В данной статье будет рассмотрена тема определения авторства анонимного текста за счёт частотных характеристик. Тема является достаточно актуальной на сегодняшний день и охватывает большой спектр целей: от отыскания автора необходимой вам статьи в интернете или запоминающегося отрывка художественного произведения до достаточно серьёзных военных целей.
Рассмотренные в данной работе методы и приёмы помогают достаточно точно определить автора необходимого вам текста или сообщения, т. к. базируются на особенностях речи людей.
Для определения истинного автора текста зачастую приходится обращаться к экспертам, которые могут идентифицировать автора неизвестного текста или определить принадлежность произведения другому автору при помощи характерных языковых особенностей и различных стилистических приемов. Важно отметить, что задача установления авторства текстов (задача атрибуции) встречается в различных областях и представляет интерес для филологов, литературоведов, юристов, криминалистов, историков. В настоящее время для атрибуции текстов применяются подходы из теории распознавания образов, математической статистики и теории вероятностей, алгоритмы нейронных сетей и кластерного анализа и многие другие.
Целью данной статьи является разработка программного продукта, который решал бы задачу об определении авторства художественных и научных текстов, выявление различных зависимостей результатов работы программы от входных параметров, а также определение влияния стиля исходного текста на точность определения автора.
Проведём анализ существующих систем по определению авторства текста.
Атрибуция текста — исследование текста с целью установления авторства или получения каких-либо сведений об авторе и условиях создания текстового документа. Задачи атрибуции можно разделить на идентификационные и диагностические.
Идентификационные задачи решаются из предположения, что автор текста известен. Диагностические задачи позволяют определить личностные характеристики автора (образовательный уровень, родной язык, знание иностранных языков, происхождение, место постоянного проживания и др.) и факт сознательного искажения письменной речи. Диагностические задачи решаются из предположения, что автор текста неизвестен.
Существует довольно много методов анализа стиля. В целом можно разделить их на две большие группы — экспертные и формальные. Экспертные методы предполагают исследование текста профессиональным лингвистом-экспертом. К формальным относятся приемы из теории вероятностей и математической статистики, алгоритмы кластерного анализа и нейронных сетей.
Приведём примеры существующего программного обеспечения по определению авторства текста.
Система «Лингвоанализатор». Метод, применяемый в этой системе для определения авторства текста, основан на формальной математической модели. Программа учитывает следующие характеристики языка автора: число служебных слов; используемые морфемы; уровень сложности употребленных грамматических конструкций; словарный запас.
Система «Атрибутор». Данная программа является онлайн лингвистическим процессором для машинного сравнения текстов и их классификации по параметрам индивидуального авторского стиля. Произведения подбирались так, чтобы тексты разных писателей имели как можно больше различий, а тексты одного писателя имели максимальные сходства. На данный момент система обучена сравнивать только тексты романов. Для атрибуции достаточно примерно шесть печатных страниц.
Система «СМАЛТ». Система состоит из двух основных блоков: функционального (анализ, база данных) и аналитического (реализация методик статистического анализа текстов). Проект еще не доработан до конца и предполагает разработку информационной системы, применяющую статистические методы анализа. В основе должна иметься база литературных произведений, состоящая из публицистики 60–70 гг. 19 века. Обработка текстов в данной системе производится поэтапно. Сперва производится автоматизированное разбиение исходного текста на: раздел, абзац, предложение, слово. Затем осуществляется автоматическая обработки текста, его морфологический разбор и синтаксический анализ. После чего пользователем выполняются операции из базы данных по анализу текстов.
Система «Авторовед». Программа, основанная на фоносемантическом анализе, составляет психологический портрет автора. Система содержит набор DLL-библиотек, которые подключаются к текстовому процессору Word for Windows и в главном меню появляется новый пункт. Таким образом, данная программная система позволяет пользователю работать в привычной для него среде.
Среди программных продуктов для определения авторства текстов можно выделить систему «Антиплагиат» (http://www.antiplagiat.ru). Этот интернет-сервис предлагает осуществить проверку текстовых документов на наличие заимствований из общедоступных сетевых источников. Система позволяет проводить атрибуцию текстов на различных языках. Поиск совпадений осуществляется методом сравнения последовательностей символов без учета языковых особенностей и речевых взаимосвязей. За счет этого достигается высокая, в несколько секунд, скорость поиска совпадений.
Для выполнения поставленной задачи применяются методы из теории вероятностей и математической статистики для атрибуции текстов. Предлагаемый метод основан на учете статистики употребления пар элементов любой природы, идущих друг за другом в тексте (букв, морфем, словоформ и т. п.), т. е. на формальной математической модели последовательности букв (и любых других элементов) текста как реализации цепи Маркова. По темам произведений авторов, которые достоверно ими созданы, вычислялась матрица переходных частот употребления пар элементов (букв, грамматических классов слов и т. п.). Она служила оценкой матрицы вероятности перехода из элемента в элемент. Для каждого автора строилась матрица переходных частот и оценивалась вероятность того, что именно он написал анонимный текст (или фрагмент текста). Автором анонимного текста считался тот, для кого вычисленная оценка вероятности больше.
Существуют различные подходы к решению данной задачи, отличающиеся способами формализации предметной области, объектов обучающей выборки и синтеза математической модели.
В данной статье будут рассмотрены три основные меры распознавания авторства: мера Хмелёва, дивергенция Кульбака, мера Х2. Рассмотрим их более подробно.
Идеей алгоритма Хмелева является учет и хранение различных частотных характеристик текста, биграмм (сочетание двух букв). Перед началом работы необходимо сделать подготовительные мероприятия. Задается начальное количество известных авторов и их произведений. Для каждого автора определяются статистические значение биграмм, и проводится частотный анализ заданного текста. Для определения авторства входного анонимного текста проводятся аналогичные вычисления частот биграмм и букв по тексту, далее полученные значения сравниваются с уже имеющимися статистическими. После нахождения минимальной разницы между частотными значениями анонимного текста и какого-либо текста из статистических, можно считать задачу о нахождении авторства решенной.
Для оценки эффективности методов зафиксируем элементы подсчета. Будем использовать биграммы, входной текст должен быть обработан. Так как матрицы частот переходов являются двумерными распределениями, то и сравниваются они с помощью мер сравнения двумерных распределений.
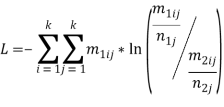
где индекс «1» — принадлежит неизвестному автору;
индекс «2» — принадлежит известному автору;
![]() ,
, ![]() — число переходов из буквы i в букву j;
— число переходов из буквы i в букву j;
![]() ,
, ![]() — общее количество повторений текущей буквы в тексте;
— общее количество повторений текущей буквы в тексте;
k — мощность алфавита, над которым происходит исследование.
Значение L тем меньше, чем меньше разница между матрицами биграмм анонимного и текущего автора. Когда значение L минимально, считается что найден автор анонимного текста.
Аналогичным образом формируется мера Хмелёва на основе частотного анализа текста. За основу берётся матрица расстояний между частотами букв известного автора и частотным анализом по анонимному входному тексту.
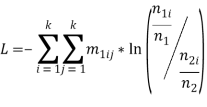
Рассмотрим дивергенцию Кульбака. Безусловную направленную дивергенцию Кульбака называют информационной мерой расхождения безусловных распределений (частот биграмм). Она может быть построена по следующей формуле:
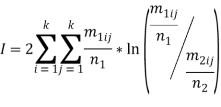
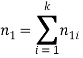
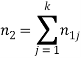
Безусловной эта мера названа, потому что в ней нет отношений типа m1ij/n1j.
Мера Х2. Меры, описанные ранее, «направлены» от матрицы анализируемого текста к матрице-эталону (усреднение по анализируемому тексту). Возможны и другие варианты — направленность на анализируемый текст (усреднение по матрице-эталону), симметричная мера (сумма мер в одну и в другую сторону пополам).
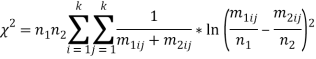
В отличие от меры Хмелева и дивергенции Кульбака мера ![]() является ненаправленной. Эта мера также, как и предыдущие, базируется на матрицах биграмм статистических открытых авторов и анонимного входного текста.
является ненаправленной. Эта мера также, как и предыдущие, базируется на матрицах биграмм статистических открытых авторов и анонимного входного текста.
В данной статье были рассмотрены основные системы и методы по определению авторства текста, которые позволяют с высокой точностью идентифицировать автора заданного анонимного текста. Данные алгоритмы показывают хорошие результаты при условии достаточно больших входных текстов, а также имеет важность объём базы данных произведений известных авторов.
Литература:
1. Батура, Т. В. Формальные методы определения авторства текстов / Т. В. Батура. — Новосибирск: Вестник НГУ, серия «Информационные технологии», Том 10, Выпуск 4
2. Поддубный, В. В. Сравнительный анализ эффективности алгоритмов распознавания авторства текстов по частотам переходов / В. В. Поддубный, О. Г. Шевелев, А. А. Фатыхов. — Томск: Вестник Томского государственного университета, Выпуск № 290 / 2006
3. Мощенкова, Д. С. Обзор программных продуктов, разработанных для атрибуции художественных текстов / Д. С. Мощенкова, Д. А. Кривицкая, Н. С. Амосова. — Молодежь и наука: сборник материалов Х Юбилейной Всероссийской научно-технической конференции студентов, аспирантов и молодых ученых с международным участием, посвященной 80-летию образования Красноярского края
4. Романов, А. С. Методика идентификации автора текста на основе аппарата опорных векторов / А. С. Романов. — Томск: Доклады ТУСУРа, часть 2, 2009
5. Кукушина О. В., Определение авторства текста с использованием буквенной и грамматической информации / О. В. Кукушина, А. А. Поликарпов, Д. В. Хмелёв. — Статья опубликована в журнале «Проблемы передачи информации». Т. 37, № 2 — М., 2001.

