





В статье рассматриваются методики обработки устных спонтанных монологических текстов. Построение графов семантических связей полей в тексте производилось в ИС «Семограф». С целью выбора адекватного метода семантического анализа текста один и тот же текст был обработан разными методиками. Сравнительный анализ методик позволяет говорить о значительных изменениях в семантических структурах текстов.
Ключевые слова: методика, устная речь, семантическая структура текста, граф, эксперимент.
С середины XX в. начинается активное изучение устной речи, продолжающееся и по сей день. В лингвистике складывается несколько точек зрения на то, что представляет собой устная речь, текст ли это, текстоид и т. д. Мы придерживаемся точки зрения, что устный спонтанный монолог на заданную тему (материал изучения) является текстом. «Несмотря на то что понятие “текст” является одним из базовых в лингвистике, до сих пор не существует его единого определения. Это обусловлено, во-первых, многообразием явлений, подводимых под категорию “текст”, а во-вторых, различными аспектами его изучения: текст можно рассматривать в статике и динамике, с точки зрения формы и содержания, в широком и узком смыслах и т. д». [8, с. 5]. Не углубляясь в рассмотрение различных подходов к тексту, отметим, что мы склоняемся к пониманию текста, сформулированному в рамках петербургской лингвистической школы, и в качестве рабочего определения текста примем определение, данное Ю. С. Масловым: «В лингвистике термином “текст” обозначают не только записанный, зафиксированный так или иначе текст, но и любое кем-то созданное “речевое произведение” любой протяженности — от однословной реплики до целого рассказа, поэмы или книги» [6, с. 11]. Базовыми свойствами текста, которые выделяет большинство исследователей, являются цельность и связность [5, 7, 9, 10 и др.]. Именно благодаря им текст становится принадлежностью системы языка.
Благодаря тому, что устный текст является цельным и связным, можно изучать его семантическую структуру, которая, по мнению Т. В. Жеребило, основана на правилах языкового кодирования и отражает языковую и когнитивную информацию [4, с. 88]. Задача исследования — изучение семантической структуры текста. Под семантической структурой текста мы подразумеваем совокупность важных тем и подтем текста, семантических единиц, реализующих эти подтемы, и разнообразных связей (семантических и грамматических) между единицами и темами/подтемами. При анализе семантической структуры текста мы идем от поверхностной структуры к глубинной, от локальной связности через глобальную к цельности текста (собственно, как и поступает человек при восприятии текста).
Материалом исследования стал устный монологический текст о себе, состоящий из 125 уникальных компонентов, т. е. разных, неповторяющихся лексем. Автор текста — мужчина-негуманитарий, 36 лет, с высшим образованием. Для обработки материала пользуемся Системой графосемантического моделирования «Семограф» [http://semograf.com], созданной совместными усилиями программистов и лингвистов. В этой системе в основу заложен метод, дающий возможность частичной автоматической обработки данных, а также строящий граф зависимостей [1]. При определении полей мы опирались на [2, 3 и др]. Цель работы — выделение наиболее значимых контекстуально-семантических полей в тексте и выяснение структуры их взаимодействия в данном тексте. Цель данной статьи — обоснование выбора методики исследования.
Согласно методике, реализованной в ИС «Семограф» (К. И. Белоусов), текст делится на синтагмы, слова каждой синтагмы получают семантическое описание через отнесение к семантическому полю. Например, в синтагме пять часов слово пять относится к полю КОЛИЧЕСТВО, а часов — к полю ВРЕМЯ. Или в синтагме большой снегопад слово большой относится к полю КАЧЕСТВО, а снегопад — к полю ПРИРОДНЫЕ ЯВЛЕНИЯ (ПОГОДА). Программа автоматически считает связанными слова одной синтагмы. Получаемый в результате анализа граф изображает семантические связи полей в тексте (см. рис. 1).
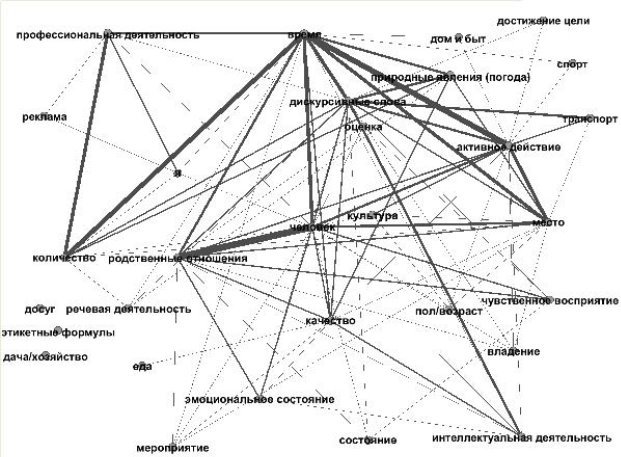
Рис. 1. Граф семантических связей полей в тексте, построенный с использованием методики разработчиков ИС «Семограф»
Однако такой тип анализа учитывает только вхождения слов в синтагму, но не синтаксические связи между ними. Поэтому стандартная методика была нами изменена. Согласно новой методике обработки материала слова относятся к контекстуально-семантическим полям с учетом не только семантики, но и их синтаксических связей. Например, в словосочетании пять часов существительное часов относится к полю ВРЕМЯ, а пять — одновременно к полям и КОЛИЧЕСТВО, и ВРЕМЯ, поскольку числительное обозначает именно количество времени. Или в словосочетании большой снегопад существительное снегопад относится к полю ПРИРОДНЫЕ ЯВЛЕНИЯ (ПОГОДА), а прилагательное большой — одновременно к полям КАЧЕСТВО и ПРИРОДНЫЕ ЯВЛЕНИЯ (ПОГОДА), т. к. обозначает именно качество явления.
Обработка происходит в той же ИС «Семограф», в результате обработки также получаем граф семантических связей (см. рис. 2).
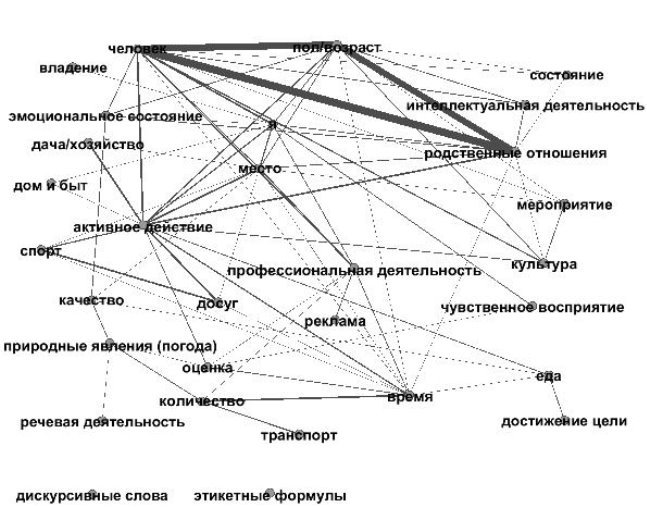
Рис. 2. Граф семантических связей полей в тексте, построенный с использованием нашей методики
Как видим из представленных графов, методики дают разный результат. Во-первых, меняется сила связи между полями, например, с учетом синтаксических связей поля СПОРТ и АКТИВНОЕ ДЕЙСТВИЕ связаны сильнее, чем если учитывать только семантику. Во-вторых, при учете синтаксических отношений поля ЭТИКЕТНЫЕ ФОРМУЛЫ и ДИСКУРСИВНЫЕ СЛОВА оказались не связанными с другими полями вообще, а без учета этих отношений такими полями стали ДАЧА/ХОЗЯЙСТВО, ДОСУГ и ЭТИКЕТНЫЕ ФОРМУЛЫ.
Рассмотрим различия, которые дают методики, на примере поля КОЛИЧЕСТВО. Как видим, обе методики показывают, что наиболее сильную связь оно образует с полем ВРЕМЯ (см. рис. 3 и рис. 4).
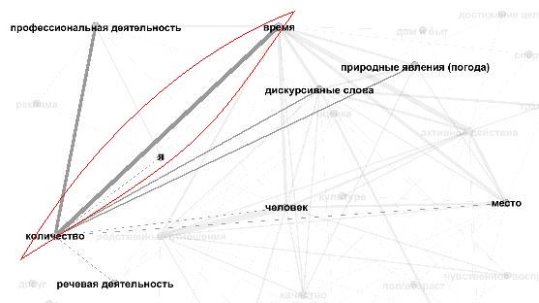
Рис. 3. Связь поля КОЛИЧЕСТВО с другими полями при использовании методики разработчиков ИС «Семограф»
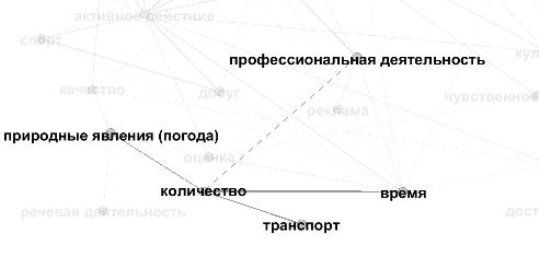
Рис. 4. Связь поля КОЛИЧЕСТВО с другими полями при использовании нашей методики
Как видим, помимо силы связи между полями меняются и сами поля. Кроме общих в обоих случаях полей ВРЕМЯ, ПРОФЕССИОНАЛЬНАЯ ДЕЯТЕЛЬНОСТЬ И ПРИРОДНЫЕ ЯВЛЕНИЯ (ПОГОДА), в первом случае связанными с полем КОЛИЧЕСТВО будут поля Я, ЧЕЛОВЕК, МЕСТО, РЕЧЕВАЯ ДЕЯТЕЛЬНОСТЬ И ДИСКУРСИВНЫЕ СЛОВА, а во втором случае — поле ТРАНСПОРТ.
Для ответа на вопрос, какой же метод больше соответствует цели и задачам нашего исследования, нами был проведен эксперимент в форме письменного анкетирования. Испытуемыми стали 25 филологов в возрасте от 20 до 25 лет, уже имеющие высшее образование или учащиеся старших курсов. Им необходимо было прослушать 3-х минутный монолог о себе и ответить на 2 вопроса: 1) выделите 5 основных тем текста; 2) выделите 3 наиважнейшие связи между выделенными темами.
Нами было выделено 30 полей, информанты же выделили 19 тем, совпадающих с нашими полями. Граф связей между выделенными информантами темами выглядит так:
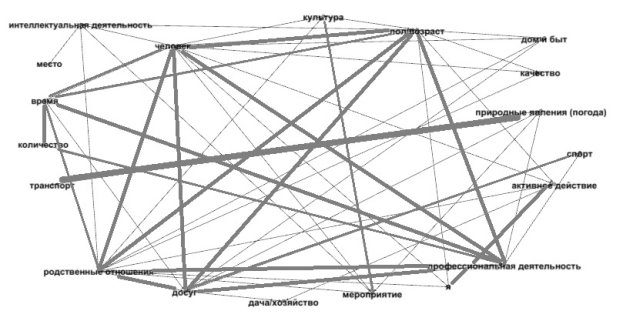
Рис. 5. Граф связей между темами, которые выделили информанты
Как видим, наиболее легко опознаваемой и почти всеми информантами выделенной была связь погоды и пробок (в нашем случае: ПРИРОДНЫЕ ЯВЛЕНИЯ (ПОГОДА) и ТРАНСПОРТ).
Интересным оказался тот факт, что информанты выделили в основном те поля, которые имеют сильные связи с другими при обработке упомянутыми выше двумя методиками. Только к этим основным полям добавились поля ДОСУГ, ДОМ И БЫТ, МЕРОПРИЯТИЕ. Отсутствуют поля ЭМОЦИОНАЛЬНОЕ СОСТОЯНИЕ, ОЦЕНКА.
Сравним полученные 3 графа. При сопоставлении графов получаем, что граф по результатам эксперимента и граф по нашей методике имеют больше общего, отражают наиболее важные связи. Таким образом, получается, что на семантическую структуру текста одинаково сильно влияют семантика и грамматика.
Анализ графов показал, что применение той или иной методики должно быть обусловлено целью исследования. При исследовании семантического пространства текста в статике следует пользоваться оригинальной методикой разработчиков «Семографа», а при изучении семантического развертывания текста предложенная нами методика будет более адекватна.
Литература:
- Белоусов К. И., Зелянская Н. Л., Баранов Д. А. Концептуально гипертекстовая модель управления контентом в ИС «Семограф» // Вестник Оренбургского государственного университета. 2012. № 11. С. 56–61.
- Большой толковый словарь русских глаголов: идеографическое описание. Англ. эквиваленты. Синонимы. Антонимы / под общ. ред. Л. Г. Бабенко. М.: АСТ-ПРЕСС КНИГА, 2007. 576с.
- Большой толковый словарь русских существительных: Идеографическое описание. Синонимы. Антонимы / под ред. Л. Г. Бабенко. Москва: АСТ-ПРЕСС КНИГА, 2005. 864 с.
- Жеребило Т. В. Термины и понятия: Методы исследования и анализа текста: Словарь-справочник. Назрань: ООО «Пилигрим», 2011. 108 с.
- Леонтьев А. А. Признаки связности и цельно-сти текста // Лингвистика текста. М., 1974. Ч.1. С. 169–172.
- Маслов Ю. С. Введение в языкознание. М.: Высш. шк., 1998. 272 с.
- Мурзин Л. Н., Штерн А. С. Текст и его восприятие. Свердловск: Изд-во Урал. ун-та, 1991. 172 с.
- Павлова Д. С., Ерофеева Е. В. Семантическая структура устного спонтанного текста: теоретические и методологические подходы к исследованию // Вестник Пермского университета. Российская и зарубежная филология. 2015. № 1 (29). С. 5–17.
- Сахарный Л. В. Введение в психолингвистику: курс лекций. Л.: Изд-во Ленингр. ун-та, 1989. 184 с.
- Тураева З. Я. Лингвистика текста (текст: структура и семантика). М.: Просвещение, 1986. 127 с.
