Введение
При разработке, а также расширении корпоративных информационных систем, неотъемлемой частью является процесс проектирования. Существует несколько моделей такого процесса, каждая из которых описывает свой подход, в виде задач и (или) деятельности, которые имеют место в ходе процесса. Одной из такой моделей является итерационная. В данной модели работы выполняются параллельно с непрерывным анализом полученных результатов и корректировкой предыдущих этапов работы, причем в каждой итерации выполняется цикл: планирование, реализация, проверка, оценка. Преимущества данной модели заключается в следующем:
‒ Снижение рисков — раннее обнаружение конфликтов между требованиями, моделями и реализацией проекта; большая фокусировка на основных задачах; динамическое формирование требований и управление ими.
‒ Организация эффективной обратной связи проектной команды с потребителем, создание продукта, реально отвечающего его потребностям.
‒ Быстрый выпуск минимально ценного продукта и возможность вывести продукт на рынок и начать эксплуатацию гораздо раньше.
На сегодняшний день большинство подходов разработки программного обеспечения (ПО) используют данную модель. Одним из таких походов является экстремальное программирование. Основными целями данного подхода являются повышение доверия заказчика к программному продукту путем предоставления реальных доказательств успешности развития процесса разработки и резкое сокращение сроков разработки продукта. При этом экстремальное программирование сосредоточено на минимизации ошибок на ранних стадиях разработки. Это позволяет добиться максимальной скорости выпуска готового продукта и даёт возможность говорить о прогнозируемости работы. Практически все приемы подхода направлены на повышение качества программного продукта. Данный подход содержит 12 дисциплинарных (требующих выполнения разработчика) правил. Одним из таких правил является непрерывная интеграция. Это правило подразумевает интеграцию новых частей системы как можно чаще. Можно отметить, что интеграция новых частей зачастую влечет за собой изменения в базе данных (структура, данные и т. д.). Также на сегодняшний день нет легкодоступных средств для автоматизирования процесса миграций баз данных.
Постановка задачи
В среднем каждая корпоративная информационная система должна содержать несколько баз данных (БД):
‒ Рабочие БД — базы данных, предназначенные для конечных пользователей.
‒ Тестовые БД — базы данных, предназначенные для тестирования изменений, прежде чем переносить их на рабочие БД.
‒ БД «песочницы» — базы данных, предназначенные для каждого разработчика, в которых происходит разработка данных изменений.
Необходимо спроектировать инструмент, позволяющий переносить изменения с тестовой БД на рабочие. Встречаются случаи, когда на различных филиалах предприятия требуется внести различные изменения. В данной ситуации инструмент должен определять необходимые изменения для каждой рабочей БД. Также данный инструмент должен уметь создать новую БД (при расширении информационной системы) и привести ее в рабочее состояние. Встречаются случаи, при которых обновление занимает много времени. В таких случаях этот процесс будет отвлекать пользователя от работы, который ведет к потере концентрации. Следовательно, данный инструмент должен обеспечить удобное для пользователя время обновления информационной системы. Также можно отметить, что не все разработчики используют одни и те же инструменты для разработки информационных систем. Наш инструмент должен быть универсальным, т. е. иметь возможность работать с различными БД. Не всегда все сервера одной компании находятся в одной локальной сети. Следовательно, некоторые изменения происходят по сети интернет. Нужно предусмотреть возможность работу инструмента с различными протоколами.
Подведя итоги можно сформировать основные задачи:
‒ Инструмент должен выбирать необходимые изменения для каждой рабочей БД и применять их. При этом выполнение изменений должно происходить однократно.
‒ Возможность создать новую рабочую БД с нуля и привести ее в рабочее состояние.
‒ Возможность конечному пользователю самому выбрать время обновления системы.
‒ Возможность работы с различными системами управления баз данных (СУБД).
‒ Возможность использовать различные протоколы для передачи изменений.
Анализ ивыбор подхода
Есть несколько подходов:
1) Сравнение схем тестовой и рабочих БД.
2) Сравнение заскриптованной схемы (и данных) с рабочей БД.
3) На основе последовательных (инкрементных) SQL-скриптов.
4) Метод идемпотентных изменений.
Сравнение схем тестовой и рабочих БД.
Основной принцип данного подхода заключается в переносе всех изменений в структуре данных из тестовой в рабочую БД. Для этого генерируется скрипт, отражающий в себе все различия между тестовой и рабочей БД (diff-скрипт). Затем этот скрипт выполняется в рабочей БД, приводя ее в состояние, идентичное тестовой.
Плюсы:
‒ изменения в тестовой БД можно выполнять визуальными средствами;
‒ скрипт содержит только SQL-операторы изменения структуры данных.
Минусы:
‒ наличие нескольких тестовых БД (как правило, по одной на каждую из рабочих) вынуждает проводить процедуру несколько раз;
‒ внесение ненужных изменений для рабочей БД из тестовой;
‒ автоматическая генерация diff-скриптов не всегда корректно справляется со своей задачей. При перепроверке автоматически сгенерированных скриптов исчезает суть подхода, т. к. проще писать скрипты сразу вручную;
‒ невозможность обновить настройки рабочих БД и серверов;
‒ отсутствие хороших бесплатных инструментов. Среди платных инструментов требуется лицензия на каждый хост.
Сравнение заскриптованной схемы (и данных) с рабочей БД.
Основой данного подхода является каталог со скриптами, который позволяет создать базу данных с нуля (схемы, справочники и пр.). Разработчик должен вручную вносить изменения в скрипты, которые находятся в этом каталоге. После этого запускается инструмент, который сравнивает каталог с рабочей БД. Затем генерируется diff-скрипт и выполняется в рабочей БД.
Плюсы:
‒ необязательное скриптование всех изменений. Некоторые изменения являются вспомогательными и, как правило, используются разработчиками для тестирования новых функциональных возможностей;
‒ возможность изменения не только структуры, но и данных.
Минусы:
‒ ошибки, возникающие при ручном создании (изменении) скриптов;
‒ нет возможности сделать различные изменения в различных рабочих БД с помощью единого каталога. Для каждой рабочей БД необходимо создавать свой собственный каталог скриптов;
‒ автоматическая генерация diff-скрипта не всегда корректно справляется со своей задачей;
‒ нет возможности сравнивать настройки баз данных и сервера;
‒ отсутствие готовых решений.
На основе последовательных (инкрементных) SQL-скриптов.
Основой данного подхода является ручное написание скриптов (изменение структуры и данных в базе данных, настроек баз данных и пр.). Каждому из этих скриптов присваивается имя, удобное для разработчика, затем помещается в каталог. В определенное время запускается инструмент, выполняющий данные скрипты по порядку. Имя последнего можно запомнить во вспомогательной таблице рабочей БД для того, чтобы предотвратить повторное применение.
Плюсы и минусы данного подхода, в основном, совпадают с предыдущим подходом, но имеются и отличия.
Плюсы:
‒ хранение в скриптах изменения настроек баз данных, сервера и пр.;
‒ хранение всех скриптов для различных рабочих БД в едином каталоге.
Минусы:
‒ отсутствие пояснения к скриптам не позволяет сходу определить, за какие изменения они отвечают;
‒ готовые решения имеют высокую цену.
Метод идемпотентных изменений.
В основе данного подхода лежит один скрипт, позволяющий создать новую базу данных с нуля до последней версии. Каждое из изменений добавляется в конец скрипта разработчиком. Данный скрипт содержит ключевые слова if not exist, которые позволяют предотвратить повторное применение некоторых изменений.
Плюс:
‒ получение последней версии базы данных одним скриптом.
Минусы:
‒ потеря данных (например, если в скрипте изменений требуется удалить таблицу, а после создать новую с тем же именем, то после ее создания все данные в таблице будут потеряны);
‒ сложность написания и поддержки данного скрипта.
Сравнив данные подходы, можно сделать вывод, что больше всего плюсов имеет подход на основе инкрементных изменений. Используя репозиторий можно решить несколько минусов данного подхода. Например, при переименовании скрипта с существующим именем разработчик будет об этом уведомлен. С помощью ветвлений можно решить задачу по обновлению разных рабочих БД, используя различные наборы скриптов для каждого ветвления. Каждый comit может содержать описание изменений в добавленных скриптах. Пропадает строгая структура хранения каталога со скриптами. Разработчик делает удобную структуру для себя. Хранение скриптов возможно в удаленном репозитории.
Пример реализации
Рассмотрим основные моменты процесса переноса изменений из тестовой БД в рабочую. На первом этапе инструмент должен запросить изменения у тестовой БД. Запрос должен совершаться в определенное время или вручную пользователем для того, чтобы не отвлекать его от работы. Следовательно, инструмент должен быть запущен все время. Осуществить это можно используя службы. Далее инструмент на тестовой БД должен определить, какие изменения необходимо внести на данную рабочую БД. Следовательно, запрос должен содержать информацию о текущем состоянии рабочей БД, а также ее имя (уникальное или группы). Это можно решить с помощью создания дополнительной таблички в рабочей БД и хранении данной информации в ней. Следующий момент — хранение изменений. Используя инкрементный подход, необходимо все изменения писать в скриптах. Так как каждый скрипт должен выполниться в определенном порядке и иметь свое собственное имя, можно использовать репозиторий. С его помощью можно каждому скрипту присвоить уникальное имя, редактировать скрипты для повторных применений, а также выполнять их в том порядке, в котором были созданы или изменены, при этом для конкретной рабочей БД. После этого инструмент на тестовой БД должен сформировать пакеты для передачи на рабочую БД с необходимыми для нее скриптами. Затем инструмент на рабочей БД должен распаковать данные пакеты в указанную для него папочку и применить их. Во время применения могут возникнуть ошибки. О данной ошибке нужно оповестить разработчика. В данном случае инструмент должен вносить изменения одной транзакцией и, в случае ошибки, откатить ее до исходного состояния. При этом должен сформироваться пакет с описанием ошибки и скрипта, в котором она произошла. На тестовой БД инструмент должен внести данные об ошибке в отдельный файл для решения проблемы разработчику. При успешном выполнении транзакции на рабочей БД вносятся изменения в дополнительную табличку о текущем состоянии БД, а также формируется запрос об успешном внесении изменений. После этого на тестовой БД вносятся данные об успешном обновлении в файл разработчику.
Весь процесс переноса изменений можно разделить на две основные части: серверная часть (на сервере разработчика) и клиентская часть (на рабочем сервере). Наглядное отображение данного процесса отображено на диаграмме последовательности (рисунок 1).
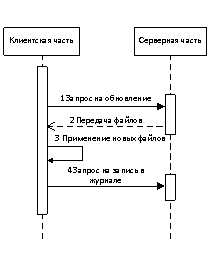
Рис. 1. Диаграмма последовательности — общий вид
Процессы, происходящие на клиентской и серверной частях, отображены на рисунках 2 и 3.

Рис. 2. Диаграмма последовательности — клиентская часть
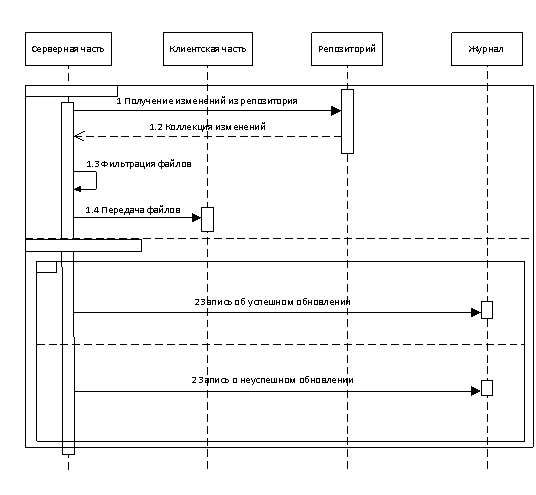
Рис. 3. Диаграмма последовательности — серверная часть
Используя данные диаграммы, можно реализовать инструмент для автоматических внесений изменений в рабочую БД из тестовой. Используя различные библиотеки можно работать с различными СУБД и репозиториями, которые используются на предприятии.
Литература:
- Скотт Амблер, Прамодкумар Дж. Садаладж Рефакторинг баз данных: эволюционное проектирование. М.: Вильямс, 2016.
- Кузнецов С. М. Информационные технологии: учебное пособие. — Новосибирск: НГТУ, 2011.
- Поль М. Дюваль, Стивен М. Матиас III, Эндрю Гловер Непрерывная интеграция: улучшение качества программного обеспечения и снижение риска. М.: Вильямс, 2016.
- Вольф Э. Continuous delivery. Практика непрерывных апдейтов. Спб: Питер, 2018.

