




Модификация алгоритма Смита — Уотермана для задачи автоматического распознавания слитной речи

Авторы: Пикалёв Ярослав Сергеевич, Ермоленко Татьяна Владимировна
Рубрика: 1. Информатика и кибернетика
Опубликовано в
Дата публикации: 06.02.2019
Статья просмотрена: 295 раз
Библиографическое описание:
Пикалёв, Я. С. Модификация алгоритма Смита — Уотермана для задачи автоматического распознавания слитной речи / Я. С. Пикалёв, Т. В. Ермоленко. — Текст : непосредственный // Актуальные вопросы технических наук : материалы V Междунар. науч. конф. (г. Санкт-Петербург, февраль 2019 г.). — Санкт-Петербург : Свое издательство, 2019. — С. 8-11. — URL: https://moluch.ru/conf/tech/archive/324/14840/ (дата обращения: 18.04.2024).
В данной работе рассмотрен классический и модифицированный алгоритм Смита-Уотермана. Выполнено их сравнение в задаче улучшения результата автоматического распознавания слитной речи. Выделены преимущества и недостатки модифицированного алгоритма. Описаны общие недостатки, присущие алгоритму Смита-Уотермана при автоматическом распознавании речи.
Ключевые слова: автоматическое распознавание речи; динамическое программирование; локальное выравнивание; WER.
Алгоритм Смита-Уотермана [1], являющийся алгоритмом парного выравнивания (sequence alignment), как правило, применяется в сфере биоинформатики для нахождения сходств (локальное выравнивания) между ДНК. Помимо задач из сферы биоинформатики данный алгоритм можно применять для нахождения последовательностей, которые, как предполагается, имеют сходство. При этом природа элементов последовательностей может быть различной. Т. е. алгоритм Смита-Уотермана находит локальные паттерны с высоким уровнем сходства. В рамках автоматического распознавания речи алгоритм Смита-Уотермана применяют для сравнения строк — эталонной и строки текста, полученной в результате распознавания устной речи, что позволяет исправлять ошибки при распознавании.
Описание классического алгоритма Смита-Уотермана
В рамках алгоритма Смита-Уотермана нахождение оптимального выравнивания сводится к решению задачи динамического программирования. Входные данные: последовательности символов q1 (эталон), q2 (последовательность, подаваемая на сравнение после распознавания), длинной n и m соответственно; score_match — размер «поощрения», добавляемое каждый раз при совпадении элементов последовательностей q1 и q2; score_pen — размер штрафа, добавляемый за несовпадение элементов последовательностей q1 и q2.
Промежуточные переменные — матрица оценок ![]() , элементы которой соответствуют накопленным очкам, добавляемым в результате поощрения или штрафа в ходе сравнения последовательностей q1 и q2.
, элементы которой соответствуют накопленным очкам, добавляемым в результате поощрения или штрафа в ходе сравнения последовательностей q1 и q2.
Классический алгоритм Смита-Уотермана состоит из следующих этапов.
- Инициализация: элементам первой строки и первого столбца матрицы М присваивается нулевое значение, определяются значения поощрений и штрафов.
m(1, j) = 0 для j= 1,…,n+1; m(i,1) = 0 для i= 1,…,m+1.
score_match = 2; score_pen = -1.
- Вычисляются элементы матрицы М:
m(i, j) = m(i-1, j-1) + score, (1)
где ![]() .
.
-
Обратный ход для поиска локальных паттернов с высоким уровнем сходства (трассировка). Трассировку нужно начинать с
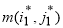 — элемента матрицы М с максимальным значением. Итеративно получаем последовательность индексов элементов матрицы М. На итерации l ищется максимальный элемент среди соседних элементов с
— элемента матрицы М с максимальным значением. Итеративно получаем последовательность индексов элементов матрицы М. На итерации l ищется максимальный элемент среди соседних элементов с 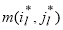 :
:
![]() .(2)
.(2)
Последней является итерация k, если ![]() .
.
Выходными данными алгоритма (результатом выравнивания) является подпоследовательность эталонной последовательности q1, содержащаяся в последовательности q2:
![]() .(3)
.(3)
Рисунок 1 демонстрирует результат обратного хода.
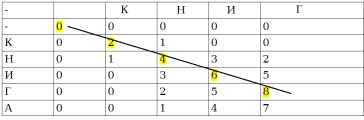
Рис. 1. Результат обратного ходя для q2 «книга» и q1 «книг»
Описание модифицированного алгоритма Смита-Уотермана
Недостатком классического алгоритма Смита-Уотермана является тот факт, что для ряда задач, таких как выравнивание результатов распознавания речи, результатом выравнивания может стать не слово, а лишь его часть, в то время как модифицированный алгоритм позволяет этого избежать. Для вышеописанной задачи эталон, q1, состоящий из единой строки, образуется посредством считывания множества массивов текстовых объектов, отделённых друг от друга в строке знаком пробела («», delimiter). Таким образом, известно, что начало и конец последовательностей строк отделяются символом пробела. Модифицированный алгоритм Смита-Уотермана отличаются следующим.
- Используем алгоритм трассировки из классического алгоритма, но запоминаем начало (beg_query) и конец (end_query) совпадения в исходных данных, а также ищем не одно максимальное, а n-максимальных, в том случае, если есть несколько вхождений с одинаковыми максимальными оценками.
![]() (4)
(4)
- Если beg_query не является первым символом строки q1, то проверяем является ли beg_query-1 символом delimiter. Если да, то началом результата выравнивания является beg_query. Иначе — сдвигаем начало результата выравнивания, на предыдущий символ, пока не встретим delimiter или не попадём на первый символ.
- Если end_query не является концом строки q1, то проверяем является ли end_query+1 символом delimiter. Если да, то концом результата выравнивания является end_query. Иначе — сдвигаем конец результата выравнивания на следующий символ, пока не достигнем delimiter или конца строки q1.
- В случае, если в результате выравнивания имеются несколько вхождений с одинаковыми максимальными оценками — выполняем для каждого паттерна шаги 2, 3. Затем выбираем вхождение с наименьшим количеством символов.
Эксперимент выравнивания для результатов распознавания речи
Эксперимент проводился для выравнивания результатов распознавания речи. Данная система распознавания речи основана на статистическом моделировании: акустическая модель обучена с использованием GMM-HMM (гауссовых смесей на основе скрытых Марковских моделей) подхода [2] с применением дискриминационного обучения, а также глубоких нейронных сетей. Языковая модель построена с использованием 3-gram (общее количество 1-gram: 410191; 2-gram: 5347632; 3-gram: 3899721) на текстах, извлечённых из дампа Википедии, а также из новостных лент; словарь использовался на основе 1-gram из языковой модели. В качестве обучающих данных использовался исправленный корпус VoxForge, общая продолжительность аудио составляет около 15 ч. В качестве тестовых данных использовались аннотированные записи 2 мужских дикторов (по 200 аудиозаписей для каждого диктора; текст один и тот же).
Результаты распознавания, а также выравнивания их результатов отображены в табл. 1, где WER — процент верно распознанных слов; SER — процент верно распознанных предложений (фраз); sw_o — правка результатов распознавания при помощи классического алгоритма Смита-Уотермана; sw_m — правка результатов распознавания при помощи модифицированного алгоритма Смита-Уотремана; dict1, dict2–1-й и 2-ой дикторы. Помимо этого, в табл. 2 приведены примеры распознавания и соответствующих правок, где source_right — оригинальная последовательность слов (что распознавалось); target — результат распознавания.
Таблица 1
Результаты распознавания иих выравниваний
|
WER(target) |
SER(target) |
WER(sw_o) |
SER(sw_o) |
WER(sw_m) |
SER(sw_m) |
|
|
dict1 |
37.26 % |
77 % |
14.25 % |
34 % |
4.62 % |
15 % |
|
dict2 |
40.89 % |
83.5 % |
21.19 % |
47 % |
6.73 % |
25 % |
Таблица 2
Примеры результата распознавания ипоследующих выравниваний
|
source_right |
dict1(target) |
dict2(target) |
dict1(sw_o) |
Dict2(sw_o) |
dict_1(sw_ m) |
dict2(sw_m) |
|
молох |
запах |
мало |
задач |
моло |
задачах |
Молох |
|
об интеллекте |
интеллекте |
пол интеллекте |
интеллекте |
об интеллекте |
интеллекте |
Об интеллекте |
|
автоматическое распознавание речи |
автоматического распознавания речи |
автоматического распознавания речи |
автоматического распознавания речи |
автоматического распознавания речи |
автоматического распознавания речи |
автоматического распознавания речи |
Заключение
Таким образом, модифицированный алгоритм Смита-Уотермана не ограничен длиной строки, а также показывает более высокую точность выравнивания по сравнению с классическим; из недостатков можно выделить тот факт, что данный алгоритм менее быстродейственный из-за наличия дополнительных операций.
Также, можно выделить общие недостатки, которые присущи как классическому, так и модифицированному алгоритму Смита-Уотермана:
1) В случае, если в target кол-во несоответствий с source (последовательность исходных данных) составляет ![]() , то результат выравнивания не даст улучшения.
, то результат выравнивания не даст улучшения.
2) В случае, если в source есть сложное слово (более одного корня), а в target вместо одного сложного слова находятся два слова, одно из которых не соответствует одному из корней ![]() . Тогда, если в множестве source есть похожее вхождение одного из двух слов — результат выравнивания может быть неверным.
. Тогда, если в множестве source есть похожее вхождение одного из двух слов — результат выравнивания может быть неверным.
3) Проблемы с падежами, родом, временем и т. п. В том случае, если в source встречается последовательность слов, отличающаяся вышеописанными признаками, при условии, что target задан только этой проблемной последовательностью, то выравнивание не даст улучшения. Пример: source_right — “автоматическое распознавание речи”; source_false (неверный вариант из последовательности source) — “методы автоматического распознавания речи”; sw_m — “автоматического распознавания речи”.
4) В случае, если падеж, род, время target не соответствуют source_right и такая последовательность встречается в других вхождениях source, то выравнивание не даст улучшения. Например: source_right — “нейронные сети”; source_false — “подход к определению параметров нейронной сети”; sw_m — “нейронной сети ”.
5) Если в результате распознавания пропущено слово, как правило, являющееся коротким словом, то при выравнивании это слово не будет учитываться. Пример: source_right — “об интеллекте”; target — “интеллекте”; sw_m –»интеллекте».
Стоит отметить, что недостатки, описанные в пунктах 3, 4, 5 могут быть устранены за счёт внедрения меток начала и конца (например, «<» и «>») с cоответствующими изменениями в модифицированном алгоритме Смита-Уотермана.
Литература:
- Smith T. F., Waterman M. S. Comparison of biosequences //Advances in applied mathematics. — 1981. — Т. 2. — №. 4. — С. 482–489.
- F. Jelinek. Statistical methods for speech recognition // MIT Press. ‒ 1997. ‒ p. 283.
Ключевые слова
Динамическое программирование, , автоматическое распознавание речи, локальное выравнивание, WERПохожие статьи
Методы распознавания речи | Статья в журнале «Молодой...»
Методы распознавания речи. Автор: Воробьева Светлана Алексеевна.
Распознавание речи включает в себя два основных этапа: предварительную обработку сигнала и его
Результат суммирования передается в активационную функцию F. Существуют различные виды...
Алгоритмы распознавания объектов | Статья в сборнике...
В данной статье рассмотрены алгоритмы распознавания объектов на изображении, проведен анализ методов, применяемых при обработке изображений, а также описано использование средств машинного обучения в рамках работы с изображениями.
Распознавание речи на основе искусственных нейронных сетей
В результате проделанной работы предложена модель распознавания речи на основе искусственных нейронных сетей. Так же в настоящий момент разрабатывается подход обучения нейронной сети с применением генетического алгоритма. Данный подход будет реализован в...
Система управления устройствами «умного дома»...
В статье рассматривается метод распознавания речи на основе облачного сервиса, производится фильтрация исходных данных, производится исследование применимости данного метода в задаче распознавания голосовых команд Умного дома.
Сегментация, шумоподавление и фонетический анализ в задаче...
По результатам распознавания можно заключить, что алгоритм Дамерау-Левенштейна лучше всего подходит для получения грамматической формы слова. Ключевые слова: распознавание речи, сегментация, метрика Дамерау-Левенштейна, спектральный центроид.
Задача распознавания речи и выбор оптимального сервиса для...
В статье рассматривается задача распознавания речи, классификация систем распознавания речи. Рассматриваются основные достоинства и недостатки существующих решений с открытым и с закрытым исходным кодом.
Применение и модификация алгоритма Вагнера — Фишера...
Распознавание голоса осуществляет стандартная служба, входящая в пакет
Таким образом, целью данной работы была реализация алгоритма сопоставления на основе
Практическая значимость работы заключается в том, что модифицированный алгоритм может...
Использование преобразования Гильберта-Хуанга для...
Конечной целью создания систем распознавания речи является способность машины распознавать слова в акустическом сигнале с
При создании системы преобразования речи в текст одна из самых важных задач — выбор единицы распознавания.Рассмотрим основные...
Предварительная обработка речевых сигналов для системы...
Распознавание речи является задачей классификации образов акустических характеристик
В системах распознавания речи на основе нейронной сети выделяются две основные
Планируется разработать систему автоматического распознавания речи на основе...
Похожие статьи
Методы распознавания речи | Статья в журнале «Молодой...»
Методы распознавания речи. Автор: Воробьева Светлана Алексеевна.
Распознавание речи включает в себя два основных этапа: предварительную обработку сигнала и его
Результат суммирования передается в активационную функцию F. Существуют различные виды...
Алгоритмы распознавания объектов | Статья в сборнике...
В данной статье рассмотрены алгоритмы распознавания объектов на изображении, проведен анализ методов, применяемых при обработке изображений, а также описано использование средств машинного обучения в рамках работы с изображениями.
Распознавание речи на основе искусственных нейронных сетей
В результате проделанной работы предложена модель распознавания речи на основе искусственных нейронных сетей. Так же в настоящий момент разрабатывается подход обучения нейронной сети с применением генетического алгоритма. Данный подход будет реализован в...
Система управления устройствами «умного дома»...
В статье рассматривается метод распознавания речи на основе облачного сервиса, производится фильтрация исходных данных, производится исследование применимости данного метода в задаче распознавания голосовых команд Умного дома.
Сегментация, шумоподавление и фонетический анализ в задаче...
По результатам распознавания можно заключить, что алгоритм Дамерау-Левенштейна лучше всего подходит для получения грамматической формы слова. Ключевые слова: распознавание речи, сегментация, метрика Дамерау-Левенштейна, спектральный центроид.
Задача распознавания речи и выбор оптимального сервиса для...
В статье рассматривается задача распознавания речи, классификация систем распознавания речи. Рассматриваются основные достоинства и недостатки существующих решений с открытым и с закрытым исходным кодом.
Применение и модификация алгоритма Вагнера — Фишера...
Распознавание голоса осуществляет стандартная служба, входящая в пакет
Таким образом, целью данной работы была реализация алгоритма сопоставления на основе
Практическая значимость работы заключается в том, что модифицированный алгоритм может...
Использование преобразования Гильберта-Хуанга для...
Конечной целью создания систем распознавания речи является способность машины распознавать слова в акустическом сигнале с
При создании системы преобразования речи в текст одна из самых важных задач — выбор единицы распознавания.Рассмотрим основные...
Предварительная обработка речевых сигналов для системы...
Распознавание речи является задачей классификации образов акустических характеристик
В системах распознавания речи на основе нейронной сети выделяются две основные
Планируется разработать систему автоматического распознавания речи на основе...




