В статье обосновывается актуальность разработки программного модуля, обеспечивающего проверку законов, находящихся в ведомстве Госдумы РФ, на плагиат. Также описывается метод латентно-семантического анализа, на основе которого разрабатывается алгоритм работы программного модуля.
Ключевые слова: программный модуль, латентно-семантический анализ, терм, корпус, матрица, TF-IDF, сравнение.
В Российской Федерации (далее РФ) основным законом является Конституция [1], которая представляет собой акт наивысшей юридической силы. Ни один правовой акт на территории РФ не может противоречить её Конституции. Следующими по важности являются федеральные конституционные законы, которые развивают положения Конституции. Они обладают высшей юридической силой по сравнению с другими законами. Далее идут федеральные законы, регламентирующие основополагающие стороны общественных отношений и государственной жизни. Именно они составляют основную массу законодательства. К объектам законотворчества Государственной Думы РФ (далее Госдума, ГД) и относятся проекты федеральных конституционных законов, федеральных законов и проекты постановлений [3].
На данным момент Госдумой РФ принято более 30000 законов и около 2200 постановлений. Анализируя статистику законодательного процесса с рис.1 за последние 13 лет, можно увидеть, что за это время было внесено и рассмотрено около 16000 законопроектов [2]. Путем нехитрых вычислений получаем, что в месяц приходится рассматривать около 100 законопроектов, причём каждый из них необходимо сравнивать со всеми уже принятыми законами и постановлениями.
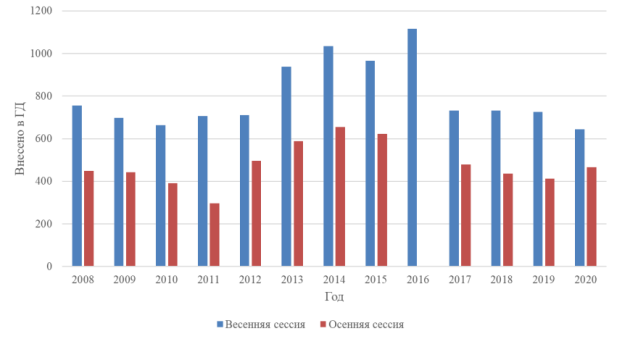
Рис. 1. Статистика законодательного процесса
Актуальность проблемы выявления заимствований в текстах законов обусловлена тем, что большинство систем и веб-сервисов для определения процента заимствований в текстах не предназначены для проверки на уникальность именно законов. Сравнение законов происходит со всеми доступными документами, зачастую не относящимися к законодательной деятельности. Также закон воспринимается как набор токенов (слов, предложений, абзацев и т. п.), без учёта структурных особенностей закона. Поэтому возникает необходимость разработки программного модуля, предназначенного для обработки только законов Госдумы РФ.
Для выявления смысловых зависимостей между законами был выбран метод латентно-семантического анализа (далее ЛСА), поскольку он является одним из лучших решений для проблемы выявления латентных зависимостей внутри множества документов [4]. Также этот метод позволяет снять полисемию и омонимию слов. Впоследствии он может быть применен как с обучением, так и без.
Любой закон назовём документом, а коллекцию документов будем называть корпусом. Документ разбивается на текстовые единицы (термы) — это могут быть символы, слова, словосочетания, предложения и т. д. Мы будем разбивать закон на слова.
Основной идеей ЛСА является отображение всех документов и встречающихся в них термах в «семантическое пространство», иначе называемое матрицей термы-на-документы. По этой матрице и производятся все дальнейшие вычисления. Подобное отображение позволяет сравнить два терма или документа между собой, а также сравнить терм и документ друг с другом.
Но перед тем, как приступить к самому алгоритму, требуется подготовить для него данные. В нашем случае поскольку структура написания закона одна, то требуется выделить в законе именно те части, которые несут информацию, необходимую для сравнения с другими законами. Поэтому возьмем только те разделы, которые обозначены следующими заголовками:
- «Постановление».
- «Федеральный закон».
- «Пояснительная записка».
Выделенные части также необходимо избавить от так называемого «шума», к которому относятся нерелевантные символы (знаки препинания и цифры), стоп-слова (предлоги, частицы, союзы и т. д.) и нерелевантные слова (применимо к обработке законов ими являются такие термы, как «Конституция Российской Федерации», «вносится на рассмотрение», «о внесении изменения в статью» и т. д.). Далее все слова сводятся к словарной форме при помощи алгоритма лемматизации. На выходе имеем текст закона, очищенный от «шума» и готовый для сравнения с другими законами.
Чтобы использовать модель мешка слов, сначала необходимо определить словарь всех уникальных термов корпуса. Этот словарь ограничит размерность будущей матрицы по одной оси. А число строк матрицы определяется количеством документов в корпусе. В таблице 1 можно увидеть, что на пересечении устанавливается значение «1», если соответствующий терм присутствует в документе, иначе «0». Такая матрица соответствует матрице инцидентности, строки которой соответствуют документам, а элементы строк — наличию соответствующих терминов в этих документах.
Таблица 1
Пример матрицы термы-на-документы
|
отменить |
реализация |
механизм |
противодействие |
… | |
|
Закон 1 |
1 |
1 |
0 |
0 |
… |
|
Закон 2 |
1 |
0 |
1 |
1 |
… |
Теперь надо учесть, что тот или иной терм может встретиться в одном документе несколько раз. Как правило, элементы матрицы заменяются на весы, позволяющие учесть частоту появления каждого терма в каждом документе и появление терма во всех документах. Такая статистическая мера называется TF-IDF.
Отдельно рассчитывается мера TF:
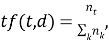
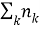
И мера IDF:
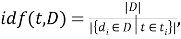
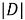
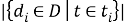
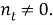
Итоговая мера TF-IDF является произведением двух сомножителей TF и IDF:
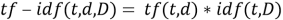
Далее можно с помощью метрик вычислить сходство двух законов. Существует несколько видов расстояний: редакционное, манхэттенское, Левенштейна и т. д. Но с векторной моделью представления информации лучше использовать косинусное расстояние, когда мера сходства двух документов оценивается через косинус между двумя числовыми векторами, представляющими эти документы. Косинусное расстояние между двумя документами 𝐷
1
и 𝐷
2
:
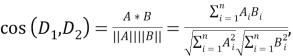
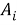
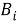
Таким образом, метод ЛСА позволяет представить множество законов в удобном виде для анализа, а сопоставление значений, вычисленных по метрике косинусного расстояния между разными законами, даёт возможность определить степень их смыслового сходства. Программный модуль позволит производить анализ заимствований, путем сравнения законов, что позволит улучшить существующую законодательную систему.
Литература:
- Конституция Российской Федерации: [принята всенародным голосованием 12 декабря 1993 г. с изменениями, одобренными в ходе общероссийского голосования 01 июля 2020 г.] — Текст: электронный // Официальный интернет–портал правовой информации: [сайт]. — URL: http://www.pravo.gov.ru (дата обращения: 09.03.2021).
- Государственная Дума. — Текст: электронный // Государственная Дума: [сайт]. — URL: https://www.gosduma.net (дата обращения: 20.05.2021).
- Система обеспечения законодательной деятельности. — Текст: электронный // Система обеспечения законодательной деятельности: [сайт]. — URL: https://sozd.duma.gov.ru (дата обращения: 20.05.2021).
- An Introduction to Latent Semantic Analysis / Thomas K Landauer, Peter W. Foltz, Darrell Laham. — Discourse processes, 1960. — Текст: непосредственный.

