В данной статье представлен краткий обзор на компоненты модуля формирования отчетов в информационной системе страховой компании.
Ключевые слова : информационная система, страховая компания, Greenplum, Apache Nifi, Apache Superset
Финансовые отчеты являются значимым инструментом для оценки финансового состояния и результативности страховой компании. Финансовые отчеты играют немаловажную роль в процессе управления и принятии решений.
Текущий модуль формирования отчетов в информационной системе страховой компании сталкивается со следующими проблемами: несовместимость исходного хранилища на базе с требованиями отчетности; дублирование и несовпадение данных в отчетах в различных платформах для визуализации данных. Компания стремится решить данные проблемы и обеспечить плавный переход всей отчетности на Open Source — решения.
В базе данных MS SQL Server 2016, которая является исходной базой для разрабатываемого хранилища, данные хранятся в таблицах, где некоторые поля содержат информацию в формате JSON-файлов. MS SQL Server не является идеальным выбором для работы с JSON-файлами из-за ограничений встроенной поддержки для JSON. Компании была необходима база данных, которая поддерживала бы работу с JSON-файлами, и была заточена под решения задач отчетности. Еще компании необходимо было реализовать ETL-процесс для синхронизации данных с базой-источником. Вся отчетность должна быть визуализирована в удобной платформе.
Схема разработанного модуля представлена на рис. 1. Данные забираются из MS SQL, ETL-процесс организован в Apache NiFi, целевой базой является Greenplum Database и средством визуализации Apache Superset.
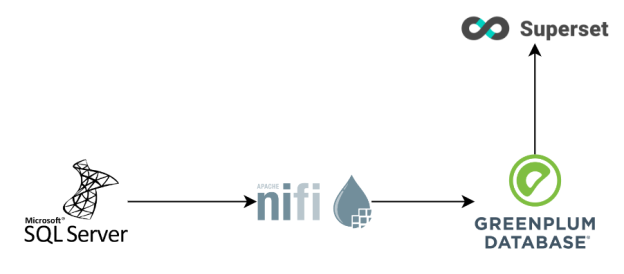
Рис. 1. Схема взаимодействия компонентов модуля
Greenplum– это сервер баз данных с массивно-параллельной обработкой (MPP), который предназначен для работы с хранилищами данных нового поколения и выполнения крупномасштабной аналитической обработки. Greenplum реализует концепцию «Shared Nothing», когда узлы кластера, которые взаимодействуют для выполнения вычислительных операций, не разделяют ресурсы: каждый из них имеет собственную память, операционную систему и жесткие диски. Он автоматически разделяет данные и выполняет параллельные запросы, позволяя кластеру серверов функционировать как единый суперкомпьютер базы данных, работающий гораздо быстрее, чем традиционные базы данных [1].
Преимущества использования Greenplum:
- Высокая эффективность: база обеспечивает одновременную обработку данных в больших объемах, что позволяет проводить запросы и аналитические операции на огромных объемах данных с высокой скоростью. Это уменьшает время выполнения сложных аналитических запросов и повышает производительность работы с данными.
- Горизонтальное масштабирование: Greenplum позволяет легко масштабировать кластер серверов для обработки больших объемов данных. Он автоматически распределяет данные и запросы между узлами кластера, обеспечивая высокую доступность и отказоустойчивость.
- Гибкость и расширяемость: Greenplum предлагает обширный выбор функций и возможностей для работы с данными, включая поддержку различных типов данных, таких как JSON, CSV, TXT, индексацию и партицирование данных, агрегацию и транзакции. Он также легко интегрируется с другими инструментами и разнообразными платформами, что позволяет создавать как сложные аналитические решения, так и
Apache NiFi — это инструмент для обработки и передачи данных. Он предоставляет графический интерфейс для создания, настройки и мониторинга потоков данных. NiFi позволяет достаточно просто интегрировать различные источники данных, преобразовывать и обогащать данные, а также управлять ошибочными данными и поддерживать безопасность ETL-процессов [2].
Apache NiFi имеет хорошо продуманную архитектуру. После извлечения данных из источников они представляются в виде файла потока внутри системы NiFi. NiFi имеет интуитивно понятный графический веб-интерфейс для создания и управления потоками данных, более 260 встроенных процессоров и коннекторов готовы к использованию после их быстрой настройки, что позволяет его использовать для сопряжения практически с любыми типами источников и потребителей данных. Возможность работать в асинхронном режиме обеспечивает высокую пропускную способность, удобную обработку некорректны данных. Существует возможность версионного контроля процессорных групп или процессов в Apache NiFi.
Apache Superset — это платформа для исследования и визуализации данных с открытым исходным кодом, которая позволяет пользователям создавать интерактивные информационные панели, отчеты и визуализации данных. Superset предоставляет удобный интерфейс для изучения и анализа данных из различных источников, включая базы данных, хранилища данных и сторонние платформы [3].
Superset предлагает большой выбор встроенных типов визуализации, которые покрывают базовую потребность в визуализации. Типы основных визуализаций включают в себя диаграммы, графические изображения, карты и таблицы. Superset также обеспечивает поддержку запросов на основе SQL и позволяет пользователям писать пользовательские SQL-запросы для выполнения сложных вычислений и преобразований своих данных. Пользователи могут выбирать из богатой библиотеки типов визуализации и настраивать их в соответствии со своими потребностями. Они также могут создавать интерактивные информационные панели, объединяя несколько визуализаций в одно представление. Информационными панелями можно поделиться с другими пользователями, что позволяет проводить совместный анализ данных и принимать решения.
Литература:
- Мазитов, С. Обзор Greenplum Database. Назначение и ключевые преимущества / С. Мазитов. — Текст: электронный // вАЙТИ: [сайт]. — URL: https://vaiti.io/greenplum-database-naznachenie-i-klyuchevye-preimushhestva/ (дата обращения: 30.05.2024).
- Шамаев, И. Учебное пособие по Apache NiFi Tutorial (Guide, Инструкция) / И. Шамаев. — Текст: электронный // Ivan Shamaev: [сайт]. — URL: https://ivan-shamaev.ru/apache-nifi-tutorial-guide/ (дата обращения: 30.05.2024).
- Современная BI для динамичных команд. — Текст: электронный // Apache Superset: [сайт]. — URL: https://superset-bi.ru/ (дата обращения: 30.05.2024).

