В жизни практически каждого успешного онлайн проекта наступает момент, когда требуется обрабатывать большее число запросов от пользователей (или какие-либо другие данные) за фиксированный промежуток времени. Такое увеличение производительности называется масштабированием вычислительной системы. И должно быть учтено с самого начала работы над проектом.
Существует два подхода к масштабированию:
– Вертикальное масштабирование — наращивание производительности компонент системы для увеличения общей производительности. В частности это может быть переезд на более мощный сервер или оптимизация ресурсов текущего сервера. Этот способ масштабирования зачастую не требует изменений в исходном коде продукта, что делает его относительно простым и более очевидным.
– Горизонтальное масштабирование — разделение системы на компоненты для последующего размещения таких компонент на разных (в том числе и физических) серверах. Масштабируемость в этом случае достигается путем введения параллельности обработки нескольких запросов или каких-либо других заданий. Этот способ повышения производительности системы требует изменение в коде, чтобы программы могли в полной мере использовать все предоставленные им ресурсы.
В этой статье мы рассмотрим реализацию горизонтального масштабирования, как наиболее оптимального и перспективного с точки зрения использования платных ресурсов хостинга и гибкости в итоге полученной системы.
Каждый компонент системы мы будем помещать в Docker контейнер. Docker — программное обеспечение для автоматизации развёртывания и управления приложениями в среде виртуализации на уровне операционной системы.
Одна из наиболее часто встречающихся и весьма ресурсозатратных операций с данными на сервере это обработка изображений. Например, когда требуется создавать копии изображений меньшего размера для отображения контента веб страниц. Для операций с изображениями будем использовать библиотеку Sharp, она позволяет производить всевозможные манипуляции с изображениями в форматах JPEG и PNG. Рассмотрим (Рис. 1) пример исходного кода для модификации размера изображения.
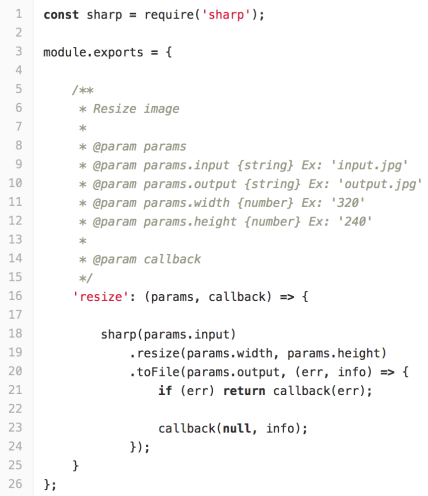
Рис. 1. Изменение размера изображения при помощи библиотеки Sharp
Предположим, мы хотим обрабатывать множество изображений одновременно, разделив тем самым нагрузку между двумя физическими серверами. Для этой цели будем использовать модель очереди заданий. Каждое действие с изображением будет представлено как задание в очереди. В один момент времени на каждом физическом сервере может выполняться одновременно до десяти заданий (на самом деле это число не ограничено, все зависит от конкретной ситуации и обрабатываемых данных).
Для реализации очереди будем использовать NPM модуль Kue. Kue — это очередь заданий с приоритезацией, поддерживающая Redis и работающая на платформе Node.js.

Рис. 2. Kue клиент для добавления заданий в очередь
На Рис. 2 показан пример создания клиента для подключения к очереди и процесс добавления задания. При этом, в примере, мы указываем какой размер изображения должен быть использован для создания копии.
После того как задание добавляется в очередь, каждый из физических серверов, на котором запущены сервера очереди может начать его выполнение. Распределение заданий происходит случайным образом (при прочих равных условиях).
На Рис. 3 показан серверный код очереди, в котором мы так же указываем адрес на котором работает Redis для синхронизации заданий и добавляем воркер, который будет обрабатывать задания с типом image.

Рис. 3. Сервер очереди и пример добавления воркера
По завершению выполнения задание будет удалено из очереди и, так же, будет записал текстовый лог о результатах его выполнения.
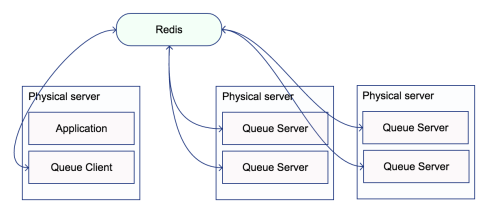
Рис. 4. Архитектура распределенной системы с очередью заданий
В итоге мы разделили нагрузку по обработке изображений между двумя физическими серверами, одновременно, перенеся ее с основного сервера приложения. В зависимости от интенсивности нагрузки мы можем выполнять масштабирование, добавляя и удаляя сервера в режиме реального времени, именно тогда когда этого требует от нас текущая ситуация. Что позволяет максимально оптимизировать затраты на аренду серверов.
Литература:
- Kue. // GitHub — Kue. URL: https://github.com/Automattic/kue (дата обращения: 14.11.2017).
- Sharp. // Sharp. URL: http://sharp.dimens.io/en/stable/ (дата обращения: 05.12.2017)
- Docker. // What is Docker. URL: https://www.docker.com/what-docker (дата обращения: 23.11.2017)

