В последние десятилетия алгоритмы машинного обучения стали важным инструментом в различных областях науки и техники. Одним из наиболее популярных и эффективных методов является случайный лес (Random Forest). Этот метод используется для решения задач классификации и регрессии и отличается высокой точностью, устойчивостью к переобучению и способностью обрабатывать данные с большим числом признаков.
Ключевые слова: случайный лес, классификация данных, машинное обучение, тепловая карта, Python, Scikit-learn, прогнозирование.
In recent decades, machine learning algorithms have become important tools in various fields of science and engineering. One of the most popular and effective methods is the Random Forest. This method is used for solving classification and regression problems and is characterized by high accuracy, robustness against overfitting, and the ability to handle data with a large number of features.
Keywords: random forest, data classification, machine learning, heatmap, python, scikit-learn, prediction.
Основные концепции случайного леса
Случайный лес представляет собой ансамблевый метод, основанный на построении множества деревьев решений. Каждое дерево в ансамбле обучается на случайной подвыборке данных, а его узлы строятся с использованием случайного подмножества признаков. Такая стратегия позволяет снизить корреляцию между отдельными деревьями и улучшить общую производительность модели.
Процесс построения случайного леса можно разделить на несколько этапов. Во-первых, выполняется выборка с возвращением (bootstrap sampling), что означает, что некоторые образцы из обучающего набора данных могут быть выбраны несколько раз, в то время как другие могут быть не выбраны вовсе. Далее, для каждого узла дерева выбирается случайное подмножество признаков, и среди них выбирается тот, который лучше всего делит данные. Этот процесс повторяется до тех пор, пока дерево не достигнет заданной глубины или не будет выполнен другой критерий остановки.
После того как все деревья обучены, для классификации нового объекта используется метод голосования. Каждый классификатор в лесу делает свой прогноз, и итоговый результат определяется большинством голосов [1].
Преимущества и недостатки метода
Одним из основных преимуществ случайного леса является его способность обрабатывать большие объемы данных с высоким числом признаков, оставаясь при этом устойчивым к переобучению. Это достигается за счет случайности, вводимой на каждом этапе построения леса. Еще одно важное достоинство заключается в том, что случайный лес автоматически оценивает важность признаков, что может быть полезным для отбора переменных и интерпретации модели [2].
Пример применения случайного леса для классификации
Рассмотрим пример использования случайного леса для классификации данных на наборе данных о цветках ириса (Iris dataset). Этот набор данных является классическим примером для задач классификации и содержит четыре признака (длина и ширина чашелистиков и лепестков) для трех видов ирисов [2].
Для начала импортируем необходимые библиотеки и загрузим данные. На рисунке 1 представлен процесс импорта данных.
Рис. 1. Импорт данных
Теперь создадим и обучим модель случайного леса (рис. 2).

Рис. 2. Обучение модели
После обучения модели проведем прогнозирование и оценим качество классификации (рис. 3).
Рис. 3. Обучение модели
Результаты включают отчет о классификации, который показывает точность, полноту и F1-меру для каждого класса, а также матрицу ошибок, иллюстрирующую количество верных и неверных классификаций.
Визуализация результатов
Для наглядности построим тепловую карту матрицы ошибок с помощью библиотеки seaborn (рис. 4).

Рис. 4. Визуализация данных
Эта тепловая карта позволяет легко увидеть, где модель ошиблась, и насколько точны её предсказания для каждого класса (рис. 5).
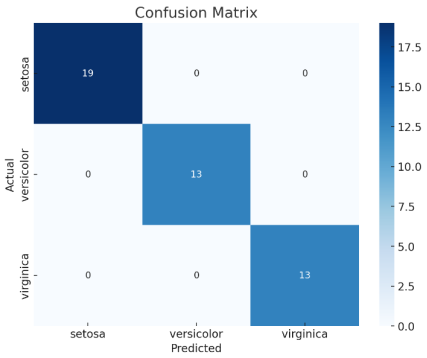
Рис. 5. Тепловая карта
Литература:
- Data Mining. Извлечение информации из Facebook[*], Twitter, LinkedIn, Instagram*, GitHub. — СПб.: Питер, 2020. — 464 с.: ил.
- Data Science. Наука о данных с нуля: Пер. с англ. — 2-е изд., перераб. и доп. — СПб.: БХВ-Петербурr, 2021. — 416 с.: ил.
[*]Instagram и Facebook, продукты компании Meta, которая признана экстремистской организацией в Росси

