





Обычно частотные словари строятся на основе корпусов текстов: берется набор текстов, представительный для языка в целом, для некоторой предметной области или данного автора и из него извлекаются словоформы, леммы и части речи (последние извлекаются в случае, если корпус имеет морфологическую разметку). Проблемы при создании частотных словарей заключаются в воспроизводимости (будут ли результаты идентичны на другом аналогичном корпусе), всплесках частоты отдельных слов (частота слова в одном тексте может повлиять на его позицию во всем частотном словаре), сложности определения позиции менее частотных слов, что не дает возможности ранжировать их рационально. Все эти проблемы связаны с тем, что со статистической точки зрения язык представляет собой большое количество редких событий (Закон Ципфа), в результате чего небольшое количество слов встречается очень часто, а подавляющее большинство слов имеют очень невысокую частоту.
Целью данной работы является разработка алгоритмов для построения частотных словарей. При выборе методики решения были рассмотрены два способа представления данных: двоичные деревья и хэш-таблица [2].
Хеш-таблица — структура данных, реализующая интерфейс ассоциативного массива. Представляет собой эффективную структуру данных для реализации словарей, а именно, она позволяет хранить пары ключ-значение и выполнять три операции: операцию добавления новой пары, операцию поиска и операцию удаления пары по ключу.
Двоичное дерево — древовидная структура данных, в которой каждый узел имеет не более двух потомков (детей). Как правило, первый называется родительским узлом, а дети называются левым и правым наследниками.
По результатам сравнения для реализации был выбран метод на основе построения хеш-таблицы как наиболее оптимальный для решения данной задачи. Для организации хеш-таблицы целесообразно использовать тип данных — структуру. В ней необходимо определить поле для ключа, поле для значения и поле для ссылки на следующий элемент.
Код созданной структуры выглядит следующим образом:

В качестве хеш-функции была выбрана Djb, потому что это простая и быстрая хэш-функция общего назначения. Так же из достоинств функции можно отметить хорошее распределение и простоту конструкции. Данная функция разработанная профессором Дэниэлом Берштейном, американским математиком и программистом. Она не является криптографически-безопасной, возвращает 32-разрядное беззнаковое число в качестве хеш-суммы. Код используемой хеш-функции выглядит следующим образом (<< — операция побитого сдвига влево):

Была реализована функция добавления пары ключ-значение. Задачами данной функции являются выделение памяти для ключа и значения и занесение данных, если элемента с таким ключом нет, или обновление значения, если элемент с таким значением есть. Алгоритм функции добавления пары ключ-значение приведен на рисунке 1.
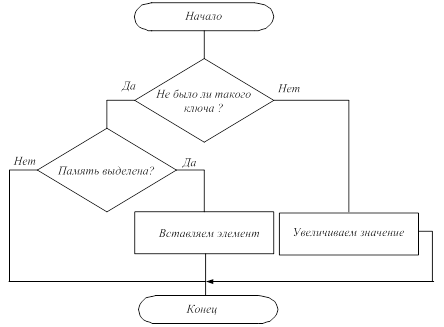
Рис. 1. Алгоритм функции добавления пары ключ-значение
Также была реализована функция поиска значения по ключу, она позволяет проверить существование элемента с заданным ключом. Функция возвращает либо указатель на элемент, если элемент существует, либо нулевой указатель при отсутствии искомого элемента. Аргумент функции это ключ, по которому ведется поиск. Вначале вычисляется хеш ключа. Далее цикл последовательно сравнивает ключи элементов цепочки с загруженным ключом. При их совпадении сравнивание прекращается и выдается указатель на эту структуру. Если же элемент не найден, то возвращается значение NULL. Алгоритм функции поиска значения по ключу приведен на рисунке 2.
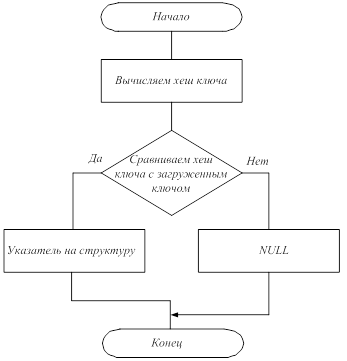
Рис. 2. Алгоритм функции поиска значения по ключу
Также была реализована функция удаления значения по ключу. Вначале вычисляется хеш ключа. Далее проверяется существование элемента с данным хешем. В случае существования элемента проверяется совпадение его ключа и заданного ключа. При наличии совпадения происходит удаление элемента и восстановление целостности списка. Во всех остальных случаях происходит возврат из функции. Алгоритм функции удаления значения по ключу приведен на рисунке 3.
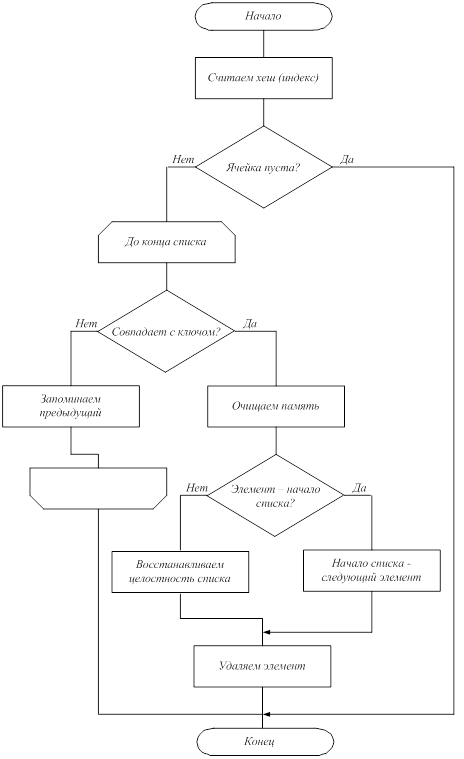
Рис.3. Алгоритм функции удаления значения по ключу
По итогам разработки алгоритмов было реализовано программное обеспечение, которое будет анализировать коллекцию текстов на английском языке и автоматически формировать частотный словарь.
Применение разработанного программного обеспечения дает возможность повысить эффективность и качество обучения студентов вузов английскому языку, а также сделать это обучение профессионально-ориентированным и коммуникативно-направленным.
Литература:
1. Алексеев П. М. Частотные словари: Учебное пособие. — СПб.: Изд-во С.-Петерб. Ун-та, 2001–156 с.
2. Ахо А. Структуры данных и алгоритмы/ А.Ахо, Д. Хопкрофт, Д. Ульман; пер. с англ. — М.: Вильямс, 2000. — 384 с.
