисов, серверов и другого сетевого оборудования. Данные будут отправляться при помощи специальной утилиты — nodejs-zabbix-sender. Рассмотрим процесс отправки данных (Рис. 4). Мы будем отправлять актуальные данные процесса каждую минуту.
Для того чтобы Zabbix сервер начал принимать данные от нашего приложения, в интерфейсе мы должны создать хост, и заполнить свойства для хранения наших метрик. Для каждой из метрик мы можем сконфигурировать время хранения значения, тренда и единицы измерения метрики.
В случае если данные метрик памяти приходят в Байтах, а мы хотим отображать их на графиках в Мегабайтах, можно выполнять обработку входящих данных согласно правилам.

Рис. 4. Фрагмент исходного кода для отправки данных на Zabbix сервер
Такая информация, как время жизни процесса, позволит Zabbix серверу понять когда процесс был перезапущен (например в случае критического сбоя) и сообщить об этом администратору системы.
На обнаружение проблем, характерных для системы, могут быть настроены разные обработчики (триггеры). При срабатывании триггера создается “проблема” и информация о ней незамедлительно становится доступной в Zabbix. Для каждого триггера, возможно указать специальное условие, при котором проблема считается более не актуальной. Именно это позволяет с высокой точностью детектировать момент решения проблемы, и избегать ложных срабатываний.
Помимо сбора информации о Node.js приложении, можно установить и настроить Zabbix Agent, который по умолчанию умеет собирать множество метрик об операционной системе в целом. Включая использование памяти, процессора, и время задержки операций ввода-вывода.
Для удобства просмотра общего состояния существуют специальные отчеты, в которых указываются время и длительность проблемы, см. Рис. 5. А так же, список ресурсов которые затронуты и находятся в режиме ограниченного функционирования.
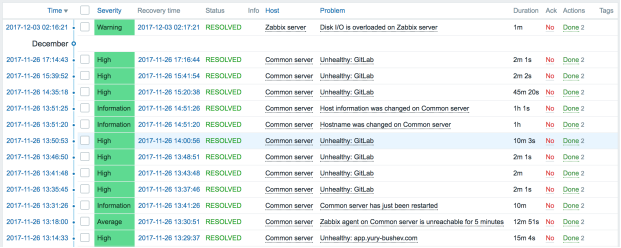
Рис. 5. Сводный отчет о последних проблемах в система мониторинга Zabbix
В системах и проектах, где количество Node.js приложений может достигать нескольких десятков, а то и сотен штук, просто необходима централизованная система сбора метрик и мониторинга в целом. Она позволяет незамедлительно обнаруживать проблемы в программном обеспечение, и решать вопросы масштабирования и доступности сервисов.
Литература:
- Node.js. // About Node.js®. URL: https://nodejs.org/en/about/ (дата обращения: 06.12.2017).
- Event Loop. // The Node.js Event Loop, Timers, and process.nextTick() URL: https://nodejs.org/en/docs/guides/event-loop-timers-and-nexttick/ (дата обращения: 02.11.2017)
- Zabbix. // Product Overview. URL: https://www.zabbix.com/product (дата обращения: 23.11.2017)

