





Рекуррентные нейронные сети (Recurrent Neural Network, RNN) — класс моделей машинного обучения, основанный на использовании предыдущих состояний сети для вычисления текущего [5; 10]. Такие сети удобно применять в тех случаях, когда входные данные задачи представляют собой нефиксированную последовательность значений, как, например, текстовые данные, где текстовый фрагмент представлен нефиксированным количеством предложений, фраз и слов. Каждый символ в тексте, отдельные слова, знаки препинания и даже целые фразы — все это может являться атомарным элементом входной последовательности.
На каждом шаге обучения 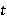 значение
значение 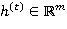 скрытого слоя рекуррентной нейронной сети вычисляется следующим образом:
скрытого слоя рекуррентной нейронной сети вычисляется следующим образом:
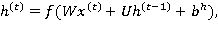
где 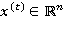 — входной вектор в момент времени (например, векторное представление текущего слова в текстовом фрагменте);
— входной вектор в момент времени (например, векторное представление текущего слова в текстовом фрагменте); 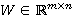 ,
, 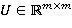 ,
, 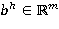 — обучаемые параметры рекуррентной нейронной сети;
— обучаемые параметры рекуррентной нейронной сети; 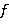 — функция нелинейного преобразования. Чаще всего в качестве нелинейного преобразования применяют одну из следующих функций: сигмоидальная функция (1), гиперболический тангенс (2), функция-выпрямитель (3):
— функция нелинейного преобразования. Чаще всего в качестве нелинейного преобразования применяют одну из следующих функций: сигмоидальная функция (1), гиперболический тангенс (2), функция-выпрямитель (3):
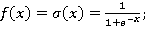 (1)
(1)
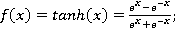 (2)
(2)
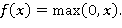 (3)
(3)
В простой рекуррентной нейронной сети (см. рис. 1) выходное значение 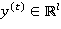 на текущем шаге вычисляется по формуле:
на текущем шаге вычисляется по формуле:
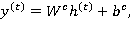
где 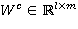 и
и 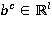 — обучаемые параметры.
— обучаемые параметры.
В 1997 году Зепп Хохрайтер (Sepp Hochreiter) и Юрген Шмидхубер (Jürgen Schmidhuber) представили новый подход, получивший название LSTM (Long Short-Term Memory — долгая краткосрочная память) [8]. Рекуррентные нейронные сети, основанные на этом подходе, имеет более продвинутый (и более сложный) способ вычисления 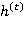 . Данный способ, помимо входных значений и предыдущего состояния сети, использует также фильтры (gates), определяющие, каким образом информация будет использоваться для вычисления как выходных значений на текущем слое
. Данный способ, помимо входных значений и предыдущего состояния сети, использует также фильтры (gates), определяющие, каким образом информация будет использоваться для вычисления как выходных значений на текущем слое 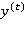 , так и значений скрытого слоя на следующем шаге
, так и значений скрытого слоя на следующем шаге 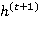 . Весь процесс вычисления для простоты упоминается как LSTM-слой (LSTM layer, LSTM unit).
. Весь процесс вычисления для простоты упоминается как LSTM-слой (LSTM layer, LSTM unit).
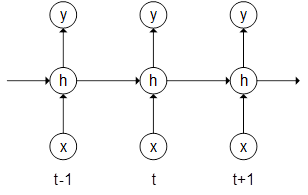
Рис. 1. Простая рекуррентная нейронная сеть
Рассмотрим подробнее структуру LSTM-слоя. Центральным понятием здесь является запоминающий блок (memory cell), который, наряду с состоянием сети 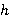 , вычисляется на каждом шаге, используя текущее входное значение
, вычисляется на каждом шаге, используя текущее входное значение 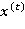 и значение блока на предыдущем шаге
и значение блока на предыдущем шаге 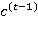 . Входной фильтр (input gate)
. Входной фильтр (input gate) 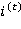 определяет, насколько значение блока памяти на текущем шаге должно влиять на результат. Значения фильтра варьируются от 0 (полностью игнорировать входные значения) до 1, что обеспечивается областью значений сигмоидальной функции:
определяет, насколько значение блока памяти на текущем шаге должно влиять на результат. Значения фильтра варьируются от 0 (полностью игнорировать входные значения) до 1, что обеспечивается областью значений сигмоидальной функции:
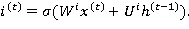 (4)
(4)
«Фильтр забывания» (forget gate) позволяет исключить при вычислениях значения памяти предыдущего шага:
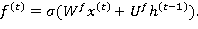 (5)
(5)
На основе всех данных, поступающих в момент времени 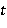 (а именно, ,
(а именно, , 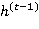 и ), вычисляется состояние блока памяти
и ), вычисляется состояние блока памяти 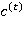 на текущем шаге, используя фильтры (4) и (5):
на текущем шаге, используя фильтры (4) и (5):
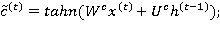
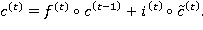 (6)
(6)
Выходной фильтр (output gate) аналогичен двум предыдущим и имеет вид:
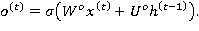 (7)
(7)
Итоговое значение LSTM-слоя определяется выходным фильтром (7) и нелинейной трансформацией над состоянием блока памяти (6):
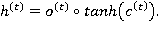
В 2014 году в работе [15] была представлена модель GRU (Gated Recurrent Unit), основанная на тех же принципах, что и LSTM, но использует меньше фильтров и операций для вычисления 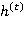 [6]. Фильтр обновления (update gate)
[6]. Фильтр обновления (update gate) 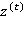 и фильтр сброса состояния (reset gate)
и фильтр сброса состояния (reset gate) 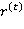 вычисляются по следующим формулам:
вычисляются по следующим формулам:
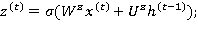 (8)
(8)
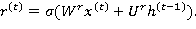 (9)
(9)
Выходное значение вычисляется на основе промежуточного значения 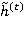 , которое, при помощи фильтра сброса состояния (9), определяет, какие значения предыдущего шага следует исключить (здесь можно видеть прямую аналогию с фильтром забывания из LSTM):
, которое, при помощи фильтра сброса состояния (9), определяет, какие значения предыдущего шага следует исключить (здесь можно видеть прямую аналогию с фильтром забывания из LSTM):
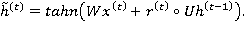 (10)
(10)
Используя фильтр обновления (8) и промежуточное значение (10), имеем:
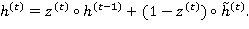
Сходства и различия между LSTM- и GRU-слоями можно изобразить схематически (см. рис. 2)
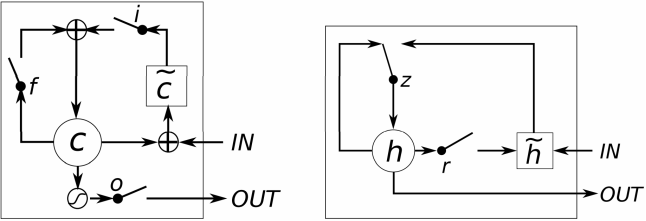
Рис. 2. Схематическое представление LSTM (слева) и GRU (источник: [6])
Несмотря на то, что в целом развитие вычислительных моделей идет от простых к более сложным, более простая модель GRU появилась на 17 лет позже модели LSTM. Сама формулировка Gated Recurrent Unit является более обобщающей и подразумевает включение в себя LSTM как частного случая. Однако, это не более чем занимательный исторический факт. Семейство рекуррентных нейронных сетей, использующих фильтры (gates), благодаря LSTM, за свою историю получило активное развитие в следующих областях [12]:
- распознавание рукописного текста [1; 3; 4];
- моделирование языка [7];
- машинный перевод [2; 15];
- обработка аудио [13], видео [11] и изображений [14];
- анализ тональности и классификация текстов [16];
- целый ряд других областей, использующих алгоритмы машинного обучения.
Стоит отметить, что такое активное внимание к рассмотренному семейству моделей в настоящее время обусловлено, в частности, высокими показателями их эффективности во многих задачах. Как и другие рекуррентные нейронные сети, LSTM и GRU (особенно двух- и многослойные) характеризуются достаточно сложной процедурой обучения. Значительно ускорить процессы обучения глубоких нейросетей позволяют графические процессоры (Graphics Processing Unit, GPU), что наглядно демонстрируется активной реализацией (и оптимизацией) описанных рекуррентных моделей под GPU-вычисления [9]
В заключение можно констатировать, что рекуррентные нейросетевые модели, активно представленные в последнее время в виде LSTM и GRU, являются эффективными и перспективными алгоритмами машинного обучения для широкого спектра прикладных задач.
Литература:
1. A novel connectionist system for unconstrained handwriting recognition / A. Graves [et al.] // Pattern Analysis and Machine Intelligence, IEEE Transactions on. — 2009. — Vol. 31, no. 5. — Pp. 855–868.
2. Addressing the Rare Word Problem in Neural Machine Translation / T. Luong [et al.] // arXiv preprint arXiv:1410.8206. — 2014.
3. Doetsch P., Kozielski M., Ney H. Fast and robust training of recurrent neural networks for offline handwriting recognition // Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on. — IEEE. 2014. — Pp. 279–284.
4. Dropout improves recurrent neural networks for handwriting recognition / V. Pham [et al.] // Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on. — IEEE. 2014. — Pp. 285–290.
5. Elman J. L. Finding structure in time // Cognitive science. — 1990. — Vol. 14, no. 2. — Pp. 179–211.
6. Empirical evaluation of gated recurrent neural networks on sequence modeling / J. Chung [et al.] // arXiv preprint arXiv:1412.3555. — 2014.
7. Gated feedback recurrent neural networks / J. Chung [et al.] // arXiv preprint arXiv:1502.02367. — 2015.
8. Hochreiter S., Schmidhuber J. Long short-term memory // Neural computation. — 1997. — Vol. 9, no. 8. — Pp. 1735–1780.
9. Hwang K., Sung W. Single stream parallelization of generalized LSTM-like RNNs on a GPU // arXiv preprint arXiv:1503.02852. — 2015.
10. Jordan M. I. Serial order: A parallel distributed processing approach // Advances in psychology. — 1997. — Vol. 121. — Pp. 471–495.
11. Long-term recurrent convolutional networks for visual recognition and description / J. Donahue [et al.] // arXiv preprint arXiv:1411.4389. — 2014.
12. LSTM: A Search Space Odyssey / K. Greff [et al.] // arXiv preprint arXiv:1503.04069. — 2015.
13. Multi-resolution linear prediction based features for audio onset detection with bidirectional LSTM neural networks / E. Marchi [et al.] // Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. — IEEE. 2014. — Pp. 2164–2168.
14. Novel approaches for face recognition: template-matching using dynamic time warping and LSTM Neural Network Supervised Classification / A. L. Levada [et al.] // Systems, Signals and Image Processing, 2008. IWSSIP 2008. 15th International Conference on. — IEEE. 2008. — Pp. 241–244.
15. On the properties of neural machine translation: Encoder-decoder approaches / K. Cho [et al.] // arXiv preprint arXiv:1409.1259. — 2014.
16. Tai K. S., Socher R., Manning C. D. Improved semantic representations from tree-structured long short-term memory networks // arXiv preprint arXiv:1503.00075. — 2015.
