The paper presents a VS Code module for automated extraction and visualization of Python function and class change history. By using Abstract Syntax Trees, the tool filters out irrelevant edits and reduces code audit time by more than 7 times.
Keywords: version control, abstract syntax tree, code analysis, Visual Studio Code, Python .
Введение
В современной разработке программного обеспечения поддержка качества и безопасности кода требует глубокого понимания истории его изменений. Стандартные инструменты систем контроля версий (Git) и популярные графические интерфейсы, такие как GitLens или Git History, работают преимущественно на уровне текстовых строк или целых файлов [1]. Это создает проблему избыточности информации: при анализе эволюции конкретного метода разработчик вынужден просматривать десятки коммитов, которые не затрагивают логику искомого компонента, а лишь изменяют соседние участки кода.
Ситуация осложняется спецификой языка Python, где семантика блоков определяется отступами. Обычный текстовый diff часто теряет контекст при изменении уровня вложенности. Общие методы статического анализа исходных текстов позволяют частично решить проблему понимания структуры [2], однако целью данной работы является создание специализированного модуля просмотра эволюции программных компонентов (ПМ ПЭПК), который изолирует историю конкретных синтаксических единиц от общего информационного шума репозитория.
Архитектура и алгоритм работы
Рис. 1. Схема концептуальной модели и архитектуры взаимодействия программного модуля
Логика системы реализована в виде конвейера, состоящего из трех независимых блоков: парсинга синтаксиса, извлечения истории из Git и формирования пользовательского интерфейса.
Процесс начинается с определения целевого компонента в редакторе. Модуль синтаксического разбора использует библиотеку tree-sitter для построения абстрактного синтаксического дерева. Использование AST является признанным методом для глубокого семантического анализа исходного кода [3]. Парсер выполняет рекурсивный обход дерева и точно определяет границы функции или класса по текущим координатам курсора, учитывая декораторы и вложенные структуры.
Затем подсистема истории запрашивает у Git список коммитов, в которых изменялся данный файл. Основная инновация заключается в алгоритме семантической фильтрации:
- Для каждой исторической ревизии файла строится AST.
- В дереве находится целевой компонент.
- Текст компонента сравнивается с его состоянием в предыдущем коммите с использованием оптимизированных алгоритмов выявления различий [4].
- Если код компонента идентичен, коммит отсеивается как нерелевантный.
Программная реализация и интерфейс
Модуль разработан как расширение для среды Visual Studio Code на языке TypeScript. Для обеспечения плавного пользовательского опыта интерфейс реализован через механизм WebView. Это позволило создать интерактивную панель, которая отображается рядом с основным кодом.
Основной элемент интерфейса — лента карточек коммитов. В отличие от стандартных инструментов, здесь отображается только фрагмент кода, относящийся к выбранной функции.
В заголовках карточек используется цветовая индикация типа изменений (создание, изменение, удаление), а внутри применяется подсветка синтаксиса и diff-разметка. Также предусмотрена кнопка вызова нативного редактора сравнения VS Code для просмотра изменений в контексте всего файла.
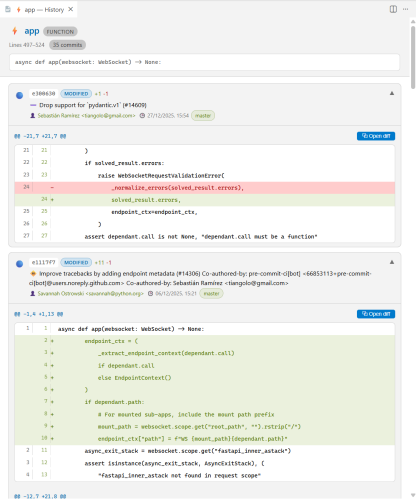
Рис. 2. Интерфейс ленты карточек коммитов с отображением дифференциальных блоков
Анализ результатов
Для проверки эффективности решения было проведено тестирование с участием 12 программистов. Задача состояла в поиске причин изменения конкретной бизнес-логики в модуле объемом более 1000 строк. Подобный подход к анализу компонентов на основе деревьев также доказывает свою эффективность в задачах поиска клонов и схожих фрагментов кода [5].
Результаты показали:
— Снижение операционной нагрузки: количество действий для вызова истории сократилось с 4–5 шагов до 2 кликов.
— Экономия времени: среднее время выполнения задачи сократилось с 4 минут 45 секунд до 35 секунд.
Алгоритм на основе AST позволил исключить до 90 % нерелевантных коммитов, что критически важно при работе с крупными проектами и частым рефакторингом.
Заключение
Разработанный программный модуль переходит от текстового сравнения файлов к семантическому анализу эволюции кода. Использование абстрактных синтаксических деревьев обеспечивает высокую точность выделения изменений, что существенно ускоряет процессы код-ревью, поиска дефектов и аудита безопасности. Модуль готов к интеграции в повседневный рабочий процесс разработчиков на Python.
Литература:
- Spinellis D. Version control systems // IEEE Software. — 2012. — Vol. 29, № 2. — P. 100–103.
- Apiwattanapong T., Orso A., Harrold M. J. A differencing algorithm for object-oriented programs // Proceedings of the 19th IEEE international conference on Automated software engineering. — 2004. — P. 2–13.
- Neamtiu I., Foster J. S., Hicks M. Understanding source code evolution using abstract syntax tree matching // Proceedings of the 2005 international workshop on Mining software repositories. — 2005. — P. 1–5.
- Myers W. An O(ND) difference algorithm and its variations // Algorithmica. — 1986. — Vol. 1, № 1. — P. 251–266.
- Falleri J. R., Morandat F., Blanc X. Fine-grained and accurate source code differencing // Proceedings of the 29th ACM/IEEE international conference on Automated software engineering. — 2014. — P. 313–324.

