В статье произведен обзор возможностей программной среды RapidMiner для интеллектуального анализа данных. А также сравнительный анализ инструментов для аналитической обработки данных. Сделаны выводы относительно применения в академических целях.
Ключевые слова: интеллектуальный анализ данных; RapidMiner.
Программная платформа RapidMiner для интеллектуального анализа данных
RapidMiner, ранее известный как YALE (Yet Another Learning Environment), является программной платформой, которая обеспечивает интегрированную среду для машинного обучения, интеллектуального анализа данных, анализа текста, прогностической аналитики и бизнес-аналитики. Эта среда используется для деловых и промышленных приложений, а также для научных исследований, образования, профессиональной подготовки, быстрого прототипирования и разработки приложений и поддерживает все этапы процесса добычи данных, включая результаты визуализации, проверки и оптимизации. RapidMiner является системой с открытым программным кодом, система написана на языке Java и в настоящее время распространяется по лицензии GNU Affero General Public License. В зависимости от конфигурации системы имеются свободно распространяемые и коммерческие лицензии (рис.1).
Функции, реализованные в RapidMiner, позволяют работать с операторами системы WEKA, выполнять предобработку данных, фильтровать признаки, оценивать качество. Так же есть встроенный язык сценариев, который позволяет выполнять большие серии экспериментов. Достоинствами системы являются визуализация процесса анализа данных и представления результатов, так же возможна загрузка и сохранение данных в специальных форматах (arff, C4.5, csv, bibtex, базы данных и т.д.).
Возможности среды RapidMiner
Все задачи, связанные с хранением данных, моделей и результатов анализа, в RapidMiner решаются при помощи единого репозитория. Репозиторий — это хранилище данных, создаваемое на диске средой и содержащее в себе все данные и процессы. Использование репозитория дает пользователю целый ряд преимуществ:
данные, процессы, результаты и отчеты размещены и упорядочены;
Рис. 1. Конфигурации RapidMiner (https://rapidminer.com/products/comparison/#)
открытие или загрузка файлов не требует дальнейшей настройки;
входные, выходные данные, промежуточные результаты сопровождаются метаинформацией, обеспечивая связность и целостность данных и облегчая разработку процесса на начальном этапе;
репозиторий может размещаться на кластерной файловой системе или на удаленном сервере RapidMiner (RapidAnalytics).
На рис.2 приведены элементы интерфейса RapidMiner. Основным рабочим элементом в среде RapidMiner является процесс. В основе успешной работы лежит правильный выбор и настройка отдельных компонентов процесса, которые в RapidMiner называются операторами. Операторы, доступные в среде, расположены во вкладке Operators и разбиты на группы в зависимости от назначения:
контроль процесса (process control) включает в себя операторы для выбора оптимального числа параметров, создания и управления подпроцессами и группами объектов, сохранения и извлечения состояния процесса, обработки исключений, цикла;
утилиты (utility) для использования макросов и журналов действий, работы с файлами, генерации наборов данных, добавления аннотации и другие;
доступ к хранилищу данных (Repository Access) чтение, сохранение, перемещение, копирование, переименование хранилищ данных;
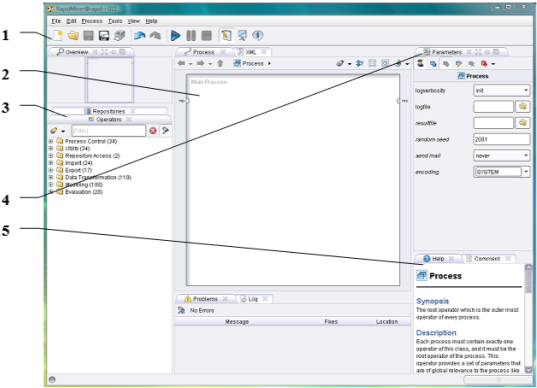
Рис. 2. Элементы интерфейса RapidMiner (1.Панель быстрого доступа; 2.Вкладка Process;3. Вкладки Repositories и Operators; 4. Вкладка Parameters; 5. Вкладка Help)
импорт (Import) чтение данных из различных форматов хранения (CSV, Excel, XML, SAS, Access, AML, ARFF, XRFF, Database, SPSS, Stata, Sparse, dBase, C4.5, BibTeX, DasyLab, URL), моделей, атрибутов, параметров, методов и результатов;
экспорт (Export) запись и обновление данных в различные форматы хранения (CSV, Excel, Access, ARFF, XRFF, Database и специальный формат), моделей, атрибутов, параметров, методов и результатов;
преобразование данных (Data Transformation): переименование и модификация ролей, преобразование типа данных, преобразование атрибутов, изменение значений, очистка данных, фильтрация, сортировка, агрегация данных, операции над множествами данных (объединение, пересечение и др.);
оценка обработки данных (Evaluation) измерение производительности, значимости, точности вычислений;
модели (Modeling), реализованные с использованием алгоритмов:
1) классификации и регрессии (модель по требованию, байесовская, в виде дерева, логическая и др.),
2) взвешивания атрибутов,
3) кластеризации и сегментации (модель k-Means и ее модификации, разбиения по плотности на основе пространственной кластеризации, максимизации математического ожидания, случайного разбиения, кластеризации сверху вниз, агломеративной кластеризации и др.),
4) ассоциации,
5) корреляции и вычисления зависимостей,
6) сходства вычислений.
Операторы имеют входы и выходы, называемые портами, через которые они связываются друг с другом и с рабочей областью процесса. Параметры каждого оператора настраиваются во вкладке Parameters.
Во вкладке Process размещена рабочая область среды, в которой происходит построение модели обработки данных. Вкладки Problems и Log помогают пользователю обнаружить и исправить ошибки, возникающие в ходе работы.
После запуска процесса и в случае его успешного окончания RapidMiner направляет пользователя в режим просмотра результатов. Выбрав соответствующую опцию на вкладке ExampleSet, можно различным образом изучить набор выходных данных, полученных в результате выполнения процесса, установить связи или закономерности между атрибутами. Раздел Data View представляет собой таблицу, содержащую значения всех атрибутов каждого экземпляра данных, количество этих экземпляров, информацию о количестве атрибутов с разной ролью. Раздел Plot View позволяет, используя графические средства RapidMiner, увидеть визуальное изображение данных в среде.
В системе RapidMiner реализовано огромное число различных способов визуализации данных. Способ визуализации выбирается в разделе Plot View кнопкой Plotter. Перечислим некоторые виды визуализации, реализованные в системе:
Scatter –2-х и 3-х мерные проекции точек;
Bubble — каждый объект изображается кругом, радиус которого соответствует значению одного из признаков;
Parallels — каждый объект изображается линией, которая проходит через точки, соответствующие значениям признаков,
Series — изображение рядов;
SOM — карты Кохонена;
Block — объекты изображаются прямоугольниками;
Density — изображение плотности;
Pie, Ring — секторные диаграммы типа «пирог».
Сравнительный анализ инструментов для аналитической обработки данных
Сравнительный анализ инструментов для аналитической обработки данных приведен в таблице 1.
Таблица 1
Сравнение инструментов для обработки данных
|
Предметы сравнения |
WEKA |
RapidMiner |
MATLAB |
|
Обработка больших объёмов данных |
+ |
+ |
- |
|
Обучение с учителем |
+ |
+ |
- |
|
Обучение без учителя |
+ |
+ |
+ |
|
Работа с локальными файлами |
- |
+ |
+ |
|
Наличие собственного скриптового языка |
- |
+ |
+ |
|
Визуализация процесса |
- |
+ |
- |
|
Справочная система |
- |
+ |
+ |
|
Интеграция с приложениями |
JAVA |
JAVA |
JAVA и C++ |
|
Лицензия и распространение |
GNU GPL бесплатно |
GNUAGPL Версии 5.3 — бесплатно; Версии выше 6.0 платная или пробная версия 30 дней |
The MathWorks, Inc. Пробная версия по запросу для студентов |
RapidMiner и Weka хорошо подходят для академических целей. Преимуществом RapidMiner является визуализация процесса анализа данных, которая помогает лучше ознакомиться с его задачами и этапами.
Литература:
- F. Akthar, C. Hahne, RapidMiner 5 Operator Reference, by Rapid-I GmbH, 2012, URL: https://rapidminer.com/wp-content/uploads/2013/10/RapidMiner_OperatorReference_en.pdf
- RapidMiner Studio Manual by RapidMiner, 2014, URL: https://rapidminer.com/wp-content/uploads/2014/10/RapidMiner-v6-user-manual.pdf
- Дьяконов А.Г. Анализ данных, обучение по прецедентам, логические игры, системы WEKA, RapidMiner и MatLab. МГУ, 2010, стр. 278
- Электронный ресурс университета Вайкато, URL: http://www.cs.waikato.ac.nz/ml/weka/

