Обнаружение вторжений изучается в течение последних 20 лет. Вторжение — это деятельность, которая нарушает политику безопасности информационной системы [1]. Обнаружение вторжений основано на предположении, что поведение нарушителя будет существенно отличаться от нормального поведения, что обеспечит обнаружение большого количества несанкционированных действий.
Системы обнаружения вторжений обычно используются совместно с другими системами защиты, такими как контроль доступа и аутентификации в качестве дополнительной защиты информационных систем [2]. Есть много причин, которые делают обнаружение вторжений важной частью во всей системе защиты. Во-первых, многие из существующих систем и приложений, были разработаны и построены без учета требований безопасности. Во-вторых, компьютерные системы и приложения могут иметь недостатки или ошибки в их конфигурации, которые могут быть использованы злоумышленники для атаки систем или приложений. Таким образом, профилактический метод не может быть столь же эффективным, как и ожидалось.
Системы обнаружения вторжений можно разделить на два класса: системы обнаружения сигнатур и системы обнаружения аномалий. Система обнаружения сигнатур идентифицирует шаблоны трафика данных или приложений которые считаются вредоносными, в то время как системы обнаружения аномалий и сравнивают деятельность с нормальным поведением.
Согласно [3], [4] все методы обнаружения аномалий состоят из следующих основных модулей или этапов (рис. 1). Эти этапы параметризация, обучение и обнаружение. Параметризация включает в себя сбор исходных данных из контролируемой среды. Исходные данные должны быть типичными для системы, которая должна быть смоделирована, (например, данные пакета из сети). Этап обучения моделирует систему с помощью ручных или автоматических методов. Для архитектуры клиент-сервер, сервер является хост, который ожидает входящее соединение. Когда соединение устанавливается между клиентом и сервером, то сервер подтверждает сокет, который будет использоваться для создания экземпляра. Объект обработчика, который работает на отдельном потоке. Эти обработчики будут храниться в объекте коллекции.
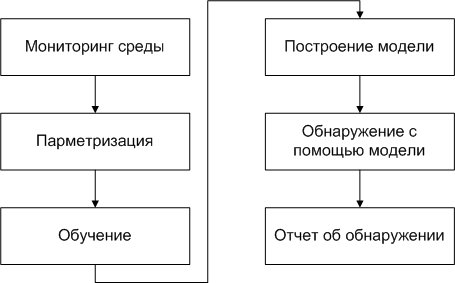
Рис. 1. Общая схема обнаружения аномалий
Этапы, представленные в модели, будут отличаться в зависимости от используемого метода. При обнаружении сравнивается система, созданная на этапе моделирования, с выбранным параметризованным блоком данных. Пороговые критерии будут выбраны для определения аномального поведения [4].
Машинное обучение может построить необходимую модель автоматически на основе некоторых обучающих данных. Применение такого подхода нуждается в наличии необходимой подготовки данных, но эта задача является менее сложной по сравнению с вычислением аномальной модели [5]. С увеличением сложности и количества различных атак, методы машинного обучения, которые позволяют создавать и поддерживать системы обнаружения аномалий (ADS) с меньшим вмешательством человека является единственным практическим подходом для создания следующего поколения систем обнаружения вторжений.
Применение методов машинного обучения для обнаружения вторжений позволит автоматически построить модель, основанную на наборе обучающих данных, которая содержит экземпляры данных, описанных с помощью набора атрибутов (признаков). Атрибуты могут быть различных типов, например качественными или количественными.
Были рассмотрены различные алгоритмы обнаружения аномалий, в таблице 1 представлены плюсы и минусы каждого из них.
Обнаружение аномалий включает в себя контролируемые и неконтролируемые методы. Сравнительный анализ показал, что контролируемые методы обучения значительно превосходят неконтролируемые, если тестовые данные не содержит неизвестных атак. Среди контролируемых методов, наилучшая производительность достигается за счет нелинейных методов, таких как SVM, многослойный персептрон и методов, основанных на правилах. Неконтролируемые методы, такие как K-средних, SOM, и один класс SVM показывают более высокую производительность по сравнению с другими методами, хотя они различаются по эффективности обнаружения всех классов атак.
|
Методы |
Плюсы |
Минусы |
|
K — ближайших соседей |
|
|
|
Нейронная сеть |
|
|
|
Дерево решений |
|
|
|
Машина опорных векторов |
|
|
|
Самоорганизующиеся карты |
|
|
|
K-средних |
|
|
|
Алгоритм нечёткой кластеризации Fuzzy C-means |
|
|
|
Аппроксимация |
|
|
Анализ показал, что контролируемые методы обучения значительно превосходят неконтролируемые, если исследуемые данные не содержит неизвестных атак. Среди контролируемых методов, наилучшая производительность достигается за счет нелинейных методов, таких как SVM, многослойный персептрон и методов основанных на правилах. Неконтролируемые методы, такие как K-средних, SOM, и один класс SVM показывают более высокую производительность по сравнению с другими методами, хотя они показывают различную эффективность обнаружения всех классов атак.
Литература:
- Никишова А. В. Интеллектуальная система обнаружения атак на основе многоагентного подхода // Вестник Волгоградского государственного университета. Серия 10. Инновационная деятельность.. — 2011. — № 5. — С. 35–37.
- Аткина В. С. Оценка эффективности катастрофоустойчивых решений // Вестник Волгоградского государственного университета. Серия 10. Инновационная деятельность.. — 2012. — № 6. — С. 45–48.
- Estevez J., Garcya P., Dyaz J. «Anomaly detection methods in wired networks: a survey and taxonomy». Computer Networks, том.27 — №.16. — 2004. — С. 1569–84.
- Garcıa T., Dıaz V., Macia F., Vazquezb. «Anomaly-based network intrusion detection». Computers and security, том 28. — 2009. — С. 18 –28.
- Omar S., Ngadi A., Jebur H. «Machine Learning Techniques for Anomaly Detection: An Overview». International Journal of Computer Applications, том 79. — № 2.— 2013 — С. 33–41.

