





Современное развитие информационных технологий и глобальная сеть предоставило пользователям доступ к огромным массивам информации. Появилось большое число offline и online-библиотек, предоставляющих возможность читать книги, новости и газеты непосредственно с компьютера и с других девайсах.
Так же в сети стало доступно множество методических указаний, обучающих курсов лекций, учебников и т. д. Кроме того, появились огромные коллекции рефератов, готовых курсовых и дипломных проектов. Если раньше для написания реферата или какой-либо работы необходимо было найти в книгах нужный материал и переписать его, то теперь достаточно ввести название нужной темы в любой поисковик и получить нужный материал. Стало распространяться метод написания работ под названием «CopyandPaste» (простое копирование информации из одного или нескольких источников).
В то же время, развитие информационных технологий, наряду с безусловными положительными для общества аспектами, повлияло на развитие проблем в таких областях, как защита авторских прав, интеллектуальной собственности, сохранение конфиденциальности информации и другие. Перед преподавателями возникла задача проверки работ студентов на предмет заимствований из Интернет-ресурсов, то есть на наличие плагиата.
Рассмотрим понятие плагиата. Согласно словарю иностранных слов, Плагиат — умышленное присвоение авторства чужого произведения искусства или достижения науки, технических решений или изобретений. Плагиат может быть нарушением авторско-правового законодательства и патентного законодательства и в качестве таковых может повлечь за собой юридическую ответственность.
Плагиат может осуществляться следующим образом:
- полное или частичное копирование текста из одного источника;
- копирование и компоновка текста из нескольких источников;
- копирование текста из другого источника и изменение порядка следования частей текста [1].
Как осуществляется проверка текста на плагиат?
Данная процедура подразумевает анализ контента по критерию уникальности. В сущности, у предлагаемых в Интернете программ либо онлайн-сервисов, осуществляющих проверку текста по вышеуказанному критерию, один принцип действия.
Вначале происходит разбивка текста на отдельные части, состоящие из нескольких слов. Далее данные куски текста направляются в различные поисковые системы, в виде определенных запросов. Затем приходит ответ о найденном или ненайденном совпадении. Информация может быть представлена в процентном отношении по каждому сайту. Таким образом, если присутствовал плагиат, то программы или онлайн-сервисы обязательно покажут это. Они все являются своего рода индикаторами заимствований.
Основные способы, процедуры анализа
Вот где и как появился контент-анализ. Как метод исследования он включает в себя сразу несколько основных процедур, которые мы сейчас и рассмотрим.
- Во-первых, нужно выявить смысловые единицы анализируемого контента, в роли которых могут выступать:
- Некие термины, являющиеся смысловыми понятиями, используемыми в отдельных научных отраслях.
- Темы, причем не только всего текста или выступления в целом, но и те, которые подразумеваются разными смысловыми абзацами или фрагментами речи выступающего.
- Особенно важны имена и фамилии людей, которые встречаются в данном материале.
- Анализу следует подвергать все упоминаемые события и факты.
- Если у речи или документа есть потенциальные оппоненты, то нужно разобраться и со смысловыми реляциями, которые на них направлены.
Нужно заметить, что единицы обязательно должны выделяться в контексте содержания, а также задач и целей, которые преследует данная публикация. Конечно же, всегда нужно учитывать еще и те научные гипотезы, которые были использованы (если они были) при ее создании.
- Во-вторых, выделяются единицы счета. Они могут как совпасть, так и не совпасть с элементами анализа, о которых мы только что говорили. Если совпадают, то исследователю остается банально определить частоту появления каждого термина (или аналогичного понятия) в тексте. Во втором же случае ему самому, на основе тематики какого-то произведения и собственного здравого смысла, предстоит выделить эти самые единицы, которыми могут являться:
- Общая протяженность написанного текста или произнесенной речи.
- Площадь произведения, где в большей концентрации имеются смысловые единицы.
- Общее количество печатных знаков или же абзацев.
- Если речь идет о публичном выступлении, видеозаписи или аудиофайле, то определяется общее их время.
- При анализе старых кинохроник можно принять во внимание также общий метраж использованной пленки.
- Наконец, при изучении старинных гравюр или аналогичных произведений всегда нужно определять общее количество рисунков, которые связаны определенным содержанием.
- Затем исследователи занимаются простым подсчетом, технология которого схожа с теми методами, которые используются для любой классификации понятий или явлений. Составляются математические модели и диаграммы, по специально разработанным формулам выводится "общая понятность текста" и аналогичные данные, которые могут помочь в дальнейших исследованиях.
Процедура подсчета
Чтобы лучше понять, о чем до сей поры вообще шла речь, необходимо рассказать о самой методике. Подсчет ведется посредством так называемого коэффициента Яниса [2].
Вот он:
![]()
где:
![]() – значение коэффициента.
– значение коэффициента.
![]() – количество оценок отрицательных.
– количество оценок отрицательных.
![]() – количественный объем изучаемого текста или иной исследуемой единицы, в котором речь идет непосредственно об изучаемой проблеме.
– количественный объем изучаемого текста или иной исследуемой единицы, в котором речь идет непосредственно об изучаемой проблеме.
![]() – соответственно, общий объем всего изучаемого текста.
– соответственно, общий объем всего изучаемого текста.
В настоящее время существует большое количество сервисов в сети интернет для проверки на плагиат, которые укажут в процентном соотношении наличие заимствований. К ним можно отнести систему «Антиплагиат» (компания ООО «Текст») и другие. Но все они имеют как достоинства, так и недостатки.
Система «Антиплагиат» проводит поиск по большому количеству работ, хранящихся в базе данной системы. Но значительным минусом является то, что система не осуществляет поиск по документам, доступным в сети интернет.
Проверяемый материал проходит предварительную обработку, в которую входят следующие пункты:
- Преобразование регистра;
- Обработка замены символов, т. е. замена русских букв английскими;
- Обработка окончаний слов;
- Исключение из текста знаков препинания;
- Фильтрация текста, которая заключается в удалении наиболее частотных слов, редко встречающихся слов. Так же этой процедуре подвергаются слова, содержащие спецсимволы или слова большой длины.
Анализ вышеприведенных программ позволил выделить следующую структуру проверки текста на плагиат (рис. 1):
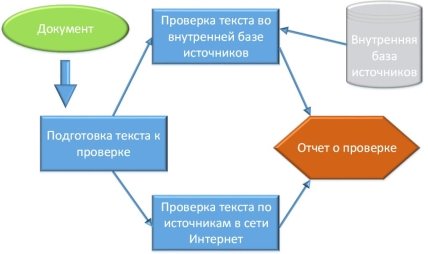
Рис. 1. Структура системы проверки текста на плагиат
На первом этапе осуществляется проверка по внутренней базе документов. Данная база включает в себя уже имеющиеся работы (статьи, курсовые, дипломные работы и диссертации).
На следующем этапе проводится проверка в сети интернет. Для этого текст документа разбивается на части (число частей зависит от размера документа). Далее с использованием поисковых систем проводится поиск тех источников, в которых имеются указанные информативные части.
И в заключении выдается отчет, в котором в процентном соотношении указано наличие заимствований [3].
Сейчас алгоритмы программы защищены от большого количества манипуляций, которые выполняются студентами для коррекции результата и увеличения уникальности текстов. В частности, система защищена от перестановки абзацев и замены кириллических букв латинскими, от перестановки слов и перегруппировки предложений, от замены пробелов точками, точек запятыми и отдельных слов их синонимами.
В связи с тем, что на данный момент не существует полнофункциональной программы «Антиплагиат», позволяющей производить развернутый анализ казахского текста, перед нами ставится задача разработки собственной системы методов и программного комплекса по поиску текста на плагиат на узбекском языке.
Внедрение данного комплекса позволит:
- оптимизировать процесс проверки текстовых работ обучающихся (на русском, узбекском и английском языках), сделать его более качественным, удобным, быстрым и технологичным;
- уменьшить трудозатраты преподавателей, избавить их от рутинного поиска совпадений или заимствований;
- осуществлять мониторинг ситуации с наличием плагиата в работах обучающихся в целом, по факультетам, кафедрам и другим структурным единицам, выявлять проблемные места, осуществлять контроль, как студентов, так и преподавателей [4].
Исследование и разработка системы методов и программного комплекса поиска текста, по нашему мнению, позволит повысить качество системы образовательного процесса за счет развития навыков самостоятельной работы при подготовке к научным работам.
Литература:
- Аушра А. Научная электронная библиотека, как средство борьбы с плагиатом// Международный форум Educational Technology & Society 9(3). — 2006.
- Барсамов В. А. Контент-анализ газетных материалов // СоЦис – 2006 – №2. Стр. 62-64. [Электронный ресурс]. — Режим доступа: http://ecsocman. hse. ru/socis/volumes. html (дата обращения: 21. 05. 2016).
- Шарапов Р. В., Шарапова Е. В. Система проверки текстов на заимствование из других источников // Всероссийская научная конференция Электронные библиотеки: Перспективные методы и технологии, электронные коллекции. — 2011.
- SearchInform Плагиат – Информ – система для определения плагиата в документах [Электронный ресурс]. — Режим доступа: http://searchinform. ru/main/full-text-search-company-legal. html (дата обращения: 20. 05. 2016).
