С каждым годом в современном мире компьютерные технологии играют всё более важную роль. Компьютеры проникают во все сферы человеческой деятельности, от образования до создания новых материалов. И чтобы перевести технологию на следующий уровень эволюции, создаются новые программы, заменяющие старые и совершенствуются наиболее часто используемые программы. Компьютерные технологии продолжают внедряться в новые сферы жизни, приобретая все более разнообразные формы и способы использования. Благодаря интернету мы можем заказывать товары, оплачивать счета за коммунальные услуги, поддерживать связь с родственниками, не выходя из дома.
Актуальность этой работы вызвана тем, что в последние годы технологический прогресс привел к росту потока информации. Иногда трудно систематизировать огромное количество информации вручную, поэтому я хотел бы спросить — как я могу легко собрать определенную информацию? И мне не потребовалось много времени, чтобы найти ответ. Парсинг — это отрасль программирования, которая стремительно развивается. Однако я понимал, что научиться этому самостоятельно не легко, поэтому начал искать курсы, смотрел различные видео о том, как писать парсинг.
Целью этой работы является создание программы, которая может автоматически собирать данные о книгах с сайта и сохранять эту информацию в текстовом формате.
Задачи:
- Узнать новую информацию о парсинге.
- Создать свой парсер на языке программирования Python.
- Написать код, учитывая все нюансы.
- Сделать выводы после окончания работы.
Парсинг в XXI веке
Парсинг — процесс сбора и обработки данных с сайтов, находящихся в открытом доступе, специальными программами, которые автоматизируют этот процесс. Проще говоря- мы просто берём с помощью программы данные, которые сами могли бы скопировать вручную. Но, поскольку, лень — двигатель прогресса, проще сделать это скриптом. Сам парсер представляет собой скрипт, которым осуществляется сбор и обработка данной информации. Источником этих данных может служить HTML код, база данных, текст и др.
Как работает программа парсера :
- Поиск нужных источников по заданным данным.
- Извлечение нужной информации.
- Переделывание полученных данных в удобный нам формат.
- Сохранение информации в нужном виде.
Парсинг значительно расширяет диапазон деятельности людей. Он автоматизирует процесс анализа данных и снижает нагрузку на человека. Время и энергия могут быть перенаправлены на другие задачи. Это также ускоряет анализ больших объемов данных Это могут быть сотни интернет-магазинов, тысячи статей или огромные базы данных. Парсинг помогает разработчикам найти ошибки на сайте или в другом продукте данных, если он настроен на их поиск. Такими услугами пользуются интернет-маркетологи, веб-мастера и др.
Пример его использования: Сбор новостей. Для организованной подачи новостей новостные агентства используют парсеры. Они собирают всю обновлённую информацию и отправляют сотрудникам.
Создание парсера
Прежде всего надо выбрать сайт, с которого мы будем собирать информацию.
Я решил выбрать обычный сайт с фильмами The-cinema.in.
Начало создание кода
Загрузка библиотек
Я решил использовать самые популярные библиотеки для создания парсера: request и BeautifulSoup.
Далее нужно определиться с теми данными, которые мы хотим получить для каждого фильма. Я возьму такие данные, как название, ссылка на фильм, ссылка на постер фильма, жанр, год выпуска и описание. Занесём их в dataclass для более удобного хранения

2. Написание кода
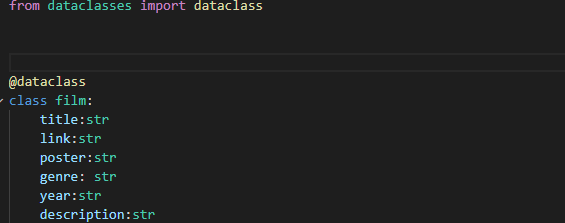
После этого создадим основную функцию, на вход передаём адрес страницы нашего сайта, а на выходе получим список с объектами класса film.
Создадим список для хранения в нём наших объектов. Отправим get запрос нашему сайту, а полученный результат положим в переменную response. Затем определяем объект класса BeautifulSoup, 1-м аргументом мы передаём текст нашего ответа, а 2-м мы передаём строку- в каком формате наш текст передаётся. Дальше можно начать искать в объекте BeautifulSoup объекты HTML.
Для этого открываем наш сайт. Выбираем параметр table -—в нём есть вся интересующая нас информация.

Далее идём в наш проект и вызываем у объекта BeautifulSoup метод find.
В ходе проекта получим все объекты div, которые входят в table при помощи функции find_all. Итерируемся по каждому блоку cards. Далее ищем параметр h2 с названием класса heading.

Следующим шагом получим постер нашего фильма.

Получим основную информацию о фильме, она лежит в параметре strong.

Для получение нужных нам параметров создадим отдельную функцию, где будем перебирать параметры по очереди и брать только нужные нам.
Остался последний этап. Помещаем все наши полученные данные в dataclass и получившийся объект добавляем в конец списка.
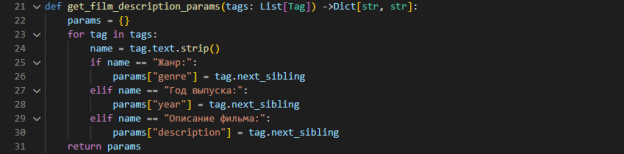
Всё вместе это выглядит так:
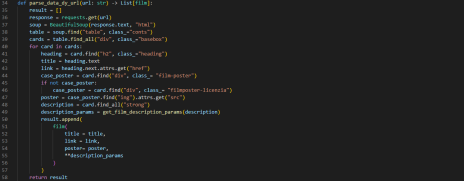
Для работы скрипта установим точку запуска.
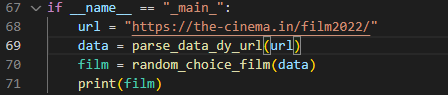
Бонусом напишем функцию, которая будет отдавать нам рандомный фильм из получившихся.
Импортируем библиотеку random.

Создадим функцию, которая будет принимать список фильмов, а возвращать только один. Выглядит это так:

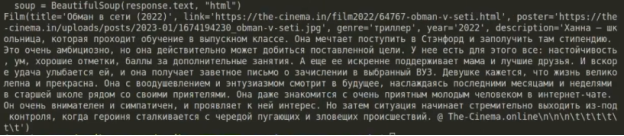
Вывод всего выглядит так:
Заключение
Эта статья была посвящена знакомству с отдельной область программирования — парсингу. У этого вида программирования много подводных камней. Самое интересное, конечно же, парсинг в Python. Благодаря обучению я освоил некоторые основы для создания собственной системы парсинга, а затем мне удалось создать свой стабильный и работающий парсер. Конечно при создании было много проблем. Сложность алгоритма в том, что он не только работает, но и читается.
Подводя итог этой работы могу сказать, что работа успешно завершена и парсер развивался, развивается и будет развиваться.

