





BigData, MapReduce, облачные вычисления, NoSQL. Все эти понятия стали популярными в последние годы. И все они связаны с распределенной обработкой больших объемов данных. Hadoop — одна из самых популярных open-source систем для обработки больших объемов данных. Необходимость в таких системах растет с каждым годом — все больше компаний сталкиваются с проблемой растущего объема данных.
Facebook, Twitter, Yahoo!, Bing, Mail.ru — это далеко не полный список компаний, которые используют Hadoop. Многие из них, при этом, активно участвуют в его развитии. И это неслучайно, т. к. именно большие интернет-компании первыми столкнулись с проблемой обработки больших объемов данных: как их надежно хранить, как обрабатывать, как получать быстрый доступ на их изменение. Сейчас Hadoop используется не только в интернет-компаниях, но и во многих других сферах, где возникает проблема с объемом данных (экономика, астрономия, биология, физика и т. д.). В своей статье я хочу рассказать про дистрибутивы, подход MapReduce, а также MRIJ — метод соединения таблиц в рамках парадигмы MapReduce.
Обзор дистрибутивов.
Hadoop — это проект фонда Apache Software Foundation, свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Т. к. Hadoop — это не монолитный продукт, а экосистема, состоящая из множества компонентов, то в данной сфере существуют организации, которые свободно разрабатывают поддерживают уже собранные дистрибутивы Hadoop. Вот обзор основных вендоров Hadoop:
- Cloudera. Ключевой продукт — CDH (ClouderaDistributionincludingApacheHadoop) — связка наиболее популярных инструментов из инфраструктуры Hadoop под управлением ClouderaManager. Менеджер берёт на себя ответственность за развёртывание кластера, установку всех компонентов и их дальнейший мониторинг. Кроме CDH компания развивает и другие свои продукты, например, Impala (об этом ниже). Отличительной чертой Cloudera также является стремление первыми предоставлять на рынке новые фичи, пусть даже и в ущерб стабильности. Ну и да, создатель Hadoop — Doug Cutting — работает в Cloudera.
- Hortonworks. Так же, как и Cloudera, они предоставляют единое решение в виде HDP (Hortonworks Data Platform). Их отличительной чертой является то, что вместо разработки собственных продуктов они больше вкладывают в развитие продуктов Apache. Например, вместо Cloudera Manager они используют Apache Ambari, вместо Impala — дальше развивают Apache Hive. Мой личный опыт с этим дистрибутивом сводится к паре тестов на виртуальной машине, но по ощущениями HDP выглядит стабильней, чем CDH.
- MapR. В отличие от двух предыдущих компаний, основным источником доходов для которых, судя по всему, является консалтинг и партнёрские программы, MapR занимается непосредственно продажей своих наработок. Из плюсов: много оптимизаций, партнёрская программа с Amazon. Из минусов: бесплатная версия (M3) имеет урезанный функционал.
Архитектура Hadoop. Обзор.
По состоянию на 2016 год, проект Hadoop состоит из основных четырех модулей:
− HadoopCommon (набор инфраструктурных программных библиотек и утилит, используемых для других модулей и родственных проектов)
− HDFS (Распределенная файловая система)
− YARN (система для планирования заданий и управления кластером)
− HadoopMapReduce (платформа программирования и выполнения распределённых MapReduce-вычислений).
HadoopCommon.
В Hadoop Common входят библиотеки управления файловыми системами, поддерживаемыми Hadoop и сценарии создания необходимой инфраструктуры и управления распределённой обработкой, для удобства выполнения которых создан специализированный упрощённый интерпретатор командной строки (FS shell, filesystem shell), запускаемый из оболочки операционной системы командой вида: hdfs dfs-command URI, где command — команда интерпретатора, а URI — список ресурсов с префиксами, указывающими тип поддерживаемой файловой системы, например hdfs://example.com/file1 или file:///tmp/local/file2.
Бо́льшая часть команд интерпретатора реализована по аналогии с соответствующими командами Unix (таковы, например, cat, chmod, chown, chgrp, cp, du, ls, mkdir, mv, rm, tail, притом, поддержаны некоторые ключи аналогичных Unix-команд, например ключ рекурсивности-R для chmod, chown, chgrp).
Есть команды, специфические для Hadoop (например, count подсчитывает количество каталогов, файлов и байтов по заданному пути, expunge очищает корзину, а setrep модифицирует коэффициент репликации для заданного ресурса).
Архитектура Hadoop. HDFS.
HDFS — основа Hadoop, это файловая система для хранение больших данных. HDFS основана на другой большой системе –GFS (Googlefilesystem), она работает на кластере из серверов, на каждом из которых может быть своя файловая система (Ext3, Ext4), при этом для пользователя она выглядит как «один большой диск», т. к. скрывает внутри себя физическое управление файлами. HDFS обладает следующими свойствами:
− Хорошо подходит для хранения больших файлов (от 100 мб).
− FaultTolerance (данные не теряются, если диски выходят из строя).
Однако из-за особенностей архитектуры HDFS не подходит для:
− хранения большого количества маленьких файлов.
− постоянной записи на файловую систему, т. к. одновременно в файл может писать только 1 процесс.
Все файлы HDFS поделены на блоки определенного размера, и каждый блок может быть размещён на нескольких узлах, размер блока и коэффициент репликации (количество узлов, на которых должен быть размещён каждый блок) определяются в настройках на уровне файла). Благодаря репликации обеспечиваетсяустойчивостьраспределённой системы к отказам отдельных узлов. Организация файлов в пространстве имён —традиционная иерархическая: есть корневой каталог, поддерживается вложение каталогов, в одном каталоге могут располагаться и файлы, и другие каталоги.
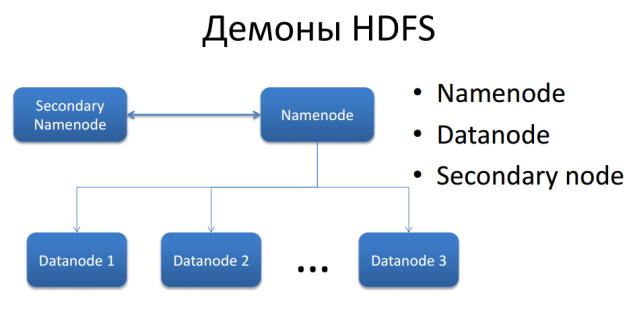
Рис. 1.
Развёртывание экземпляра HDFS предусматривает наличие центральногоузла имён(англ.name node), хранящегометаданныефайловой системы и метаинформацию о распределении блоков, и серииузлов данных(англ.data node), непосредственно хранящих блоки файлов. Узел имён отвечает за обработку операций уровня файлов и каталогов — открытие и закрытие файлов, манипуляция с каталогами, узлы данных непосредственно отрабатывают операции по записи и чтению данных. Узел имён и узлы данных снабжаютсявеб-серверами, отображающими текущий статус узлов и позволяющими просматривать содержимое файловой системы. Также для помощи в обработке существует SecondaryNode, в его обязанности входит обновление fsimage (файл, который используется для восстановления в случае падение кластера).
Архитектура Hadoop. MapReduce.
HadoopMapReduce — фреймворк для программирования распределенных вычислений в рамках Hadoop. Основан на двух операциях: Map и Reduce.
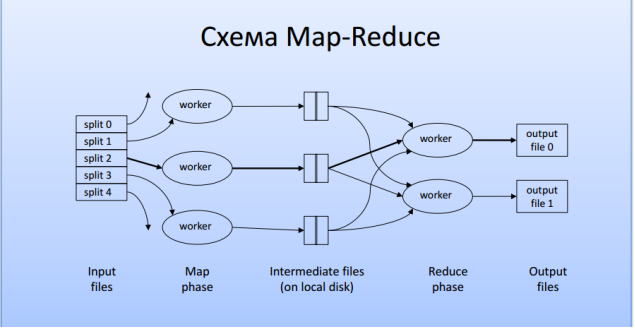
Рис. 2.
На входе файл бьется на «сплиты» определенного размера (который равен обычно размеру блока в hdfs). Далее каждому «воркеру» передается один «сплит». Затем происходит фаза Map. На каждом воркере стоит обработчик, который обеспечивает обработку входных данных, причем промежуточные результаты пишутся на локальный диск. На выходе «Маппера» получается пара Ключ — Значение, которая затем передается по сети «воркеру» с Reduce обработчиком. Стоит заметить, что данные с одним и тем же ключом попадают на один «воркер» и они начинают обрабатываться только тогда, когда отработают все «воркеры» с операцией Map. Далее начинается фаза Reduce, фаза свертки результата. Каждый «воркер» с Reduce обработчиком пишет в один файл, который сохраняются в HDFS.
Архитектура Hadoop. YARN.
YARN (YetAnotherResourceNegotiator) — модуль, который появился в 2013 году, он отвечает за управление кластерами и планирование заданий. В ранних версиях эта функция была интегрирована в модуль MapReduce, где была реализована как компонент JobTracker. Сейчас же в YARN функционирует самостоятельный демон –ResourceManager, который абстрагирует ресурсы кластера и управляет их предоставлением приложениям распределенной разработки. YARN обеспечивает возможность параллельного выполнения нескольких задач в рамках кластера и их изоляцию.
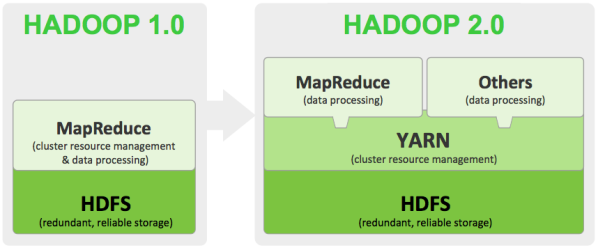
Рис. 3.
Для этого разработчику необходимо реализовать класс управления приложением ApplicationMaster, который отвечает за координацию заданий в рамках ресурсов, предоставленных планировщиком. Планировщик же отвечает за создание экземпляров класса управления приложением и взаимодействия с ним через соответствующий сетевой протокол.
Метод MRIJ.
MRIJ — метод доступа к данным, которые организованы в виде таблиц измерений и фактов, связанных по схеме «Звезда».
Типовой запрос StarJoin можно представить следующим образом:
SELECT D1.d11, D2.d21, F.m1
FROM D1 JOIN F ON (D1.d10 = F.fk1) JOIN D2 ON (D2.d20 = F.fk2)
WHERECD1 ANDCF1,
где Di — таблица измерений, а F — таблица фактов. Обычно при такой схеме запрос вида соединения вида F xD1 x D2 разделяется на два запроса F xD1 и Fx D2. Это производится на фазе Map, на фазе Reduce эти два варианта соединяются. Однако вычисление промежуточных результатов требует больших мощностей и высокую пропускную способность.
Описание метода MRIJ.
На первом шаге Первого Map-Reduce задания производится фильтрация таблиц, указанных в запросе Select (Для каждой таблицы). Результатом этого будут записи вида
Dkvi =
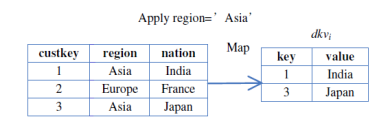
Рис. 4.
На втором шаге записи переносятся на узлы с другим обработчиком. На втором узле происходит следующее:
- Для всех входящих измерений строится хэш-индекс в памяти по их ключу
- Далее из таблицы факто читается колонка внешнего ключа и ищется в индекса, при успехе на выход отдается запись следующего вида:
- fkvi= <позиция, value >, где «позиция» — это номер строки таблицы фактов (нумерация сквозная по всем строкам таблицы фактов); value — список значений из соответствующей записи dkvi
- Далее читается очередная колонка из таблицы фактов и проверяется условие CF1 и при успехе на выход подается запись вида:
- vmj =<позиция, value >, где «позиция» — это номер строки таблицы фактов (нумерация сквозная по всем строкам таблицы фактов), value — значение факта
- Затем выполняется фаза Reduce: происходит группировка по позиции, затем проверяется число элементов, оно должно составлять n+k (n и k — это соответственно число измерений и фактов, участвующих в запросе) и проверяется удовлетворение условию запроса. В случае успеха на выход помещается запись вида: <позиция, (fkv1.value,…,fkvn.value,vm1.value,…,vmk.value)>
Литература:
1. Guoliang Zhou, Yongli Zhu, Guilan Wang Cache Conscious Star-Join in MapReduce Environments. — The Higher Education Scientific Research Project of Hebei Province — с. 7.
2. Том Уайт Hadoop: Подробное руководство. — СПб.: Питер, 2013. — 672 с.: ил. — (Серия «Бестселлеры O’Reilly»)
3. Donald Miner, Adam Shook MapReduce Design Patterns — O’Reilly Media, Inc. 2013 — с. 233.
4. Lars George HBase: The Definitive Guide — O’Reilly Media, Inc. 2011 — c. 524
5. БрюсЭккель.Философия Java = Thinking in Java. — 3-еизд. —СПб.:Питер, 2003. — 976 с. —ISBN 5–88782–105–1.
