На сегодняшний день предиктивная аналитика все больше упрочняет свои позиции в сфере розничного бизнеса. Предиктивная аналитика — инструмент, который помогает составить наиболее достоверную картину предстоящих событий и выработать соответствующий план действий, что может дать преимущество над конкурентами.
Предиктивная аналитика — это способ автоматизированного анализа данных для корректных прогнозирования и планирования событий. Она помогает заранее подстроиться под возможные изменения и избежать рисков.
Системы предиктивной аналитики предназначены для работы с ретроспективой, то есть с оглядкой на опыт. В результате получаются выводы, которые основаны на фактах, а не на голословных предположениях. Чтобы составить максимально объективную картину, используется как можно больше информации.
Предиктивная аналитика предназначена для обработки огромных объемов данных, предполагает использование искусственного интеллекта. База этой системы анализа — машинное обучение, которое позволяет компьютерным системам выполнять задачи самостоятельно — без инструкций, с опорой на готовые шаблоны.
В предиктивной аналитике существует 2 типа машинного обучения:
- Контролируемое . Основные параметры прогнозируемого события и результат, который от них зависит, заранее известны. Тип подразумевает 2 метода:
— Метод регрессии, который подходит для выполнения расчетов. Регрессия — это тип задачи машинного обучения, при котором модель обучается на основе обучающих данных, которые содержат информацию о числовых значениях. Задача модели состоит в том, чтобы предсказать новые числовые значения на основе этой информации. Например, вычисления будущей выручки на основании среднего дохода покупателей и среднего чека.
— Метод классификации, который позволяет предугадать, каким параметрам соответствуют новые объекты, и упорядочить их. Классификация — это тип задачи машинного обучения, при котором модель обучается на основе обучающих данных, которые содержат информацию о категориях или метках. Задача модели состоит в том, чтобы классифицировать новые данные на основе этой информации.
- Неконтролируемое . Позволяет обрабатывать неструктурированные данные. Основной алгоритм — кластеризация, то есть установление причинно-следственных связей [1]. Кластеризация — это тип задачи машинного обучения, при котором модель обучается на основе обучающих данных, которые не содержат информацию о метках или категориях. Задача модели состоит в том, чтобы разделить данные на группы или кластеры на основе их сходства.
С помощью инструментов предиктивной аналитики можно построить покупательский портрет клиента. Портрет клиента — это ряд характеристик, которые позволяют лучше понять целевую аудиторию, чтобы подбирать для нее персонализированный контент. Портрет клиента отличается от описания целевой аудитории более детальной характеристикой пользователя, представляющего конкретный сегмент аудитории. Клиентская база делится на сегменты, в которые входят портреты клиентов этих сегментов.
Для получения сегментов из несортированной базы клиентов необходимо найти подходящий алгоритм машинного обучения, который можно будет применить к данным.
- Байесовский классификатор
Этот алгоритм определяет класс, к которому принадлежит объект. В основе механизмов классификации — расчет вероятности, с которой объект относится к тому или иному типу данных. Применяется в задачах классификации. Из плюсов стоит выделить простоту реализации, из минусов — этот алгоритм с трудом справляется с классификацией сложных объектов.
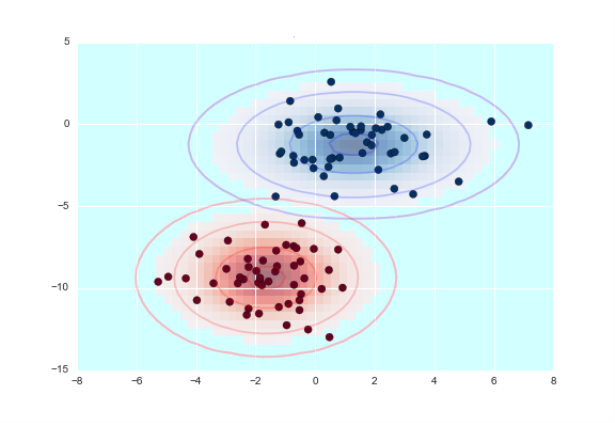
Рис. 1. Пример работы байесовского алгоритма
Учитывая множество характеристик у покупателя, таких как пол, возраст, средний покупательский чек, время и дата покупки, локация магазина и другие, можем сделать вывод что данный алгоритм не подходит для решения данной задачи.
- Метод опорных векторов
Этот алгоритм строит такую линию, которая самым точным образом разделяет между собой разные типы объектов. Из плюсов стоит выделить простоту реализации и работу с многомерными данными, однако имеет минус — может легко спутать похожие объекты разных классов.
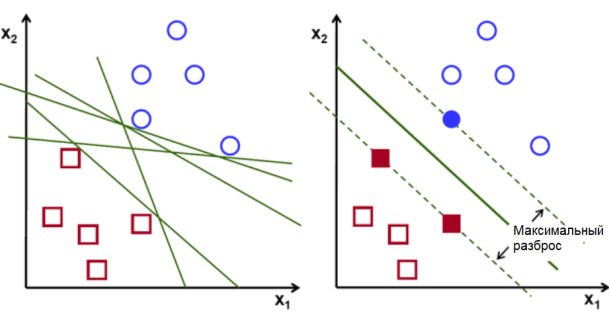
Рис. 2. Пример работы метода опорных векторов
Данный метод также не подходит для решения данной задачи.
- Метод к-средних
Этот алгоритм машинного обучения может сгруппировать объекты по степени похожести, отсортировать множество объектов на несколько классов с примерно похожими свойствами. Применяется при поиске закономерностей, классификации объектов по нескольким параметрам, а также при работе с объектами, которые можно описать набором переменных. Из плюсов стоит выделить высокую скорость работы, простоту и надежность, из минусов — плохо отличает слишком похожие объекты.
![Пример работы метода к-средних [2]](https://articles-static-cdn.moluch.org/articles/j/111816/images/111816.003.png)
Рис. 3. Пример работы метода к-средних [2]
Для решения поставленной задачи по кластеризации базы клиентов больше всего подходит метод к-средних, так как он предназначен для работы с наборами переменных, однако он будет нуждаться в тщательной калибровке, чтобы исключить случаи неправильной классификации похожих элементов.
Литература:
- Предиктивная аналитика: что это такое и как она помогает бизнесу [Электронный ресурс] — Режим доступа: https://www.mango-office.ru/products/calltracking/for-marketing/analitika/prediktivnaya/, (дата обращения — 29.02.24).
- 10 самых популярных алгоритмов машинного обучения [Электронный ресурс] — Режим доступа: https://cloud.vk.com/blog/samye-populyarnye-algoritmy-mashinnogo-obucheniya, (дата обращения — 29.02.24).

