Through the analysis of the recommendation system, it is found that the traditional recommendation algorithm has some shortcomings, and the emergence of the hybrid recommendation algorithm effectively alleviates these problems.
Keywords: hybrid, recommender, system, Spark, collaborative, filtering
Introduction
Recommendation algorithms are the core of recommendation systems, and for recommendation algorithms, the more common ones are: collaborative filtering recommendation algorithms, content-based recommendation algorithms, association rule-based recommendation algorithms, and model-based recommendation algorithms. Although, many of them have been applied to the specific business of some large Internet companies, including the most classic and earliest used collaborative filtering-based recommendation algorithm, however, such common problems of recommendation algorithms as data sparsity [1] and cold start [2] still exist, so further research on common recommendation algorithms is needed thus to solve these problems.
Along with the exponential growth of data volume in the Internet era, traditional recommendation systems can no longer store huge amount of data as well as perform high-speed counting in single-server mode. Therefore, how to handle network-level data sets [3] is the problem that recommendation systems should reconsider. At this point, distributed counting techniques that store massive amounts of data on multiple machines emerge in order to improve the efficiency of system operation and to effectively reduce the information load. At the same time, the counting speed of the recommender system was further improved by parallelizing the models used.
Recommender Systems
Collaborative filtering-based recommendation algorithms
For collaborative filtering-based recommendation algorithms, we can classify such algorithms into: user-based, item-based, and model-based collaborative filtering algorithms. In most of our common recommendation systems, this type of recommendation algorithm is used [4]. For collaborative filtering algorithms, the main idea is to perform similarity calculation based on the user's historical information to accomplish the recommendation task. The following are brief descriptions of these types of collaborative filtering algorithms, respectively.
Hybrid recommender systems
Hybrid recommendation is a recommendation method that combines multiple recommendation algorithms in order to make better recommendations. The main reason for combining multiple recommendation algorithms is that any single recommendation algorithm has more or less its defects, and the hybrid recommendation, which combines multiple recommendation algorithms, can take advantage of some aspects of a single recommendation algorithm, and effectively integrate these advantages, so as to compensate for the disadvantages of some single recommendation algorithms, which is equivalent to a method that combines the strengths of a hundred schools of thought. If the combination is right, the advantages are indeed great.
Design and Implementation of Hybrid Recommendation Algorithm
The design ideas of the hybrid recommendation algorithm are as follows: first, in view of the problems of cold start and data sparseness in the traditional recommendation algorithm based on collaborative filtering, this research uses a statistical-based recommendation algorithm in the design of the offline recommendation algorithm to effectively alleviate the data.
For the sparse problem, the content-based recommendation algorithm is used to effectively alleviate the cold start problem, and the ALS-based matrix factorization model is used to further optimize and improve the collaborative filtering-based recommendation algorithm. Secondly, in view of the fact that the real recommendation system cannot update the recommendation results significantly after this rating or after several recent ratings, and cannot meet the real-time or quasi-real-time requirements of response time, this research proposes a model-based real-time recommendation algorithm to improve this problem.
Design and implementation of offline recommendation algorithm
For the offline algorithm design part of the recommendation system, the recommendation algorithms mainly used in this research are: statistics-based, collaborative filtering-based and content-based recommendation algorithms. Among them, the statistical-based recommendation algorithm mainly uses Spark SQL to perform statistical analysis on the offline recommendation of the recommendation system and the data information used for real-time recommendation, and prepares the data for them.
Experiments and Analysis
For comparative experiments, the first thing to mention is the experimental dataset. This article mainly uses the open source MovieLens dataset after processing. The size of the dataset is 200k, 1M and 10M. There are mainly three kinds of specific files in the dataset, namely: Movies dataset, Ratings dataset and Tag dataset.
Among them, the first set of comparative experiments set up a 10M data set as a fixed size data set, so that the commonly used recommendation algorithms and the hybrid recommendation algorithm designed by this system are respectively executed in the Spark platform and the stand-alone system. In order to verify the advantages of the hybrid recommendation algorithm proposed in this research, the following is a comparison chart of the execution efficiency of different algorithms, as shown in Figure 1:
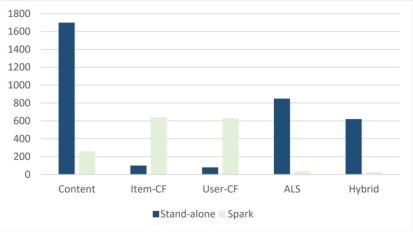
Fig. 1. Execution efficiency of different algorithms
For the second set of comparative experiments, it is mainly by using data sets of different sizes to execute on a single-machine system and a Spark distributed platform. Here, the same hybrid recommendation algorithm is guaranteed to be executed, so as to compare its execution efficiency and to verify this. The system is based on the advantages of the Spark platform. Figure 2 is the corresponding comparison chart:
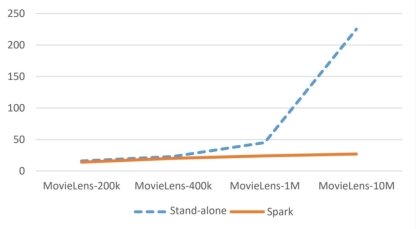
Fig. 2. Advantages of the Spark platform
By comparing and analyzing the execution efficiency of the two sets of comparative experiments, the first set of comparative experiments can verify that the hybrid recommendation algorithm proposed in this research has more advantages in algorithm execution efficiency than the traditional recommendation algorithm, and the second set of comparative experiments can verify Building a recommendation system based on the Spark distributed platform is more efficient than a single-machine recommendation system in the case of dealing with a large amount of data.
Conclusion
Through a comprehensive survey of the recommendation system, it is found that there are some problems in common recommendation systems, and the specific manifestations are as follows: Traditional recommendation algorithms have problems of sparse data and cold start, common recommendation systems cannot well meet users' requirements for real-time update of recommendation results, and with the continuous expansion of data scale, common stand-alone recommendation systems have been unable to complete recommendation tasks well. In view of these problems, this paper gives corresponding solutions.
References:
- Wang G, Liu H. Survey of personalized recommendation system [J]. Computer Engineering and Applications, 2012, 48(7): 66–76.
- Barjasteh I, Forsati R, Ross D, et al. Cold-Start Recommendation with Provable Guarantees: A Decoupled Approach [J]. IEEE Transactions on Knowledge & Data Engineering, 2016,28(6):1462–1474.
- Cozza V, Hoang V T, Petrocchi M, et al. Experimental Measures of News Personalization in Google News [J]. 2016.21–53.
- Meng Xiangwu, LIU Shudong, Zhang Yujie, et al. Research on Social Recommendation System [J]. Journal of Software, 2015, 26(6):1356–1372.

