





В настоящее время человечество производит десятки терабайт информации в день: фотографии, текст, логи серверов и т. д. На любом предприятии каждое действие записывается в базу данных. Эту информацию можно и нужно обрабатывать. Полученные данные используются для построения статистик, оптимизации направления бизнеса, привлечения новых клиентов и повышения продаж за счёт «персонализации» услуг.
Современные требования к методам анализа данных:
а) большие объёмы данных (гигабайты, терабайты);
б) разреженность, низкий коэффициент корреляции;
в) простые и понятные результаты;
г) быстрые инструменты анализа.
Традиционный метод — математическая статистика, неприменим к текущим задачам анализа, т. к. в его основе используется концепция усреднения по выборке, приводящая к операциям над фиктивными величинами. Относительно новая область науки анализа данных — Data Mining занимается поиском, разработкой и оптимизаций методов обработки данных.
Сфера применения Data Mining не ограничена — везде, где есть данные, можно найти «скрытые знания». Зачастую прибыль от использования систем обработки и анализа данных в десятки раз превышает стоимость их внедрения. Вот лишь несколько направлений, в которых обработка данных будет полезна:
а) анализ потребительской корзины в интернет магазинах — для повышения продаж нужно уметь предсказывать желания клиента, на основе его поведения и поведения похожих на него пользователей;
б) прогнозирование изменения клиентуры — важно уметь предсказать отток клиентов и, как следствие, снижение прибыли. Если вовремя обнаружить эту проблему, то можно значительно сократить убытки;
в) сегментация рынка — разделяя клиентов на категории, можно оптимизировать политику ведения бизнеса для каждого типа клиентов.
Одно из применений Data Mining — рекомендательные системы. Это информационные системы, задача которых, предложить пользователю действия, услуги или товары на основе предыдущих предпочтений его или пользователей, похожих на него по купленным товарам/услугам.
Алгоритмы фильтрации, используемые в рекомендательных системах, делятся на два типа:
а) content-based фильтрация — собирает информацию (демографические данные, музыкальный жанр, анкета пользователя) для создания профиля по каждому клиенту или товару;
б) коллаборативная фильтрация — основывается на поведении пользователя в прошлом. Каждому пользователю по данным всех транзакций ставятся в соответствие пользователи с похожей историей покупок/действий.
На данный момент, наиболее популярной считается коллаборативная фильтрация.
Алгоритм работы
Для расчета рекомендаций необходимо сформировать таблицу, в которой показано, какие товары/услуги клиент приобрёл, а какие нет. Данная таблица называется матрицей кросс-табуляции. Формирование происходит из таблицы транзакций, в которой содержатся данные о покупках каждого клиента с момента начала использования сервиса/магазина. Алгоритм получения и агрегация данных для построения матрицы кросс-табуляции, зависит от структуры базы данных и в данной статье не приводится.
Таблица 1
Пример матрицы кросс-табуляции
|
ID клиента |
Услуга 1 |
Услуга 2 |
Услуга 3 |
|
154 |
1 |
1 |
1 |
|
155 |
1 |
0 |
0 |
Таким образом, по каждому столбцу таблицы, начиная со второго, можно построить бинарные вектора, которые будут соответствовать услугам в этих столбцах. Полученные вектора можно сравнивать и находить наиболее близкие друг к другу товары — те, которые наиболее часто приобретались вместе. Также бинарные вектора можно построить и по строкам, тогда при их сравнении будет рассчитываться мера «похожести» покупателей друг на друга — насколько похожи были их покупки.
Чтобы среди всех векторов для выбранной услуги найти наиболее похожие, необходимо вычислить меру сравнения с другими векторами. Можно использовать следующие меры:
а) Косинусная мера;
б) Коэффициент корреляции Пирсона;
в) Евклидово расстояние;
г) Коэффициент Танимото;
д) Манхэттенское расстояние.
В рекомендательных системах наиболее часто используются косинусная мера и коэффициент корреляции Танимото. В данном описании алгоритма происходит сравнение товаров при помощи косинусной меры. Данная мера хорошо подходит для данных, в которых неизвестны оценки пользователей по каждому товару, но известен факт покупки.
Косинусная мера для двух векторов — это косинус угла между ними, который определяется как их скалярное произведение, деленное на длину каждого из двух векторов:
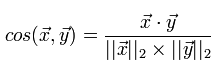
Блок-схема предлагаемого алгоритма представлена на рисунке 1.
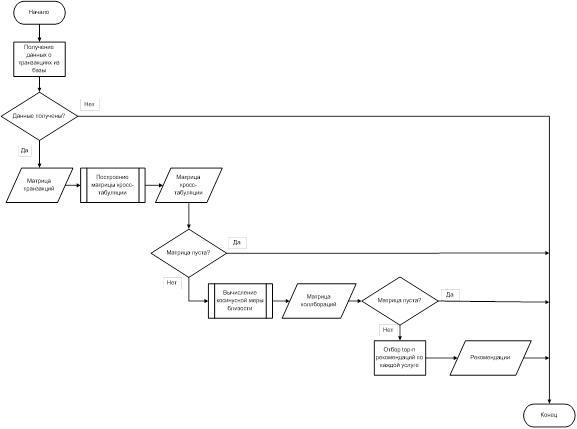
Рис. 1. Схема алгоритма работы вычисления рекомендаций
Для сбора данных необходимо сформировать несколько запросов к двум таблицам. На рисунке 2 представлена ER-диаграмма данных таблиц (в ней указаны только те строки, которые необходимые для расчёта рекомендаций).
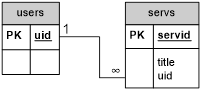
Рис. 2. ER-диаграмма
При анализе и выработке рекомендаций, промежуточные данные могут храниться как в оперативной памяти, так и в базе данных.
Для построения таблицы, в которой будет отражена информация о близости каждого товара к другим, необходимо вычислить меры близости каждого вектора с остальными. Полученная симметричная матрица называется матрицей коллабораций. В таблице 2 представлен пример матрицы коллабораций, по которой будут выбираться рекомендации. При использовании косинусной меры близости значения в ячейках этой матрицы лежат в отрезке [-1;1], где максимальная близость выражается числом 1.
Таблица 2
Пример матрицы коллабораций
|
Название услуги |
Услуга 1 |
Услуга 2 |
Услуга 3 |
|
Услуга 1 |
0 |
0.01345 |
0.08345 |
|
Услуга 2 |
0.01345 |
0 |
0.7504 |
|
Услуга 3 |
0.08345 |
0.7504 |
0 |
В данной статье был предложен алгоритм расчёта рекомендаций на основе метода коллаборативной фильтрации при помощи косинусной меры близости. Используя этот алгоритм можно повысить уровень продаж интернет-магазинов, оптимизировать работу компании и т. п.
Литература:
1. Машинное обучение (курс лекций, К. В. Воронцов).
2. Jared Dean, «Big data, data mining and machine learning»
3. https://www.ibm.com/developerworks/ru/library/os-recommender1/
4. http://www.ibm.com/developerworks/ru/library/os-recommender2/
5. http://logic.pdmi.ras.ru/~sergey/teaching/mlstc12/15-recommender.pdf
