





Цель данной исследовательской работы основывается на двух ключевых темах: как глубинное обучение может помочь в разрешении специфичных проблем в анализе больших данных, и, как определенные области глубинного обучения могут быть улучшены для соответствия задачам, связанным с анализом больших данных. В работе показываются примеры применения глубинного обучения к некоторым областям анализа больших данных и сложности, связанные с их имплементацией.
Ключевые слова: глубинное обучение, алгоритмы, большие данные, искусственный интеллект
Основной упор в машинном обучении идет на представление входных данных и обобщении изученных наборов данных для использования на будущих неизвестных данных. Правильность представления информации имеет важное значение для производительности машин обучения данным. Плохое представление скорее всего снизит производительность даже сложной, продвинутой машины обучения, а хорошее представление данных может привести к высокой производительности куда более простой машины обучения. Поэтому проектирование признаков, которое фокусируется на создании признаков и представлений данных из сырых данных. Это важный элемент машинного обучения. Проектирование признаков занимает большую часть работы в задаче машинного обучения, и часто бывает зависима от области исследования и требует большого участия человека. К примеру, методы гистограмм направленных градиентов и ускоренных устойчивых признаков, являются популярными методами проектирования признаков, особенно в компьютерной обработке изображений и видео. Выполнение проектирования признаков в более автоматизированном и обобщенном виде будет большим прорывом в машинном обучении, так как это позволит специалистам автоматически получать такие признаки без прямого участия человека.
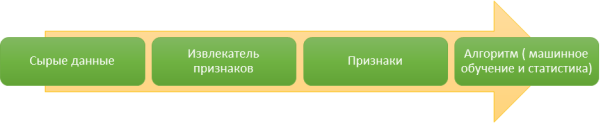
Рис. 1. Процесс обработки данных
Алгоритмы глубинного обучения одно из перспективных направлений исследований в сфере автоматизации получения сложных представлений данных на высоких уровнях абстракции. Такие алгоритмы создают многослойную иерархическую архитектуру обучения и представления данных. В таких архитектурах абстрактные признаки описываются с помощью менее сложных признаков. Иерархическая архитектура обучения в алгоритмах глубинного обучения основывается на эмулировании искусственным интеллектом глубинных многослойных процессов обучения основных чувственных зон неокортекса человеческого мозга. Эти зоны автоматически извлекают признаки и абстракции из базовых данных. Алгоритмы глубинного обучения эффективны при работе с обучением на основе больших объемов неструктурированных данных, и, обычно, обучаются представлениям данных в слоях в жадном виде. Эмпирические исследования показали, что представления данных полученные из сложения нелинейных извлеченных признаков часто выдают лучшие результаты машинного обучения. Решения на основе глубинного обучения представили превосходные результаты в различных сферах применения машинного обучения, таких как обработка и распознавание речи, распознавание образов и обработка естественных языков.
Процессы добычи и извлечения что-либо значащих наборов данных из огромных входных данных для принятия решений, предсказаний, и других видов процессов получения выводов на основе данных есть основа анализа больших данных. В дополнение к анализу огромных объемов данных, анализ больших данных привносит и другие сложные задачи для машинного обучения и анализа. К примеру, различное форматирование сырых данных, быстрые потоковые данные, определение степени доверия к анализу данных, высокодисперсные источники данных, зашумленные и плохие данные, высокая размерность, масштабность алгоритмов, несбалансированность входных данных, раздробленность и низкая структурированность данных, отсутствие индексации данных, и задачи быстрого получения информации. Следовательно, инновационный решения в сфере анализа и управления данными оправданы при работе с большими данными. Возможности глубинного обучения по получению высокоуровневых, сложных абстракций и представлений данных из больших объемов данных, особенно слабо структурированных, делают его привлекательным методом для анализа больших данных. К примеру, процессы семантического индексирования, маркировки данных, быстрых алгоритмов поиска информации и дискриминантного моделирования могут быть ускорены при помощи глубинного обучения. Более традиционные алгоритмы машинного обучения и проектирования признаков недостаточно эффективны для получения сложных нелинейных трансформаций, которые чаще всего наблюдаются в Больших данных. Получив такие признаки можно использовать более простые линейные модели для анализа больших данных таких как, классификация и предсказание, что очень важно при разработке моделей для работы с объемами больших данных. Новизна этого исследования в том, что она исследует применения алгоритмов глубинного обучения для ключевых проблем в анализе больших данных, продвигая дальше целевые исследования экспертов в этих двух сферах.
Основной идеей в алгоритмах глубинного обучения является автоматизация извлечения представлений и абстракций из данных. Эти алгоритмы используют огромные объемы слабо структурированных данных для автоматического извлечения сложных представлений. Свои корни алгоритмы берут из области искусственного интеллекта, основной целью которого является эмулирование способностей человеческого мозга, таких как, наблюдение, анализ, обучение и принятие решений, особенно для сверхсложных задач. Работа по эмуляции в отношении этих комплексных иерархических подходов человеческого мозга и есть основная сфера исследований в области глубинного обучения. Модели, основанные на поверхностных способах обучения таких как деревья принятия решений, векторные машины принятия решения, и логика на основе прецедентов могут привести к худшим результатам при поиске нужной информации из сложных структур. В тоже время глубинное обучение имеет возможности обобщать нелокальные и глобальные способы, создавая схемы обучения и представления, заходящие дальше ближайших соседей в данных. Поэтому глубинное обучение — это важный шаг в развитии искусственного интеллекта. Он позволяет создавать машины, не зависящие от влияния человека в постоянном режиме, что по сути своей и есть цель искусственного интеллекта.
Основным принципом методов глубинного обучения является распределенные представления данных, в которых больше количество различных вероятных сочетаний абстрактных признаков входных данных. Это позволяет иметь компактное представления для каждого типа и приводит к большему обобщению. Количество возможных сочетаний экспоненциально зависит от числа полученных признаков. Принимая во внимание что просматриваемые данные были получены от взаимодействия неких известных и неизвестных признаков, дополнительные представления данных могут быть получены через сочетания известных признаков. Если проводить сравнение с локальным обобщением, количество сочетаний, которые могут быть получены с помощью распределенных представлений, быстро возрастает с количеством известных признаков. Алгоритмы глубинного обучения приводят к более абстрактным представлениям, потому что они часто основаны на менее абстрактных представлениях. Что важно, чем более абстрактным будет представление, тем менее оно зависит от локальных изменений. Реальные данные используемые в задачах для искусственного интеллекта в основном берутся из сочетаний различных источников. К примеру изображение состоит из множества разных источников данных таких как свет, форма объекта, его составляющие и т. д.
Алгоритмы глубинного обучения имеют многослойную архитектуру, где каждый слой применяет нелинейную трансформацию на входные данные и передает представление на выходе. Конечной целью является получение сложного, абстрактного представления данных в иерархическом виде в результате прохождения этих данных через множество слоев трансформации. Полученные сенсором данные подаются на первый слой, который передает свой результат следующему и так далее. Расположение нелинейных слоев трансформации в последовательности является основой в алгоритмах глубинного изучения. Чем больше слоев проходят данные в глубину, тем более сложные нелинейные трансформации строятся. Эти трансформации представляют собой данные, поэтому глубинное обучение может быть рассмотрено как особый случай алгоритмов обучения представлений. Полученное финальное представление данных будет высшей нелинейной функцией входных данных.
Важно отметить что эти трансформации в слоях глубинной архитектуры являются нелинейными трансформациями, которые пытаются получить лежащие в основе объясняющие признаки данных. Нельзя использовать линейную трансформацию такую как метод главных компонент в глубинных слоях, потому что композиции линейных трансформаций содержат в себе еще одну линейную трансформацию. Поэтому не будет смысла в глубинной архитектуре. К примеру, при передаче нескольких фотографий лица в алгоритм глубинного обучения, первый слой можно обучить понимать разнонаправленные края, во втором слое можно создать композицию из краев, чтобы обучиться более сложным признакам, таким как часть губ, носа или глаз. В третьем слое алгоритм собирает эти признаки чтобы обучиться еще более сложным признакам, как к примеру, тип овала лица. Эти финальные представления можно использовать в качестве признаков в приложениях распознавания лиц. Этот пример показывает, как глубокий алгоритм изучения находит более абстрактные и сложные представления данных, составляя представления, полученные в иерархической архитектуре. Однако нужно считать, что алгоритмы глубинного обучения не обязательно пытаются создать предопределенную последовательность представлений на каждом уровне (таких как края, глаза, поверхности), но вместо этого более широко выполнить нелинейные преобразования в различных уровнях. Эти преобразования имеют тенденцию распутывать признаки изменений в данных. Перевод этого понятия к надлежащим учебным критериям является еще одним из основных нерешенных вопросов в алгоритмах глубинного обучения.
Заключительное представление данных, созданных алгоритмами глубинного обучения (вывод заключительного уровня), предоставляет полезную информацию из данных, которые могут использоваться в качестве функций в создании классификаторов, или могут использоваться для индексации данных и других приложений, которые более эффективны при использовании абстрактных представлений данных, а не высоких размерных сенсорных данных.
Изучение параметров в глубокой архитектуре является трудной задачей оптимизации, такой как изучение параметров в нейронных сетях со многими скрытыми уровнями. В 2006 Хинтон предложил изучить глубокую архитектуру неконтролируемым жадным методом в разрезе обучения слоев. Вначале сенсорные данные подаются как изучение данных к первому уровню. Когда первый уровень обучен на основе этих данных, и вывод первого уровня (первый уровень изученных представлений) передается как данные на изучение второму уровню. Такие итерации повторяются, пока желаемое число уровней не получено. Так строится процесс обучения глубокой сети. Представления, изученные на последнем уровне, могут использоваться для различных задач. Если это задача классификации, дополнительный контролируемый уровень помещается поверх последнего уровня. В итоге вся сеть подстраивается под управляемые данные для последнего слоя.
В основном используются два фундаментальных блока — неконтролируемые одноуровневые алгоритмы обучения, которые используются, чтобы создать более глубокие модели: автоассоциаторы и Ограниченные машины Больцмана (RBMs). Они часто используются в тандеме, чтобы создать последовательности автоассоциаторы и глубокие сети доверия. Автоассоциаторы являются сетями, созданными из 3 уровней: ввод, скрытый уровень и вывод. Автоассоциаторы пытаются изучить некоторые представления ввода в скрытом уровне таким способом, который позволяет восстановить ввод в выходном уровне на основе этих промежуточных представлений. Таким образом целевой вывод — сам ввод. В основном автоассоциатор изучает свои параметры, минимизируя ошибку реконструкции. Эта минимизация обычно делается стохастическим спуском градиента. Если скрытый уровень будет линеен, и среднеквадратическая ошибка используется в качестве критерия реконструкции, то автоассоциатор изучит первые k ключевых компонентов данных. Альтернативные стратегии предлагаются, чтобы сделать автоассоциаторы нелинейными. Это необходимо для создания глубоких сетей, а также для извлечения значимые представления данных.
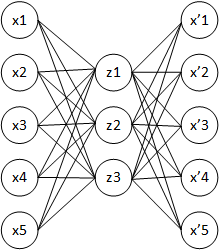
Рис. 2. Автоассоциатор
Другой неконтролируемый одноуровневый алгоритм изучения, который используется в качестве стандартного блока в построении глубокой сети доверия, является Ограниченной машиной Больцмана (RBM). Они содержат один видимый уровень и один скрытый уровень. Однако у них есть ограничение — нет никакого взаимодействия между модулями одного уровня, и соединения устанавливаются исключительно между модулями от различных уровней. Сравнительный алгоритм Расхождения часто используется для обучения машин Больцмана.
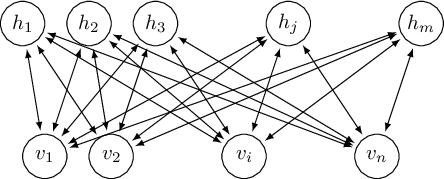
Рис. 3. Ограниченная машина Больцмана
Алгоритмы глубинного обучения извлекает значимые абстрактные представления необработанных данных с помощью иерархического многоуровневого подхода изучения, где в более высоком уровне более абстрактные и сложные представления изучены на основе менее абстрактных понятий и представлений на более низком уровне (уровнях) иерархии изучения. В то время как глубинное обучение может быть применено для изучения маркированных данных, если они доступны в достаточно больших объемах, прежде всего они интересны для приобретения знаний из больших сумм некаталогизированных данных, что делает их привлекательными для извлечения значимых представлений и образцов из «Больших Данных».
Когда иерархические абстракции данных получены из некаталогизированных данных с помощью глубинного обучения, стандартные отличительные модели могут быть обучены при помощи, относительно меньшего объема каталогизированных точек ввода данных, где маркированные данные обычно получаются посредством человеческого ввода. Алгоритмы глубинного обучения, выполняются лучше при извлечении нелокальных и глобальных отношений и образцов в данных, по сравнению с относительно мелкой архитектурой обучения. Другие полезные характеристики изученных абстрактных представлений глубинного обучения включают:
- относительно простые линейные модели могут работать эффективно со знанием, полученным из представлений более сложных и более абстрактных данных;
- увеличенная автоматизация получения представления данных от некаталогизированных данных может применяться к различным типам данных, таким как изображение, структурное, аудио, и т. д.;
- реляционное и семантическое знание может быть получено в более высоких уровнях абстракции и представлении необработанных данных.
Существуют и другие полезные аспекты представлений данных основанных на глубинном обучении, но для анализа «Больших данных» они не так важны.
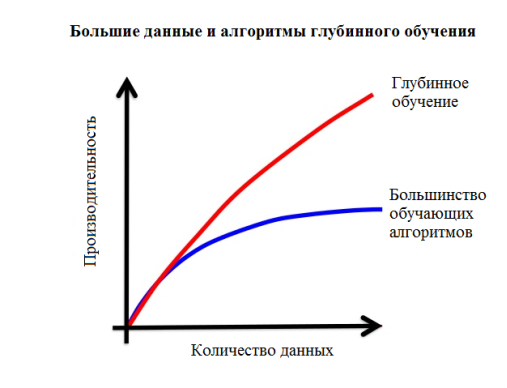
Рис. 4. Сопоставление алгоритмов
Рассматривая основные характеристики «Больших данных», т. е., объем, Разнообразие, Скорость и Достоверность, алгоритмы и архитектуры глубинного обучения более точно подходят к решению проблем, связанных с объемом и разнообразием анализа «Больших данных». Глубинное обучение по сути использует доступность крупных объемов данных, т. е. объем в «Больших Данных», где алгоритмам с мелкими иерархиями обучения не удается исследовать и понять высокую сложность образцов данных. Алгоритмы глубинного обучения работают с абстракцией данных и представлениями, что больше подходит для анализа необработанных данных, представленных в различных форматах и из других источников, т. е. в разнообразии «Больших Данных», и может минимизировать потребность во вводе от экспертов-людей для получения признаков из каждого нового типа данных, наблюдаемого в «Больших Данных». Анализ «Больших Данных» представляет возможность для разработки новых алгоритмов и моделей для решения конкретных проблем связанных с «Большими Данными». Понятия глубинного обучения обеспечивают одно из таких решений для экспертов по аналитике данных. Например, извлеченные представления можно рассмотреть, как практический источник знания для принятия решений, семантической индексации, информационного поиска, и для других целей в анализе «Больших Данных.
Литература:
- Minmin Chen. Marginalized Denoising Autoencoders for Domain Adaptation // Computer Science. — 2012. — №. — С. 8..
- Geoffrey Hinton, Ruslan Salakhutdinov. Discovering Binary Codes for Documents by Learning Deep Generative Models // Topics in Cognitive Science. — 2010. — № 1–18. — С. 18.
- Vector Representations of Words. // TensorFlow. URL: https://www.tensorflow.org/versions/r0.9/tutorials/word2vec/index.html (дата обращения: 15.01.2017).
- Guanyu Zhou, Kihyuk Sohn, Honglak Lee. Online Incremental Feature Learning with Denoising Autoencoders // Proceedings of Machine Learning Research. — La Palma: MLR press, 2012. — С. 1453–1461..
