





Ключевые слова: классификация, деревья принятия решений, отсутствующие значения, веса параметров, C4.5.
Деревья принятия решений применяются во многих сферах деятельности. Одним из главных направлений их использования является решение задач классификации [1]. C4.5 —алгоритм построениядеревьев решений, разработанный Джоном Квинланом [2]. C4.5 является усовершенствованной версиейалгоритма ID3, который также был разработан Квинланом [3]. В версию C4.5 были добавлены возможность отсечения ветвей деревьев, возможность работы с числовыми атрибутами, а также возможность построения дерева на основе выборки с отсутствующими значениями атрибутов [4]. Основная причина, по которой C4.5 применен в данном исследовании — его умение успешно работать при отсутствующих значениях атрибутов в выборке. Часто при прогнозировании или классификации возникает необходимость предварительно выбирать, какие из параметров следует включать в выборки данных и в какой форме это делать. В этой статье рассматривается решение задачи подбора параметров для выборки с целью формирования наиболее подходящих, с точки зрения эффективности классификации, выборок данных. Далее рассматривается метод определения, распределения весов входящих параметров с применением возможностей алгоритма C4.5.
Существует несколько подходов к решению проблемы прогнозирования при отсутствующих значениях в наборах входящих данных [5]. Самый простой подход состоит в игнорировании случаев с любыми пропущенными значениями. Такой подход уменьшает выборку и, следовательно, не является приемлемым в случае наличия высокой доли недостающих значений.
Другой распространенный подход заключается в замене отсутствующих значений глобальным или соответствующим одному классу средним или наиболее часто встречающимся значением, но при этом не задействованы возможные зависимости недостающего атрибута от других атрибутов. Создатель алгоритма С4.5 Р. Квинлан установил [6], что выделив случаи с пропущенными значениями среди подмножеств при разбиении обучающей выборки в дереве решений, и объединив все возможные результаты на тестовом примере с отсутствующими значениями во время классификации, можно добиться большей точности классификации, чем при использовании других вариантов процесса обучения дерева решений. В C4.5 применяется такой вероятностный подход для обработки отсутствующих значений и в обучающих, и в тестовых выборках данных.
В данной работе рассматривается случай, когда все значения выходных параметров, в обучающей и в тестовой выборках данных для прогнозирования, являются дискретными величинами, а не непрерывными. Значения атрибутов на входе при этом могут быть как дискретными, так и непрерывными.
В классическом случае применения дерева принятия решений для прогнозирования, в тестовой выборке отсутствующими значениями являются значения классов — выходных параметров [7]. Назовем такой параметр ![]() , где i соответствует порядковому номеру набора атрибутов
, где i соответствует порядковому номеру набора атрибутов ![]() , а j — количеству атрибутов в каждом из наборов
, а j — количеству атрибутов в каждом из наборов ![]() ={
={![]() ;
;![]() ;
;![]() ;…;
;…;![]() } на входе в выборке данных. Значения всех атрибутов
} на входе в выборке данных. Значения всех атрибутов ![]() и
и ![]() в выборке могут повторяться. Задача прогнозирования, в данном случае, сводится к классификации таких наборов
в выборке могут повторяться. Задача прогнозирования, в данном случае, сводится к классификации таких наборов ![]() при неизвестных значениях
при неизвестных значениях ![]() . Для распределения наборов атрибутов необходимо сперва указать возможные значения классов, а также выработать соответственные правила классификации, что и выполняется с помощью предварительного обучения алгоритма построения дерева принятия решений на основе данных из обучающей выборки [8].
. Для распределения наборов атрибутов необходимо сперва указать возможные значения классов, а также выработать соответственные правила классификации, что и выполняется с помощью предварительного обучения алгоритма построения дерева принятия решений на основе данных из обучающей выборки [8].
Однако влияние значений отдельных атрибутов ![]() на выбор того или иного значения класса
на выбор того или иного значения класса ![]() неочевидно. Расчет же значений энтропии [9] не всегда позволяет определить влияние на результат классификации отдельных подмножеств параметров из множества
неочевидно. Расчет же значений энтропии [9] не всегда позволяет определить влияние на результат классификации отдельных подмножеств параметров из множества ![]() всех доступных параметров.
всех доступных параметров.
Представим структуру данных в обучающей выборке в следующем виде:
![]() ,
, ![]() ,
, ![]() , …,
, …, ![]() |
| ![]()
…
![]() ,
, ![]() ,
, ![]() , …,
, …, ![]() |
| ![]() .
.
Выполним классификацию на тестовой выборке при тех же входных параметрах для получения спрогнозированного значения выходного параметра:
![]() ,
, ![]() ,
, ![]() , …,
, …, ![]() | ?
| ?
![]() ,
, ![]() ,
, ![]() , …,
, …, ![]() |?
|?
…
![]() ,
, ![]() ,
, ![]() , …,
, …, ![]() |?,
|?,
где знак вопроса «?» обозначает неизвестное значение атрибута.
Для того чтобы выявить ключевые атрибуты, от изменений значений которых зависит результат классификации, поочередно заменим каждый из них во всех наборах атрибутов в выборке указателем неизвестного значения.
Тестовая выборка в начале цикла поиска ключевых параметров будет выглядеть следующим образом:
?,
?, ![]() ,
, ![]() , …,
, …, ![]() |?
|?
…
?, ![]() ,
, ![]() , …,
, …, ![]() |?.
|?.
С каждой итерацией неизвестное значение «?» будет замещать следующий атрибут ![]() на интервале от
на интервале от ![]() до
до ![]() для j от 1 до
для j от 1 до ![]() , где
, где ![]() — количество атрибутов в каждом из наборов выборки, i от 1 до
— количество атрибутов в каждом из наборов выборки, i от 1 до ![]() , где
, где ![]() — общий размер тестовой выборки. Всего необходимо выполнить j итераций.
— общий размер тестовой выборки. Всего необходимо выполнить j итераций.
Так на последней итерации получим:
![]() ,
, ![]() ,
, ![]() , …, ? | ?
, …, ? | ?
![]() ,
, ![]() ,
, ![]() , …, ? |?
, …, ? |?
…
![]() ,
, ![]() ,
, ![]() , …, ? |?.
, …, ? |?.
На каждой итерации проводится сравнение результатов классификации — значений ![]() для одного и того же набора атрибутов из тестовой выборки без отсутствующих значений входящих данных и из тестовой с отсутствующим значением. Если при замене только одного из атрибутов
для одного и того же набора атрибутов из тестовой выборки без отсутствующих значений входящих данных и из тестовой с отсутствующим значением. Если при замене только одного из атрибутов ![]() значение
значение ![]() отличается от соответствующего ему, спрогнозированного ранее в тестовой выборке, то это будет означать, что параметр, который имеет наибольший вес в отдельном наборе входных и выходных параметров, найден.
отличается от соответствующего ему, спрогнозированного ранее в тестовой выборке, то это будет означать, что параметр, который имеет наибольший вес в отдельном наборе входных и выходных параметров, найден.
В пределах одного и того же значения класса c определение ключевого для него атрибута
При этом может возникнуть ситуация, когда сразу несколько параметров в одном и том же наборе, при замещении их в выборке указателями неизвестного значения, вызывают изменение результата классификации. Или же есть необходимость провести дальнейшее распределение весов оставшихся атрибутов. В таком случае нужно проверять влияние не каждого атрибута по отдельности, а всех возможных комбинаций атрибутов. Рассмотрим теперь влияние подмножеств параметров, взятых из наборов данных ![]() .
.
Например, комбинации из 2-ух неизвестных значений атрибутов:
?,?, ![]() , …,
, …, ![]() | ?
| ?
?, ?, ![]() , …,
, …, ![]() |?
|?
…
?, ?, ![]() , …,
, …, ![]() |?.
|?.
Вес отдельных атрибутов ![]() в наборах будет определяться как соотношение количества подмножеств, в которых присутствует атрибут, вызвавших изменение результата классификации при замене значений указателями «?», к общему количеству атрибутов во всех таких подмножествах.
в наборах будет определяться как соотношение количества подмножеств, в которых присутствует атрибут, вызвавших изменение результата классификации при замене значений указателями «?», к общему количеству атрибутов во всех таких подмножествах.
Распределение весов атрибутов ![]() в пределах одного значения класса c выполняется с помощью подсчета суммы рассчитанных, как указано выше, весов атрибутов
в пределах одного значения класса c выполняется с помощью подсчета суммы рассчитанных, как указано выше, весов атрибутов ![]() , находящихся на одной и той же позиции j, из разных наборов
, находящихся на одной и той же позиции j, из разных наборов ![]() .
.
Алгоритм:
-
Обучение C4.5 с обучающей выборкой данных. Все значения параметров на входе
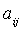 и выходе
и выходе 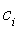 в обучающей выборке известны.
в обучающей выборке известны.
-
Классификация C4.5 с тестовой выборкой. Значения параметров на выходе
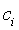 в тестовой выборке заменены указателями неизвестного значения «?».
в тестовой выборке заменены указателями неизвестного значения «?».
-
Поиск ключевых атрибутов — классификацияC4.5 с тестовой выборкой с отсутствующими значениями атрибутов . Количество итераций равно количеству атрибутов j в наборе на входе
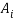 . На каждой итерации один из атрибутов
. На каждой итерации один из атрибутов 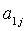 во всех наборах
во всех наборах 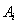 заменяется указателем неизвестного значения «?». Полученные в результате классификации значения сравниваются с соответствующими значениями из п. 2. Если при замене только одного из атрибутов из набора
заменяется указателем неизвестного значения «?». Полученные в результате классификации значения сравниваются с соответствующими значениями из п. 2. Если при замене только одного из атрибутов из набора 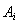 значения не совпали, а замена остальных атрибутов не вызывает изменения результата классификации, то ключевой атрибут для набора входных и выходных параметров найден. Для выбранного значения класса c веса, найденных на одной и той же позиции j в разных наборах , ключевых атрибутов
значения не совпали, а замена остальных атрибутов не вызывает изменения результата классификации, то ключевой атрибут для набора входных и выходных параметров найден. Для выбранного значения класса c веса, найденных на одной и той же позиции j в разных наборах , ключевых атрибутов 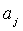 распределяются согласно количеству таких наборов.
распределяются согласно количеству таких наборов.
Распределение весов оставшихся атрибутов, не рассмотренных в п. 3 — классификацияC4.5 с тестовой выборкой с отсутствующими значениями комбинаций атрибутов ![]() . Вычисления проводятся отдельно для каждого набора
. Вычисления проводятся отдельно для каждого набора ![]() . Количество итераций для каждого набора
. Количество итераций для каждого набора ![]() равно сумме чисел сочетаний
равно сумме чисел сочетаний ![]() без повторений из j-1 атрибутов по k=2…j-1. При чем j-1 вместоj используется только в случае найденного в п. 3 ключевого атрибута
без повторений из j-1 атрибутов по k=2…j-1. При чем j-1 вместоj используется только в случае найденного в п. 3 ключевого атрибута ![]() для набора
для набора ![]() . Поочередно выполняется перебор всех возможных сочетаний
. Поочередно выполняется перебор всех возможных сочетаний ![]() без повторений параметров
без повторений параметров ![]() (кроме ключевого из п. 3) из набора
(кроме ключевого из п. 3) из набора ![]() с указателями неизвестного значения «?» вместо значений параметров
с указателями неизвестного значения «?» вместо значений параметров ![]() в сочетаниях. Учитываются только те сочетания
в сочетаниях. Учитываются только те сочетания ![]() , при которых результат классификации
, при которых результат классификации ![]() набора
набора ![]() не совпал с результатом в п. 2. Вес выбранного атрибута
не совпал с результатом в п. 2. Вес выбранного атрибута ![]() рассчитывается как соотношение числа таких сочетаний с этим атрибутом к общему количеству элементов в таких сочетаниях с выбранным атрибутом
рассчитывается как соотношение числа таких сочетаний с этим атрибутом к общему количеству элементов в таких сочетаниях с выбранным атрибутом ![]() . Для выбранного значения класса c веса атрибутов
. Для выбранного значения класса c веса атрибутов ![]() на одной и той же позиции j в разных наборах
на одной и той же позиции j в разных наборах ![]() определяются как сумма их весов в этих наборах
определяются как сумма их весов в этих наборах ![]() .
.
Разработанный метод позволяет определить ключевые для выбора того или иного класса атрибуты, а также распределять веса остальных входящих параметров. Реализация метода может быть выполнена без каких-либо громоздких надстроек с применением сторонних методов, используя только возможности хорошо изученного алгоритма С4.5. Данный метод также, без существенных изменений, можно адаптировать и для обновленной версии алгоритма построения деревьев принятия решений С5.0 [10]. Результаты, полученные с помощью данного метода, смогут найти применение в качестве предварительной обработки данных для построения более эффективных моделей прогнозирования, где так или иначе необходимо учитывать влияние каждого из всех доступных параметров в выборках.
Литература:
- Lior Rokach, Oded Maimon. Data Mining with Decision Trees: Theory and Applications. — River Edge, NJ, USA: World Scientific Publishing Co., Inc., 2008. — 244 с.
- J. Ross Quinlan. C4.5: programs for machine learning. — San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1993. — 302 с.
- J. Ross Quinlan. Induction of Decision Trees // Machine Learning. — 1986. — № 1. — С. 81–106.
- Wei Dai, Wei Ji. A MapReduce Implementation of C4.5 Decision Tree Algorithm // International Journal of Database Theory and Application Vol. 7. — 2014. — № 1. — С. 49–60.
- Jerzy W. Grzymala-Busse, Witold J. Grzymala-Busse. Handling Missing Attribute Values // Data Mining and Knowledge Discovery Handbook. — New York, NY, USA: Springer US, 2005. — С. 37–57.
- J. Ross Quinlan. Unknown attribute values in induction // Proceedings of the sixth international workshop on Machine learning. — San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1989. — С. 164–168.
- Preeti Patidar, Anshu Tiwari. Handling Missing Value in Decision Tree Algorithm // International Journal of Computer Applications Vol. 70. — 2013. — № 13. — С. 31–36.
- Ian H. Witten, Eibe Frank, Mark A. Hall. Data Mining: Practical Machine Learning Tools and Techniques. — San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2011. — 664 с.
- Badr HSSINA, Abdelkarim MERBOUHA, Hanane EZZIKOURI, Mohammed ERRITALI. A comparative study of decision tree ID3 and C4.5 // International Journal of Advanced Computer Science & Applications. — 2014. — № 3. — С. 13–19.
- Rutvija Pandya, Jayati Pandya. C5.0 Algorithm to Improved Decision Tree with Feature Selection and Reduced Error Pruning // International Journal of Computer Applications Vol. 117. — 2015. — № 16. — С. 18–21.
