





MapReduce
Технология MapReduce, поддерживается в среде баз данных NoSQL. Но существуют специальные каркасы MapReduce, имеющие файловые системы, оптимизированные под эту технологию. Примером такого каркаса является Hadoopс файловой системой HDFS.
Общий процесс обработки записей <ключ, значение> по технологии MapReduceвыглядит так:
map:
reduce:
В одном j-ом узле может выполняться несколько экземпляров функции «map». Она должна осуществлять следующие действия: разобрать входную запись и вернуть одну или несколько новых записей {
После завершения фазы Map каждый результирующий массив Fji записей (j= 1...n, i= 1...s) пересылается с j-го узла на узел, где выполняется i-й экземпляр функции «reduce». Важно подчеркнуть, что этот механизм пересылки массивов позволяет обрабатывать записи с одинаковыми значениями ключа в одном узле. Поступившие в узел записи массивов сортируются, объединяются и передаются на вход соответствующей функции «reduce». Программа «reduce» должна обработать записи объединенного массива и выполнить их «свертку» в соответствии с поставленной задачей. Функция «reduce» возвращает выходной массив(как правило, меньшей размерности), и система сохраняет его в виде записей <ключ, значение> в файловой системе MapReduce. Эти записи могут быть использованы в качестве входных данных для других заданий MapReduce.
Ниже приведен сложный пример: соединение двух таблиц, хранящихся в файлах File1 и File2, по значению ключа (Рисунок 3).
На одном узле функция Mapчитает записи файла File1, а на втором узле два экземпляра функции Mapчитают записи файла File2 (записи
Далее система автоматически выполняет хеширование записей по значению Ki первого поля ключа (создаются разделы) и реализует фазу «перетасовки» (shuffle). Записи с одинаковыми значениями Kiпопадают в один и тот же узел, так как разделы с одинаковыми значениями хеш-функции передаются в один узел. Система выполняет сортировку записей по составному ключу (см. Sorting) на каждом принимающем узле. Затем записи группируются по первому полю ключа (т. е. по Ki). Поля значений записей, попавших в группу, помещаются в поле значения новой записи (
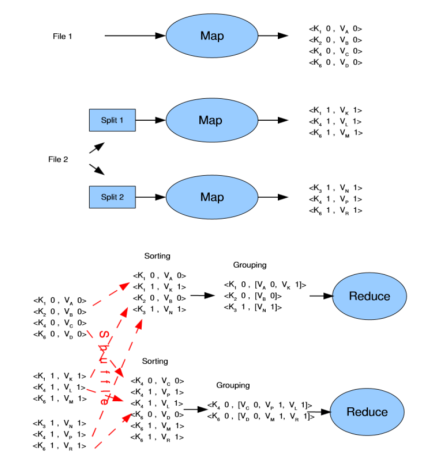
Рис. 1. Пример соединения таблиц по технологии MapReduce
И только после этого сформированная запись передается на вход функции Reduce. Эта функция анализирует запись и выполняет операцию декартова произведения значений файлов File 1 и File2 (ведь эти значения имеют один и тот же ключ соединения Ki). Ниже показан результат соединения (list
первыйReduce:
второйReduce:
Эти записи, в свою очередь, также могут быть сгруппированыи для них можно применить операции агрегирования (конечно, если Vm–это числовые значения).
Можно выделить следующие преимущества MapReduceHadoop:
- Простота установкиMapReduce(MR), ее относительно низкая стоимость.
- В функции «map» запроса к MR достаточно просто реализовать разбор (парсер) документа, а в функции «reduce» — объединение результатов разбора.
- Технология MapReduce обладает возможностью восстанавливать процесс обработки записей после сбоев в середине выполнения запроса с применением метода, не свойственного параллельным СУБД.
Метод доступа MFRJ
Таблицы измерений продублированы по всем узлам системы MapReduce (MR). Они хранятся по строкам. Таблица фактов делится на несколько групп: в 1-ю группу входят столбцы (колонки) внешних ключей измерений (fki), столбец каждого факта (mi) образует отдельную группу (группы 2,…,к+1). Все блоки таблиц измерений и групп таблицы фактов распределены MapReduce по узлам (автоматически) произвольным образом (MR пытается это делать равномерно).
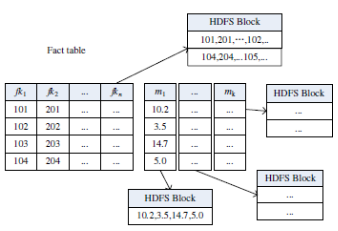
Рис. 2. Таблица фактов для варианта 1.
Доступ к данным выполняется следующим образом.
Map (в каждом узле):
- Для измерений, которые участвуют в запросе, строятся хеш-индексы в оперативной памяти.
- Читаются записи внешних ключей измерений таблицы фактов (группа 1), хранящиеся в узле (fki), для каждой строки (позиции) и каждого внешнего ключа проверяется наличие значения этого ключа в соответствующем хеш-индексе; при успешном сравнении в выходной поток помещает запись:
<позиция1, (vd1,…,vdn)>
где «позиция1» — номер строки в группе внешних ключей (нумерация сквозная по всем строкам группы 1); (vd1,…,vdn) — список значений требуемых по условию запроса столбцов таблиц измерений (выбираются из хеш-индексов).
- Читаются значения колонки i-го факта (группа i+1), хранящиеся в узле; для каждого значения факта проверяется условие CF1 запроса, и это значение помещается в выходной поток:
<позиция2i, vmi>,
где «позиция2i» — номер строки в группе i+1 (нумерация сквозная по всем строкам группы i+1), vmi — значение i-го факта.
Значения «позиций1» и «позиций2» могут не совпадать, т. к. по условию блоки групп таблицы фактов распределены по узлам произвольно.
- Далее пункт 3 повторяется для других колонок фактов, блоки которых хранятся в данном узле (i=1,…,k).
Reduce:
1. Если в полученной функцией Reduce записи (после группирования по позиции) число элементов в области значения равно n+k (n — число измерений, k — число фактов) и она удовлетворяет условию запроса (проверяются заданные отношения между столбцами), то эта запись помещается в выходной поток как строка результирующей таблицы:
<позиция, (vd1,…,vdn,vm1,…,vmk)>.
Литература:
- Zhou, G. Zhu, Y. Wang,G.Cache Conscious Star-Join in MapReduceEnvironments. Cloud-I '13 Proceedings of the аnd International Workshop on Cloud Intelligence, August 26 2013.
- Lee, RubaoHuai, Shao, Yin Zheng etc. RCFile: A fast and space-efficient data place-ment structure in MapReduce-based warehouse systems. ICDE 2011, pp. 1199–1208.
- KonstantinaPalla. A Comparative Analysis of Join Algorithms Using the Hadoop Map/Reduce Framework. Master of Science School of Informatics University of Edinburgh, 2009, pp 1–93.
- Уайт Т.Hadoop: Подробное руководство. — СПб: Питер, 2013. — 672 с.
- ЧакЛэм. Hadoop в действии. — М.: ДМК Пресс, 2012. — 424 с.
