




Deep learning: using long short-term memory algorithm in forecast insurance charges

Авторы: Нгуен Хынг Кыонг, Тран Тхе Туан
Рубрика: 1. Экономическая теория
Опубликовано в
VI международная научная конференция «Инновационная экономика» (Казань, июнь 2019)
Дата публикации: 04.06.2019
Статья просмотрена: 51 раз
Библиографическое описание:
Нгуен, Хынг Кыонг. Deep learning: using long short-term memory algorithm in forecast insurance charges / Хынг Кыонг Нгуен, Тхе Туан Тран. — Текст : непосредственный // Инновационная экономика : материалы VI Междунар. науч. конф. (г. Казань, июнь 2019 г.). — Казань : Молодой ученый, 2019. — С. 1-9. — URL: https://moluch.ru/conf/econ/archive/335/15120/ (дата обращения: 24.04.2024).
Forecasting insurance charges for new customers has always been a daunting task for insurance companies due to the limitations of information and computational complexity. Today, with the development of computer science, artificial intelligence and especially Deep Learning has brought new solutions ever before. With many neural units and artificial neural layers, Deep learning will be able to self-study and identify many complex issues so it is able to effectively handle the forecast of insurance charges to be paid to customers. This article focuses on introducing Long short-term memory (LSTM) algorithm in Deep Learning to forecast insurance charges through a set of actual data, through which readers can understand and apply algorithms into your own research or business issues.
Keywords: deep learning, forecast, classification, insurance charges, LSTM.
Life insurance is a potential and attractive market, but it is also very challenging and competitive for all insurance businesses. In order for insurance companies to operate effectively, the calculation of the correct insurance premium is extremely. However, it is very difficult to determine insurance fees because it must be based on scientific calculation bases to value products while ensuring customers' benefits and ensuring the profitability of insurance companies. At the same time, companies also have to calculate how to be able to pay insurance policies as well as to ensure the reserve level for other activities. Therefore, it is extremely important to accurately predict the insurance charges to pay insurance buyers, which is the most important for determining insurance premiums.
Today, with the development of computer science, artificial intelligence and especially Deep Learning has brought new solutions ever before. Deep Learning tries to simulate the bio-brain to help computers not only have the ability to process information like the human brain but also can manipulate on big data. With many neural units and artificial neural layers, Deep learning will be able to self-study and identify many complex issues so it is able to effectively handle the forecast of insurance charges to be paid to customers. Using Deep learning helps forecast insurance charges for customers easily and quickly, saving a lot of time, manpower and costs for insurers. This article studies the use of Long short-term memory (LSTM) algorithm in Recurrent Neural Network to forecast the insurance cost to be paid to customers, in Python programming language and programming library: Numpy, Pandas, Matplotlib, Scikit-learn, Tensor flow, Keras through a data processing reality.
Long short-term memory algorithm and the data set
Long short-term memory (LSTM)
Long short-term memory (LSTM) is an architectural form of Recurrent Neural Network (RNN) used in Deep Learning. Unlike standard feedforward neural networks, LSTM has feedback connections that make it a «general purpose computer». (wikipedia.org, 2019) LSTM can learn to do tasks that require memory about events that happened thousands or even millions of discrete time steps earlier. LSTM can not only process single data points (such as images), but also entire sequences of data (such as speech or video). (Sepp Hochreiter & Jürgen Schmidhuber, 1997)
A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate:
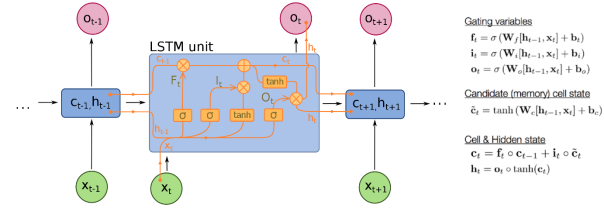
Fig. 1. A common LSTM unit component: xt: input vector to the LSTM unit; Ft: forget gate's activation vector (Sigmoid); It: input gate's activation vector (Sigmoid); Ot: output gate's activation vector (Sigmoid); ht: hidden state vector also known as output vector of the LSTM unit; ct: cell state vector [Hình 1: A LSTM unit with forget gate Nguồn: https://colah.github.io/posts/2015–08-Understanding-LSTMs/]
The Data set
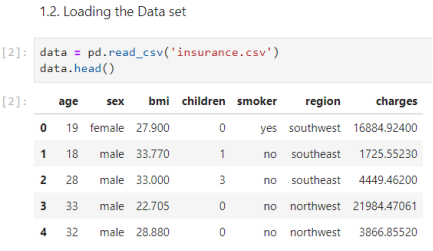
«Sample Insurance Claim Prediction Dataset» is based on «Medical Cost Personal Datasets». The data contains information of the people and based on this information the insurance company calculates the insurance charges. The goal is to forecast the insurance charges to be paid to new policyholder based on the information that the insurance company is provided from, thus calculating the premium.
Các trường thông tin bao gồm:
age: age of policyholder
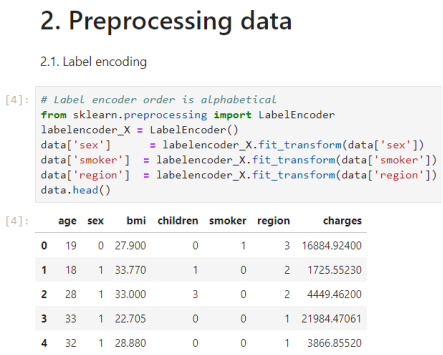
sex: gender of policy holder (female=0, male=1)
bmi: Body mass index
children: number of children / dependents of policyholder
smoker: smoking state of policyholder (non-smoke=0; smoker=1)
region: the residential area of policyholder in the US (Northeast, Northwest, Southeast, Southwest)
charges: individual medical costs billed by health insurance insuranceclaim
Source: https://www.kaggle.com/easonlai/sample-insurance-claim-prediction-dataset
Building forecasting model
Using Jupyter programming editor software to build forecasting model:



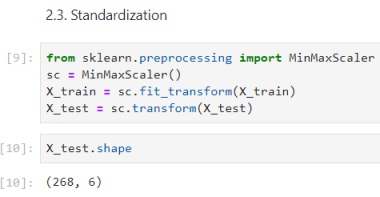
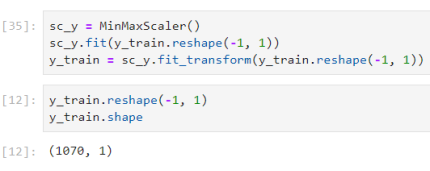
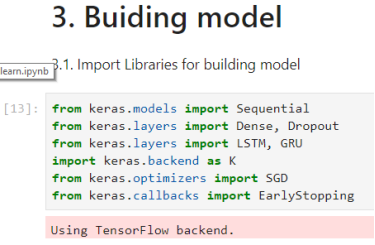
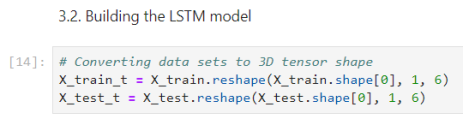

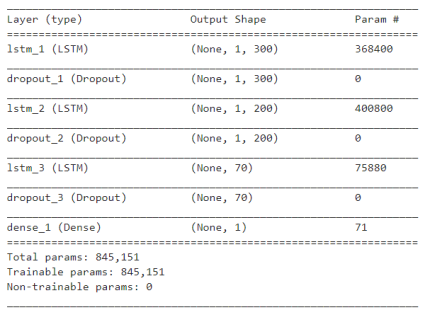
The network has 5 neural layers, 577 neural units, and 845.151 params.



The model after training has loss = 0.12 and mean absolute error = 0.0438.
DISCUSSION
To assess the accuracy of the forecast model in fact, need to check the model through the independent test data set:
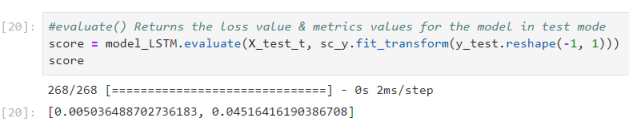
With the test data set, the model for the result changes not much compared to the train data set: loss = 0.0050 data set; mean absolute error = 0.0451.
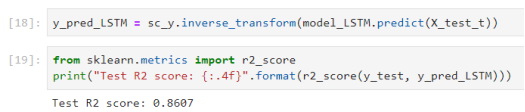
R2 Test score = 0.8607 shows model capable of explaining 86.07 % for the variation of the variable insurance charge. Thus, model_LSTM of insurance charges prediction is a good forecasting model with an ability to explain for dependent variable greater than 80 %.
Conclusion
With 6 basic information of customers, models that explain variable coverage of more than 80 %, the potential of Deep learning usage is huge in insurance premiums, as well as in general business. With the development of science and technology, the processing power of computers is increasingly strong, making Deep Learning more and more perfect, and more accurate, bringing great efficiency to society. This article introduced the use of LSTM algorithm in Deep Learning to forecast the insurance charges, but Deep Learning applications are still very large and the author will continue to introduce in the next article.
References:
- Alex Smola, & S. V. N. Vishwanathan. (2008). INTRODUCTION TO MACHINE LEARNING. Cambridge University Press.
- Edouard Duchesnayt, & Tommy Löfsted. (2018). Statistics and Machine Learning in Python — Release 0.2. ftp://ftp.cea.fr.
- Frank Rosenblatt. (1961). Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms. Washington DC: Spartan Books.
- Guido van Rossum, & et al. (2018). The Python Language Reference — Release 3.7.1. Python Software Foundation.
- JürgenSchmidhuber. (2015). Deep learning in neural networks: An overview. Neural Networks, 61, 85–117.
- NumPy community. (2018). NumPy Reference — Release 1.15.4. SciPy.org.
- Keras. (2019). Keras Documentation. keras.io
- Scikit-learn developers. (2018). scikit-learn user guide — Release 0.20.1. scikit-learn.org.
- Sepp Hochreiter, & Jürgen Schmidhuber. (1997). Long Short-Term Memory (Volume 9, Issue 8 ed.). Massachusetts Institute of Technology.
- Shai Shalev-Shwartz, & Shai Ben-David. (2014). Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press.
- Shashi Sathyanarayana. (2014). A Gentle Introduction to Backpropagation. Numeric Insight, Inc Whitepaper.
- Wes McKinney & et al. (2018). pandas: powerful Python data analysis toolkit — Release 0.23.4. PyData Development Team.
- wikipedia.org/wiki/Long_short-term_memory
Похожие статьи
GRU и LSTM: современные рекуррентные нейронные сети
Рекуррентные нейронные сети (Recurrent Neural Network, RNN) — класс моделей машинного обучения, основанный на использовании предыдущих состояний сети для вычисления текущего [5; 10].
Text Summarization with the use of Recurrent Neural Networks and...
Deep learning systems which are based on an attentional encoder and decoder models for machine translation are able to generate text summaries with
I use one component of LSTM decoder to create hidden states from word vectors of y. On every decoding step t, — algorithm uses an intra-temporal...
Механизмы работы нейронных сетей | Статья в журнале...
Сети LSTM обучаются с использованием алгоритма обратного распространения ошибок во
Из сетей LSTM можно строить многослойные нейронные сети, передавая выходную
После того, как модели будут готовы, Amazon Machine Learning позволяет легко получить предсказания...
Идентификация осложнений и неисправностей погружного...
В данной статье автор рассматривает возможности распознавания динамограмм с помощью глубоких нейронных сетей. Для анализа изображений динамограмм используются такие типы слоев как сверточный слой и слой LSTM.
Interactive methods of teaching in English lessons | Статья в журнале...
The essence of interactive learning is the special organization of the learning process, when all students are involved in the process of cognition. The joint activity of students in the process of mastering the teaching material means that each contributes its own individual contribution; there is...
The use of computer technologies in learning foreign languages
The introduction of computer technology in education provides an opportunity to use computer games in learning foreign languages, which contributes to more successful mastering of language and speech material in foreign language lessons.
Organization of distance learning in Moodle | Статья в журнале...
The introduction of distance learning necessitates a change of attitude in their activities the main subjects of the educational system — students and teachers. The process of transferring the sum of ready knowledge is transformed into a process of active, mainly independent search and knowledge...
Modern methods and approaches used for motivating young learners in...
Such a discussion or describing a thing could form the basis of practice for adjectives, comparatives, superlatives, question forms, and so on. What children really like and is interesting for them are pictures, stories and games. Pictures are colourful and attract the eyes — they are kind of visual...
Technologies of interactive training in lessons of foreign languages
The essence of interactive learning is that the learning process is organized in such a way that practically all learners are involved in the process of cognition, they have the opportunity to understand and reflect on what they know and think.
Похожие статьи
GRU и LSTM: современные рекуррентные нейронные сети
Рекуррентные нейронные сети (Recurrent Neural Network, RNN) — класс моделей машинного обучения, основанный на использовании предыдущих состояний сети для вычисления текущего [5; 10].
Text Summarization with the use of Recurrent Neural Networks and...
Deep learning systems which are based on an attentional encoder and decoder models for machine translation are able to generate text summaries with
I use one component of LSTM decoder to create hidden states from word vectors of y. On every decoding step t, — algorithm uses an intra-temporal...
Механизмы работы нейронных сетей | Статья в журнале...
Сети LSTM обучаются с использованием алгоритма обратного распространения ошибок во
Из сетей LSTM можно строить многослойные нейронные сети, передавая выходную
После того, как модели будут готовы, Amazon Machine Learning позволяет легко получить предсказания...
Идентификация осложнений и неисправностей погружного...
В данной статье автор рассматривает возможности распознавания динамограмм с помощью глубоких нейронных сетей. Для анализа изображений динамограмм используются такие типы слоев как сверточный слой и слой LSTM.
Interactive methods of teaching in English lessons | Статья в журнале...
The essence of interactive learning is the special organization of the learning process, when all students are involved in the process of cognition. The joint activity of students in the process of mastering the teaching material means that each contributes its own individual contribution; there is...
The use of computer technologies in learning foreign languages
The introduction of computer technology in education provides an opportunity to use computer games in learning foreign languages, which contributes to more successful mastering of language and speech material in foreign language lessons.
Organization of distance learning in Moodle | Статья в журнале...
The introduction of distance learning necessitates a change of attitude in their activities the main subjects of the educational system — students and teachers. The process of transferring the sum of ready knowledge is transformed into a process of active, mainly independent search and knowledge...
Modern methods and approaches used for motivating young learners in...
Such a discussion or describing a thing could form the basis of practice for adjectives, comparatives, superlatives, question forms, and so on. What children really like and is interesting for them are pictures, stories and games. Pictures are colourful and attract the eyes — they are kind of visual...
Technologies of interactive training in lessons of foreign languages
The essence of interactive learning is that the learning process is organized in such a way that practically all learners are involved in the process of cognition, they have the opportunity to understand and reflect on what they know and think.




