В статье уделяется внимание разработке компьютерной модели сверхширокополосного канала связи. В данной работе были проведены исследования метода классификации Random Forest для обнаружения аномалий в сетевом трафике сверхширокополосного канала связи. Для эффективного применения интеллектуального анализа данных в первую очередь были разобраны наиболее частые атаки на сетевые ресурсы СШП канала связи. В результате чего был выбран метод машинного обучения с учителем. Основываясь на различных источниках, был выбран универсальный метод классификации Random Forest, который эффективно справляется с нелинейной регрессией. Сравнение критериев эффективности модели без настроек и с применением изученных значений параметров демонстрируют колоссальный прирост эффективности более чем на 14 %, что подтверждает верность выбора параметров.
Ключевые слова: интеллектуальный анализ данных, компьютерная модель, сверхширокополосный канал связи, аномалии, машинное обучение, метод классификации Random Forest
The article focuses on the development of a computer model of an ultra-wideband communication channel. In this paper, studies of the Random Forest classification method were carried out to detect anomalies in the network traffic of an ultra-wideband communication channel. For the effective application of data mining, first of all, the most frequent attacks on the network resources of the UWB communication channel were analyzed. As a result, the supervised machine learning method was chosen. Based on various sources, a universal classification method Random Forest was chosen, which effectively handles non-linear regression. Comparison of the performance criteria of the model without settings and using the studied parameter values demonstrate a colossal increase in efficiency by more than 14 %, which confirms the correctness of the choice of parameters.
Keywords: data mining, computer model, ultra-wideband communication channel, anomalies, machine learning, Random Forest classification method
В настоящее время сверхширокополосные сигналы широко используются в современных высокоскоростных системах связи стандартов WiMax, LTE, при передаче информации цифрового телевидения (DVB-T) и радио (DRM, DAB), в системах радиолокации и т. д. В связи с ростом вычислительной мощности и количества узлов в любой сети увеличивается и количество данных, проходящих через них, что влечет за собой необходимость применения все более совершенных подходов к обеспечению информационной безопасности, при условии непрерывной безотказной работы информационной системы, что обеспечивает актуальность рассматриваемой темы.
В связи с тем, что в крупных предприятиях большая часть работы происходит с использованием сетевого взаимодействия, корпоративные сети все чаще подвергаются атакам злоумышленников [3, с. 12]. Анализ сетевого трафика сверхширокополосного канала связи на сегодняшний день является одним из самых перспективных направлений обеспечения сетевой безопасности.
В данной работе рассмотрена идея предотвращения атак путём анализа трафика с целью выявления аномалий, и последующее игнорирование таких пакетов. Для этого использован нелинейный регрессионный анализ сетевого трафика в перспективе в связке с устройствами сбора, накопления и обработки.
Для оценки качества алгоритмов классификации данных можно использовать различные критерии и показатели [2]. В основном они базируются на полноте ( recall ) и точности ( precision ), которые в свою очередь получаются из отношений ошибок второго и первого рода.
Ошибка первого рода («ложная тревога») заключается в определении положительного примера как отрицательного [1]. Например, классификация здорового пациента как больного.
Ошибка второго рода заключается в определении отрицательного примера как положительного. Например, классификация больного пациента как здорового. Минимизацией ошибок такого рода надо заниматься в первую очередь, т. к. они несут большую угрозу нежели ошибки первого рода.
В результате применения модели к исследуемым данным можно получить четыре исхода:
TP ( true positive ) — истинно-положительный — верная классификация положительного примера как положительного;
FP ( false positive ) — ложноположительный — ошибка первого рода, неверная классификация положительного примера как отрицательного;
TN ( true negative ) — истинно-отрицательный — верная классификация отрицательного примера как отрицательного;
FN ( false negative ) — ложноотрицаетльный — ошибка второго рода, классификация отрицательного примера как положительного.
Обычно эти исходы представляются в виде упрощенной таблицы ошибок (таблица 1).
Таблица 1
Матрица ошибок сверхширокополосного канала связи
|
Экспертная оценка | |||
|
Положительная |
Отрицательная | ||
|
Оценка классификатора |
Положительная |
TP |
FP |
|
Отрицательная |
FN |
TN | |
Точность ( precision ) — это доля наблюдений, действительно принадлежащих данному классу относительно всех наблюдений, которые система отнесла к этому классу.
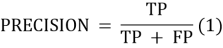
Полнота ( recall ) — это доля найденных классификатором наблюдений, принадлежащих классу относительно всех документов этого класса в тестовой выборке.
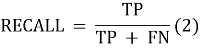
Дополнительно в качество метрик качества работы алгоритмов сверхширокополосного канала связи рассматриваются AUC ( area under curve — площадь под ROC ) и процент корректно распознанных наблюдений TPR .
ROC монотонно не убывает. Чем ближе кривая пролегает к точке (0,1), тем лучше работает классификатор. На рисунке 1 представлены результаты работы сверхширокополосного канала связи классификатора с низким уровнем качества (слева), у которого процент ошибки примерно равен 50, и классификатора с удовлетворительным уровнем качества (справа). Видны различия ROC в зависимости от уровня качества классификации и наглядно показано на какой вид данной кривой надо ориентироваться при оценке.
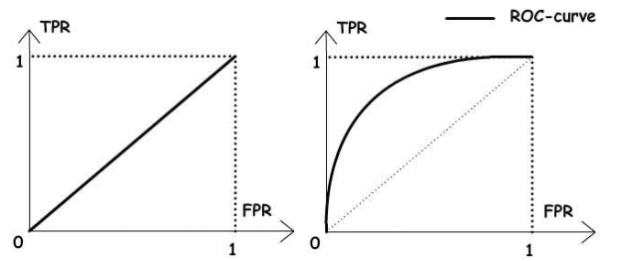
Рис. 1. Вид ROC -кривой в зависимости от качества работы классификатора
Для того чтобы оценить
AUC
(площадь под кривой) введём дополнительное обозначение
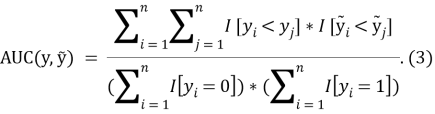
Регрессионный нелинейный анализ, позволяет выявить нелинейные отношения между параметрами и дать приблизительные прогнозы высокой точности сверхширокополосного канала связи.
В работе применяется анализ данных, обеспечивающий автоматическое выявление скрытых закономерностей. Для этих целей использован алгоритм классификации Random Forest , в котором результат большого множества классификаторов усредняется и даёт результат более высокой точности.
Алгоритм Random Forest (случайный лес) является типичным представителем алгоритмов машинного обучения с учителем для классификации данных.
Введем следующие определения:
множество признаков:
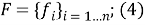
множество значений признака:
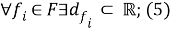
мера неоднородности множества:
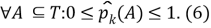
Таким образом задаётся эмпирическое дискретное вероятностное распределение меток в подмножестве наблюдений [2].
Несмотря на то, что в середине выборки объекты разных классов сильно перемешаны, при помощи дерева решений эта проблема решается: на каждом шаге необходимо выбирать признак и значения порога, по которому происходит оптимальное разбиение по заданному критерию.
Для каждого типа прикладных задач используется свой критерий разбиения. От правильного выбора критерия зависит качество полученного решения.
Для решения задач классификации чаще прочих используется критерий iGain :
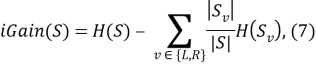
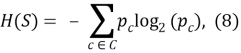
где
C
— множество классов рассматриваемой задачи, а
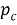
Для задач регрессии применяется аналогичный iGain критерий с использованием дисперсий:
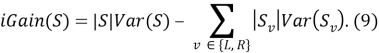
После построения всех деревьев каждый тестовый объект 𝑧 𝑖 получает в качестве промежуточного ответа вектор меток, присвоенных ему каждым деревом, который преобразуется в финальную метку по методу простого голосования [2].
После рассмотрения всей теоретической базы перейдем непосредственно к разработке модели сверхширокополосного канала связи.
Для моделирования и тестирования моделей сверхширокополосного канала связи будет использоваться обучающее и тестовое множества наблюдений из комплекта NLS-KDD , которые, по содержанию можно разделить на пять групп:
нормальные (позволительные, не атака);
DoS ( denial of service ) — атака, отказ в обслуживании, нацеленная на превышение количества одновременных подключений и исчерпыванию пропускной способности сервера; в выборке представлены шесть типов: land , teardrop , back , pod , neptune , smurf ;
probing — атака, производится в основном за счёт сканирования портов, и выяснения информации о машине; в выборке представлены четыре типа: satan , ipsweep , nmap , portsweep ;
R2L ( remote to local attack ) — атака, направленная на получение удалённого доступа к машине жертвы; в выборке представлены восемь типов: warezclient , guess_passwd , spy , imap , multihop , ftp_write , warezmaster;
U2R ( user to root ) — атака, направленная на локального пользователя системы, с целью получения прав суперпользователя благодаря уязвимостям операционной системы; в выборке представлены четыре типа: buffer_overflow , loadmodule , rootkit .
Обучающая выборка содержит 21 вид атак из 37 присутствующих в тестовой выборке. Известные атаки — это такие атаки, которые представлены в обучающем множестве, в то время как новые атаки — дополнительные атаки в тестовом множестве.
На рисунках 2 и 3 приведены гистограммы распределения типов данных в обучающей и тестовой выборках соответственно.
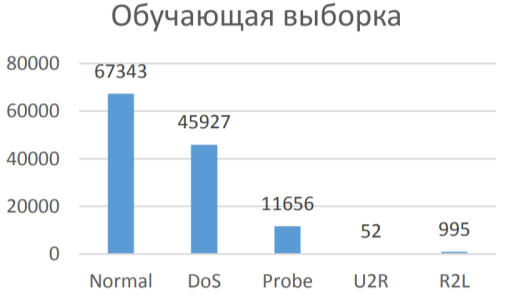
Рис. 2. Гистограмма распределения типов данных в обучающей выборке
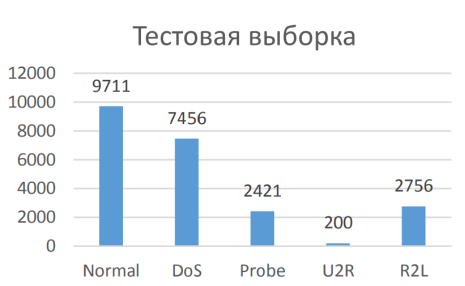
Рис. 3. Гистограмма распределения типов данных в тестовой выборке
Особенности тестовой выборки:
в тестовой выборке нет избыточных наблюдений, поэтому классификатор будет давать объективный результат;
в тестовой выборке нет наблюдений, пересекающихся с обучающей выборкой, что не будет способствовать улучшению результата.
Все атрибуты обучающей и тестовой выборок приведены в таблице 2.
Таблица 2
Атрибуты выборок сверхширокополосного канала связи
|
№ |
Имя |
Описание |
|
Основные атрибуты | ||
|
1 |
duration |
Продолжительность подключения |
|
2 |
protocol_type |
Протокол соединения |
|
3 |
service |
Сетевая служба соединения |
|
4 |
src_bytes |
Количество исходящих байт |
|
5 |
dst_bytes |
Количество входящих байт |
|
6 |
flag |
Статус соединения |
|
7 |
land |
Если src_ip = dst_ip тогда 1, в противном случае 0 |
|
8 |
wrong_fragment |
Число фрагментов с ошибкой |
|
9 |
urgent |
Срочные пакеты |
|
Атрибуты, отражающие содержимое пакетов | ||
|
10 |
hot |
Индикатор: вход в директории, создание, выполнение |
|
11 |
num_failed_logins |
Неудачные попытки входа |
|
12 |
logged_in |
При успешном входе =1, в противном случае 0 |
|
13 |
num_compromised |
Скомпрометированные состояния |
|
14 |
root_shell |
Получение root -прав, успех =1, в противном случае 0 |
|
15 |
su_attempted |
Получение su root -прав, успех =1, иначе 0 |
|
16 |
num_root |
root -доступ, количество |
|
17 |
num_file_creations |
Операции по созданию файлов |
|
18 |
num_shells |
Вызовы shell -оболочки |
|
19 |
num_access_files |
Количество доступов к файлам |
|
20 |
num_outbound_cmds |
Количество исходящих команд по FTP |
|
22 |
is_guest_login |
Если произошел гостевой вход =1 |
|
Атрибуты, отражающие характеристики пакетов | ||
|
23 |
count |
Число подключений к хосту за 2 секунды |
|
24 |
serror_rate |
Процент соединений с SYN -ошибками |
Далее исследуем выбор наиболее информативных атрибутов. Для улучшения результатов, после всех проведённых экспериментов, очистим начальную выборку из 41 параметра, применив к ней метод главных компонент, чтобы оставить наиболее информативные атрибуты.
Процесс происходит в несколько шагов: 1.
зафиксировать выборку — 41 параметр;
вычислить средние значения:
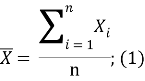
вычесть полученное в предыдущем шаге среднее значение из суммы значений по каждому атрибуту, что центрирует выборку в результате чего итоговый набор данных примет нулевое среднее значение;
вычислить ковариационную матрицу — такая матрица будет двумерной поскольку данные двумерны:
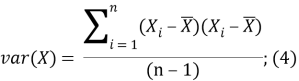
вычислить собственные векторы и собственные значения ковариационный матрицы: для получения значения информативности, возможно вычислить собственные вектора и собственные значения, так как матрица квадратная;
сформировать выборку атрибутов: основываясь на полученных значениях отобрать атрибуты, значение функции для которых получилось наибольшим.
Полученные в результате всех преобразований атрибуты и называются главными компонентами. Полный их список приведен в таблице 3.
На рисунке 4 представлена гистограмма информативности атрибутов.
Таблица 3
Перечень главных компонент
|
Важность атрибута |
Номер в изначальной выборке |
Наименование атрибута |
Величина собственного значения |
|
1 |
5 |
src_bytes |
9,913595 |
|
2 |
33 |
dst_host_srv_count |
8,64 |
|
3 |
32 |
dst_host_count |
5,380869 |
|
4 |
3 |
service |
5,380742 |
|
5 |
2 |
protocol_type |
5,379961 |
|
6 |
4 |
flag |
5,37782 |
|
7 |
29 |
same_srv_rate |
5,369393 |
|
8 |
34 |
dst_host_same_srv_rate |
5,356421 |
|
9 |
36 |
dst_host_same_src_por_name |
5,354023 |
|
10 |
12 |
logged_in |
5,306561 |
|
11 |
6 |
dst_bytes |
5,288926 |
|
12 |
37 |
dst_host_srv_diff_host_name |
5,288926 |
|
13 |
35 |
dst_host_diff_serv_rate |
5,258945 |
|
14 |
1 |
duration |
5,117015 |
|
15 |
31 |
srv_diff_host_rate |
3,201556 |
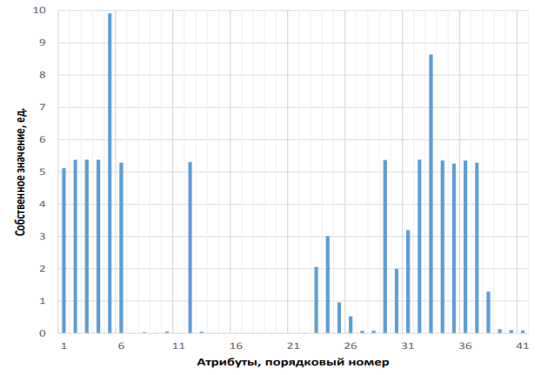
Рис. 4. Гистограмма информативности атрибутов
Удаляя по одной компоненте, получаем график, изображенный на рисунке 5.
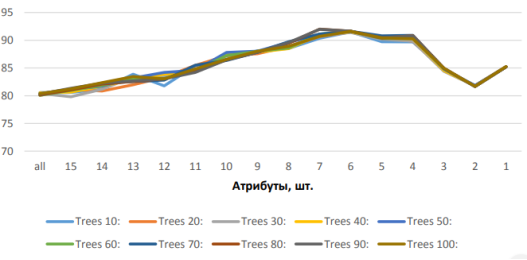
Рис. 5. Качество модели при последовательном уменьшении количества главных компонент
Таким образом, было определено оптимальное количество главных компонент для эффективной работы модели, но полученные результаты не являются удовлетворительными, хоть и удалось поднять эффективность работы модели почти на 10 %. Зная оптимальное количество атрибут, было принято решение перебрать все главные компоненты, то есть обучить модель, используя все возможные сочетания без повторений.
Опираясь на ранее полученные результаты исследования параметров, перебор дал положительные результаты. Максимального обнаружения удалось достичь при следующем множестве атрибутов [5, с. 56]:
duration;
protocol_type;
service;
flag;
src_bytes;
dst_bytes;
class.
При количестве деревьев равном 70, максимальная глубина дерева составила 12 узлов, переменных при делении узла было 3, а минимальное количество наблюдений на лист составило 5. Детальный разбор ошибок представлен в таблице 4.
Таблица 4
Сводная таблица матриц ошибок сверхширокополосного канала связи
|
Модель без настроек |
Модель с настройками и методом главных компонент | |||
|
A |
B |
A |
B |
Классификатор |
|
9447 |
264 |
9255 |
456 |
A = normal |
|
4143 |
8690 |
790 |
12043 |
B = anomaly |
В таблице 5 приведено сравнение результатов двух моделей, без использования каких-либо настроек и метода главных компонент и с использованием настроек и метода главных компонент.
Таблица 5
Сравнение моделей сверхширокополосного канала связи
|
Корректно распознанные наблюдения |
Некорректно распознанные наблюдения |
AUC | |||
|
Количество |
% |
Количество |
% | ||
|
Модель без настроек |
18137 |
80,45 |
4407 |
19,55 |
0,959 |
|
Модель с настройками и методом главных компонент |
21298 |
94,47 |
1246 |
5,53 |
0,971 |
|
Улучшение, количество |
3161 |
0,012 | |||
|
Улучшение, % |
14,021 |
1,2 | |||
Улучшение модели оказалось не всесторонним. При улучшении, уменьшение в 5,2 раза количества ошибок второго рода привело к возрастанию количества ошибок первого рода более чем в 1,5 раза.
Однако, изначально ошибок первого рода было 264, а ошибок второго рода, более серьёзных, около четырёх тысяч. Несмотря на это, общую эффективность модели удалось увеличить на 14 %. После завершения всех исследований становится очевидна эффективность метода главных компонент, который, по сути, работает с выборкой, обогащая её. Сам метод и его параметры способны незначительно улучшить результат классификации, не более чем на 2 %. Однако учитывая их количество и возможность их изменения, за счёт одних только параметров, корректно настроенных для данной выборки можно получить улучшение на ~5 %.
Литература:
- Проблемы и методики анализа трафика телекоммуникационных компьютерных сетей [Электронный ресурс]: Режим доступа: http://www.nsu.ru/archive/conf/nit/97/c8/node19.html
- Регрессионный анализ [Электронный ресурс]: Режим доступа: http://bibliofond.ru/view.aspx?id=20926
- Canty, M. J. Image Analysis, Classification and Change Detection in Remote Sensing: With Algorithms for ENVI/IDL and Python / M. J. Canty — Crc Press, 2019.
- Chen, Y. ID-Based Certificateless Electronic Cash on Smart Card against Identity Theft and Financial Card Fraud / Y. Chen, J. S. Chou // The International Conference on Digital Security and Forensics (DigitalSec2014). — The Society of Digital Information and Wireless Communication, 2019. — pp. 56- 67.
- Kovalev, S. M. Fuzzy model based intelligent prediction of objective events / S. M. Kovalev, A. V. Sukhanov, V. Styskala // Proceedings of 1st EuropeanMiddle Asian Conference on Computer Modelling. — 2018.

