





Метод автоматизированного анализа электронных документов в формате XML
Белорусов Артем Игоревич, младший научный сотрудник
Институт вычислительного моделирования СО РАН (г. Красноярск)
Введение
Повсеместное распространение сети Интернет способствует организации межсистемного взаимодействия, которое заключается в обмене информационными документами заданного формата по определенному протоколу. На транспортном уровне используется самый распространенный протокол HTTP(S). На его основе функционируют веб-сервисы, созданные для программного взаимодействия между гетерогенными информационными системами, независимо от платформы [2, 3]. На нижнем уровне взаимодействия находятся данные. Наиболее распространенный формат данных для межсистемного взаимодействия XML [1].
Анализ электронных документов в формате XML – трудоемкая задача. Необходимо автоматизировать процесс извлечения данных из документов в формате XML и их размещение в реляционной базе данных с целью обеспечения непрерывности цикла межсистемного информационного обмена и снижения трудозатрат на поддержку механизмов межсистемной интеграции.
В статье предлагается подход к автоматизированному анализу структуры XML-документов, извлечению данных и их сохранению в соответствующие таблицы реляционной базы данных, основанный на использовании метафайлов с описанием соответствия между структурой XML-документов и таблиц базы данных.
Задачи анализа XML документов
Электронные документы в формате XML представляют собой древовидную иерархическую структуру, основанную на отношениях родитель–потомок. В документе всегда присутствует корень – верхний элемент иерархии. Все остальные элементы – его потомки. Концевые узлы дерева содержат значения параметров документа. Пример XML-документа приведен в таблице 1.
В этом примере узел contract является корневым узлом XML-дерева. Узлы id, regnum и пр. являются потомками узла contract и содержат значения. Потомки foundation и customer являются потомками корневого узла и родителями для узлов, расположенных ниже по иерархии.
Таблица 1
Фрагмент документа в формате XML
|
|
В силу того, что информационное взаимодействие осуществляется путем обмена электронными документами в формате XML, решается задача анализа их структуры и содержания. Процедура анализа, как правило, сводится к выделению определенных объектов в структуре электронных документов, заполнению их данными и сохранению в реляционную базу данных. Проблема состоит в том, что типов документов много, структура у них разная, и для каждого нужно писать свою отдельную функцию анализа структуры и содержания. Процесс анализа XML-документов различных типов и сохранения данных в базу данных изображен на рис. 1.
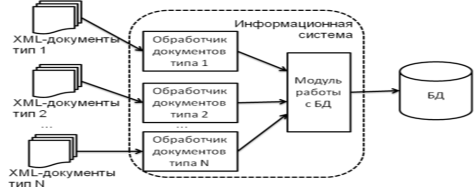
Рис. 1. Процесс обработки XML документов различных типов
Для каждого входящего типа XML-документов необходимо реализовать функцию анализа, которая приводила бы данные из электронного документа к структуре соответствующей таблицы и сохраняла бы их в базу данных. У такого подхода есть ряд очевидных недостатков:
– количество функций растет пропорционально количеству различных типов входящих документов;
– при изменении структуры входящих документов, либо структуры таблиц базы данных, тело функций необходимо менять;
– при добавлении в систему функции обработки нового типа XML-документов, или после внесения изменений в уже существующие функции, всю систему необходимо перекомпилировать и обновить.
Предлагаемое решение
С целью минимизации трудозатрат на организации межсистемного взаимодействия предлагается метод автоматизации анализа структуры XML-документов и сохранения данных в соответствующие таблицы реляционной базы данных (рис. 2).
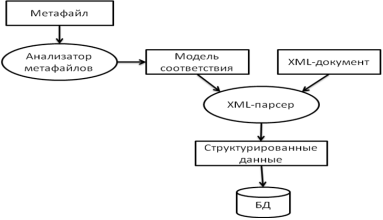
Рис. 2. Схема предлагаемого метода анализа XML-документов
Суть метода состоит в следующем:
- Для каждого типа XML-документов создается метафайл, в котором описывается отображение узлов документа в соответствующие таблицы и поля реляционной базы данных;
- Для анализа метафайлов создается специальный парсер, который выдает модель проанализированного документа, содержащую структурные паттерны XML-дерева и инструкции по их сохранению в реляционную базу данных;
3.Полученная на предыдущем этапе модель подается на вход анализатора вместе с анализируемым входящим XML-документом. В процессе анализа в этом документе распознаются структурные паттерны и в соответствии с инструкциями сохраняются в реляционную базу данных.
При таком подходе вся функциональная нагрузка ложится на 2 блока – анализатор метафайлов и XML-парсер. При изменении структуры входящих электронных документов или изменении структуры базы данных достаточно внести соответствующие изменения в метафайлы, – отпадает необходимость «горячего программирования» и последующего обновления программного обеспечения.
Реализация
Для реализации предложенного мнтода разработаны программные модули, выполняющие автоматизированную обработку электронных документов в формате XML с функцией сохранения данных в реляционную базу данных. Метафайлы выполнены в формате XML, что дает возможность работать с ними с помощью любого текстового редактора. Еще одним плюсом в пользу формата XML является большое количество программных средств автоматизированной обработки файлов этого формата.
Метафайлы необходимы для определения соответствия между узлами XML-документов и таблицами реляционной базы данных, они имеют иерархическую структуру, общий вид приведен в таблице 2.
Таблица 2
Структура метафайлов
|
|
Корнем метафайла является узел tables, который содержит в себе описание всех таблиц реляционной базы данных и соответствующих им узлов электронного документа. В описании каждой таблицы (table) присутствует список узлов (tags), значения которых должны быть помещены в соответствующие поля таблицы, и список потомков (childs), которые являются таблицами базы данных, связанными с текущей таблицей с помощью внешних ключей (foreign keys). Кроме этого в описании каждой таблицы могут присутствовать блоки с SQL запросами, которые необходимо выполнить перед или после вставки в таблицу новых значений (after insert, before insert).
В качестве наглядного примера рассмотрим задачу анализа данных о план-графиках закупок (ПГЗ), предоставляемых Единой информационной системой (ЕИС, www.zakupki.gov.ru).
Для получения номеров строк ПГЗ из ЕИС создан метафайл с описанием структуры анализируемых XML-файлов и соответствующих им таблиц базы данных (таблица 3).
Таблица 3
Метафайл с описанием план-графика закупок
|
|
В представленном примере в метафайле сначала описывается таблица для хранения информации о план-графиках OOS_PG_tenderPlan, у которой заданы следующие свойства:
– path="tenderPlan " – указан путь к корневому узлу в электронном документе;
– main="true" – служебный признак таблицы;
– required="true" – признак обязательного присутствия узла в электронном документе;
– type="catalog" – тип таблицы;
– schemeVersion="5.2" – служебный признак, задающий версию схем данных XML-документов.
С помощью узлов-потомков, принадлежащих тегу tags, задаются поля таблицы и соответствующие им узлы электронных документов. Например:
После определения полей-свойств таблицы идет раздел childs, в котором задаются зависимые таблицы, связанные с основной с помощью внешних ключей.
Например:
Как было указано выше, файл с метаописанием попадает на вход специального анализатора, в котором заданы процедуры обработки данных файлов. В результате своей работы анализатор формирует список объектов. Каждый объект хранит в себе описание таблицы реляционной базы данных в формате {свойство: значение}, которое представляет собой информационную модель соответствия таблиц реляционной базы данных узлам электронных документов в формате XML.
Последовательно анализируя информационную модель, полученную на предыдущем этапе, парсер ищет паттерны, определенные в метафайлах, в узлах электронных документов. Модель заполняется данными, содержащимися в узлах, образуя деревья связанных между собой объектов, образующих структуру таблиц базы данных (рис. 3).

Рис. 3. Схема извлечения данных план-графиков из XML-документов
Заполненное на предыдущем этапе дерево размещается в таблицы БД. Начиная с корневого элемента, заполненные объекты сохраняются в соответствующую таблицу, после чего происходит сохранение всех зависимых таблиц-потомков, записи которых будут ссылаться на родительскую с помощью внешнего ключа (foreignKey) (рис. 4).

Рис. 4. Размещение данных план-графиков в соответствующие таблицы базы данных
Заключение
Описанный метод автоматизированного анализа информационных документов в формате XML позволяет с помощью метафайлов извлекать данные из документов и размещать их в соответствующие таблицы реляционной базы данных.
Описанные механизмы автоматизированного анализа структуры XML-документов и сохранения данных в соответствующие таблицы реляционной базы данных интегрированы с автоматизированной информационной системой поддержки муниципального заказа, функционирующей в департаменте муниципального заказа администрации г. Красноярска [4]. Механизмы апробированы на XML-документах следующих типов: план-график закупок; информация о заключенных контрактах; реквизиты заказчиков. За полгода с помощью реализованного подхода обработано более 100 000 документов.
Предложенный подход позволяет значительно сократить трудозатраты при внесении изменений в структуру входящих документов или таблиц базы данных, а также при добавлении новых типов обрабатываемых XML-документов.
Литература:
- Tekli Joe, Chbeir Richard, Yetongnon Kokou. An overview on XML similarity: Background, current trends and future directions // Computer Science Review. – 2009. – Vol. 3, Issue 3. – P. 151–173.
- Jiří Dědič. Advanced Topics on System Integration (Ph.D.) // Jiří Dědič. – Masaryk University, Brno. – 2005. – 108 p.
- Хохгуртль Брайан. С# и Java: межплатформные Web-сервисы // Брайан Хохгуртль. – М.: Связь, 2004. – 213 с.
- Белорусов А.И. Интеграция информационных систем на основе стандартов XML и WEB-сервисов в сфере закупок // Молодой ученый. – 2015. – № 11. – С. 9–15.
