В статье автор исследует применение векторизации слов для нечеткого поиска в вопросно-ответных системах, путем улучшения точности через современные подходы к векторизации слов и поиск семантически близких слов.
Ключевые слова : NLP, Bag of Words, Word2Vec, семантика.
Современные системы вопросно-ответной обработки информации сталкиваются с проблемами, связанными с разнообразием и нечеткостью формулировок пользовательских запросов. Вопросы, содержащие синонимы, множественные интерпретации или нечеткие конструкции, усложняют задачу точного выделения контекста и предоставления релевантных ответов. В данном контексте, эволюция методов векторизации слов и классификации вопросов становится важным аспектом развития вопросно-ответных систем.
Традиционные подходы, такие как Bag of Words [1], демонстрировали свою эффективность, однако они ограничены в учете семантической близости и контекста вопросов. Для решения этой проблемы автор предлагает подход, основанные на использовании контекстуализированных векторных представлениях.
В данной статье исследуется применение современных методов векторизации слов и классификации вопросов с акцентом на учете нечеткости в формулировках, путем расширения модели Bag of Words.
Цель — предложить эффективные решения, способные учесть неопределенность в формулировках вопросов и обеспечить более точные ответы, при минимальных вычислительных ресурсах.
Традиционный подход Bag Of Words
В статье [2] «Разработка вопросно-ответной системы с использованием машинного обучения» авторы рассматривают задачу создания автоматизированной вопросно-ответной системы, исследуя несколько подходов к решению этой задачи, включая метод векторного представления слов и метод синтаксических деревьев. Авторы применяют такие технологии как Bag Of Words, NLTK, и pymorphy2. Рассмотрим традиционный подход классификации, основанный на технологии Bag Of Words.
Мешок слов (Bag of Words) — это упрощенное представление текста, которое применяется в обработке естественных языков и информационном поиске [1]. Модель «мешка слов» представляет текст в виде мультимножества слов, игнорируя порядок слов и грамматику. В этой модели каждый текст (предложение или документ) представляется как набор его слов, учитывая только их количество [1]. Это удобно для методов классификации документов, где частотность вхождения слова используется как признак для обучения классификатора.
Пример реализации Мешка слов, есть два простых документа:
Документ 1: «Иван любит смотреть фильмы. Мария тоже любит фильмы».
Документ 2: «Иван также любит смотреть футбольные матчи».
Для каждого документа строим список его слов:
Документ 1: «Иван», «любит», «смотреть», «фильмы», «Мария», «тоже»
Документ 2: «Иван», «также», «любит», «смотреть», «футбольные», «матчи».
Затем создаем объекты, представляющие мешок слов:
Мешок слов для Документа 1 (BoW1): {«Иван»: 1, «любит»: 2, «смотреть»: 1, «фильмы»: 2, «Мария»: 1, «тоже»: 1}
Мешок слов для Документа 2 (BoW2): {«Иван»: 1, «также»: 1, «любит»: 1, «смотреть»: 1, «футбольные»: 1, «матчи»: 1}
Если объединить эти два документа, получим мешок слов для третьего документа:
Мешок слов для Документа 3 (BoW3): {«Иван»: 2, «любит»: 3, «смотреть»: 2, «фильмы»: 2, «Мария»: 1, «тоже»: 1, «также»: 1, «футбольные»: 1, «матчи»: 1}
В алгебре логике «объединение» двух документов — это дизъюнктное объединение, суммирующее кратности элементов.
Мешок слов используется для формирования признаков, чаще всего его используют чтобы найти абсолютную частотность слов в тексте. Например, можно построить вектора абсолютных частотностей слов для каждого документа:
Документ 1: [1, 2, 1, 2, 1, 1, 0, 0, 0]
Документ 2: [1, 1, 1, 0, 0, 0, 1, 1, 1]
Каждое число в векторе соответствует количеству появлений соответствующего слова в тексте.
Word 2 Vec как семантический анализатор
В области обработки естественного языка Bag of Words (мешок слов), является мощным методом анализа текста. Однако классический подход не учитывает семантическую информацию о словах, что может привести к потере важной информации при анализе текста. Для преодоления этого ограничения был предложен и реализован расширенный алгоритм Bag of Words, который использует технологию Word2Vec [3].
Word2Vec — это метод обработки естественного языка, который преобразует слова в векторы в многомерном пространстве таким образом, что семантически близкие слова имеют близкие векторные представления [3]. Это позволяет улавливать семантические свойства слов и их взаимосвязи на основе контекста, в котором они употребляются.
Алгоритм Word2Vec основан на предположении, что слова, которые часто встречаются в похожих контекстах, имеют схожие смысловые значения. Для обучения векторных представлений слов используется нейронная сеть, которая на основе корпуса текстовых данных предсказывает контекст слова или слово по его контексту. После обучения модели Word2Vec каждое слово из словаря представлено вектором определенной размерности. В дальнейшем, эти вектора можно использовать для задач обработки текста, поиск семантически близких слов, анализ смысла предложений, кластеризация текстов и другие.
Рассмотрим математическую модель обучения Word2Vec, используя простейшую архитектуру — Continuous Bag of Words (CBOW) и Skip-gram [3].
- Continuous Bag of Words (CBOW)
CBOW — это модель, которая пытается предсказать целевое слово на основе контекста, в котором оно находится. Для этого CBOW использует среднее значение векторов контекстных слов, входными данными в таком случае являются контекстные слова вокруг целевого слова [3]. Например, если у нас есть предложение «я люблю гулять в парке», и целевым словом является «гулять», контекстными словами могут быть «я«, «люблю», «в«, «парке». Для каждого контекстного слова берется его векторное представление, затем вычисляется среднее значение векторов всех контекстных слов, а полученное среднее значение векторов контекстных слов подается на вход нейронной сети. Нейронная сеть предсказывает вероятности для каждого слова из словаря в качестве целевого слова. Вероятности рассчитываются с использованием функции softmax. Модель обучается минимизировать ошибку между предсказанными вероятностями и истинными метками (one-hot encoding [4] целевого слова) с помощью метода обратного распространения ошибки.
Пусть дано предложение
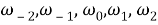
где
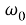
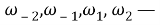
Входные векторы:
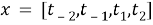
где каждый
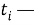
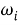
Весовая матрица: W размерности V×N ,
где V — размер словаря, N — размерность векторов.
Преобразование входных векторов:
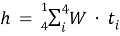
Предсказание целевого слова:
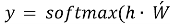
где
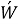
- Skip-gram
Skip-gram — это модель, которая пытается предсказать контекстные слова на основе целевого слова, т. е. действует обратно CBOW. Входными данными здесь является целевое слово [3]. Каждое слово представляется в виде вектора, например, с использованием one-hot encoding [4]. Входное слово подается на вход нейронной сети, которая пытается предсказать вероятности для всех контекстных слов из словаря на основе данного целевого слова, для вычисления вероятностей здесь также используется функция softmax.
Пусть дано целевое слово
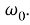
Входной вектор:
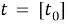
где
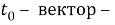
Преобразование входного вектора
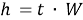
Предсказание целевого слова:
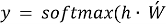
где
На рисунке 1 представлена структурная схема работы алгоритма CBOW и Skip-gram.
![Схема работы алгоритма CBOW и Skip-gram [2]](https://articles-static-cdn.moluch.org/articles/j/112168/images/112168.015.png)
Рис. 1. Схема работы алгоритма CBOW и Skip-gram [2]
Расширенный Bag Of Words
Алгоритм расширенного Bag of Words использует Word2Vec для оценки семантической схожести между словами в тексте. Рассмотрим подробнее шаги этого алгоритма:
Шаг первый, формализация текста. Пусть дан текст
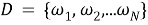
где каждый
Шаг второй, нормализация. Для каждого слова
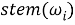
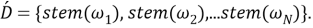
Третьим шагом является создание мешка слов. Пусть имеется набор всех возможных слов:
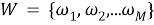
где
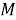
Создаем мешок слов
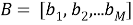
где
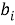
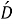
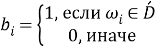
Шаг четвертый, поиск семантической схожести. Для каждого слова
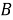
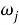
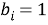
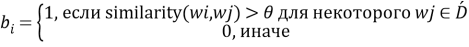
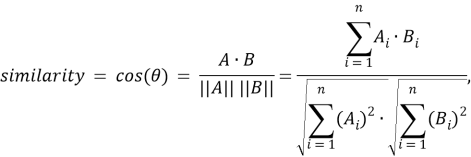
где
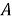
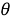
На последнем шаге возвращаем полученный мешок слов
На рисунках 2 и 3 визуализировано сравнение стандартной и расширенной моделей Bag Of Words.

Рис. 2 Схема работы стандартной модели Bag Of Words

Рис. 3 Схема работы расширенного Bag Of Words
Таким образом, модель расширенного Bag of Words с использованием Word2Vec для поиска семантической близости позволяет активировать триггеры, недоступные стандартной модели.
Результаты исследования
Для тестирования расширенного Bag of Words был создан корпус часто задаваемых вопросов абитуриентов при поступлении в университет, содержащий 20 тем для классификации с двумя примерами для каждого класса, и 100 тестовых примеров. Обучение проводится на 3-х моделях, применяя семантическое сопоставление на разных этапах:
model_with_study_w2v — модель с применением Word2Vec на этапе обучения.
model_with_answer_w2v — модель с применением Word2Vec на этапе предсказания.
model_with_w2v — модель с применением Word2Vec и на этапе обучения и предсказания.
Структура всех трех моделей представляют собой простую многослойную нейронную сеть (MLP), состоящую из трех слоев: входного, двух скрытых и выходного. Размерность входа определяется параметром, который указывает на количество слов в обучающей выборке, при тестировании это значение составило 100 элементов. Два скрытых слоя, по 16 нейронов на каждом. Для каждого скрытого слоя применяется линейное преобразование с последующей функцией активации ReLU. Выходной слой состоит из одного слоя с 20 нейронами. В данном случае, поскольку это вероятностная классификационная задача, на выходном слое не применяется функция активации, вместо него используется линейное преобразование.
Результаты проведенных исследований представлены на рисунках 4–5.
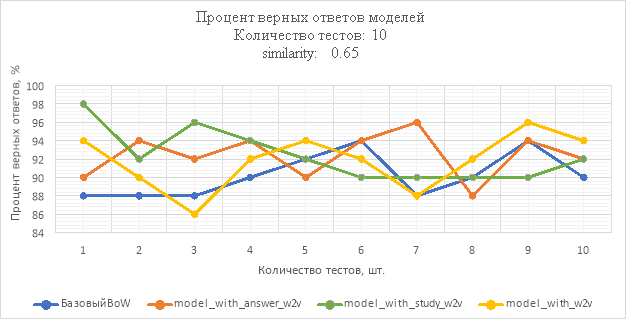
Рис. 4. Процент верных ответов моделей при similarity: 0.65
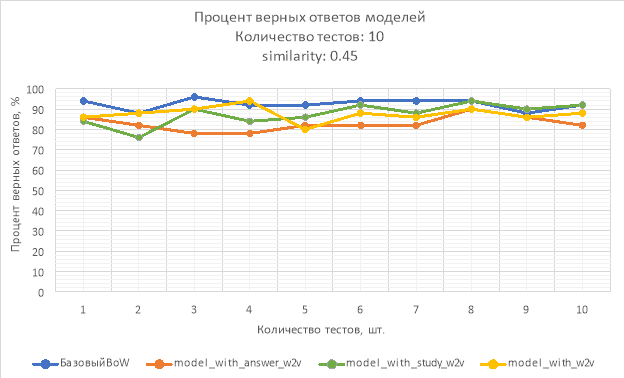
Рис. 5. Процент верных ответов моделей при similarity: 0.45
Вывод
В результате исследования процент верных ответов модели model_with_study_w2v при similarity = 0.65 не опускался ниже 90 %, а лучший результат достиг 98 % на тестовой выборке, что на 4 % превосходит лучший результат базового подхода, однако в среднем, model_with_study_w2v опережает базовый всего на 2.5 % model_with_w2v в этом исследовании показала самый худший результат. Следует также отметить, что расширенная модель лучше справляется при небольшом количестве обучающих данных.
Можно сделать вывод, что применение модели Word2Vec для сравнения семантической схожести может дать лучший результат при правильно подобранном параметре similarity. При слишком низком значении, активируются ложные триггеры, что приводит к неверным ответам модели. В тоже время слишком высокое значение может быть неэффективным с точки зрения затраченных ресурсов, так как, результат модели будет идентичен традиционному методу. Также, ключевую роль играет то, на каких данных была обучена модель Word2Vec. При правильно подобранном корпусе данных, состоящем из семантически близких слов, можно улучшить результат распознавания.
Литература:
- Bag of Words Meets Bags of Popcorn. — Текст: электронный // kaggle: [сайт]. — URL: https://www.kaggle.com/competitions/word2vec-nlp-tutorial (дата обращения: 14.03.2024).
- Науменко, А. М. Разработка вопросно-ответной системы с использованием машинного обучения / А. М. Науменко, С. Д. Шелудько, Р. Ю. Юлдашев, Н. О. Хлебников. — Текст: непосредственный // Молодой ученый. — 2017. — № 8 (142). — С. 36–40. — URL: https://moluch.ru/archive/142/40056/ (дата обращения: 14.03.2024).
- Word2Vec. How does it work. — Текст: электронный // Google: [сайт]. — URL: https://code.google.com/archive/p/word2vec/ (дата обращения: 14.03.2024).
- Jamell, A. S. One-Hot Encoding and Two-Hot Encoding: An Introduction / A. S. Jamell. — Текст: электронный // ResearchGate: [сайт]. — URL: https://www.researchgate.net/publication/377159812_One-Hot_Encoding_and_Two-Hot_Encoding_An_Introduction (дата обращения: 14.03.2024).

