Данная статья повествует о семантической метрике извлечения перечня понятий из текстов на соответствующую тематику. Онтологический анализ представляет основу для данной метрики. Для обнаружения семантической метрики применяется два показателя — показатель вложенных взаимодействий и тезаурусный подход.
Ключевые слова: тезаурус, семантическая метрика, онтология, информационная единица, предметная область.
Статистические и лингвистические подходы представляют некий фундамент в отношении процессов обнаружения лексикографических и терминоведческих понятий. Статистические подходы базируются на расчётах терминологической концентрации на основе цифровых взаимосвязей, характерных для понятия/непонятия. Дифференциация в соответствии с лексико-грамматическими стандартами и терминологическими аспектами является основанием для формирования лингвистического подхода. [3]
В ходе обнаружения терминологических единиц в тексте ключевой минус применения статистических и лингвистических подходов заключается в невозможности выявления наиболее узконаправленных понятий, относящихся к исследуемой отрасли.
Основная доля информационных компонентов предполагает наличие соотношения, отражающего ситуационное взаимодействие данных компонентов. Другими словами, оно показывает ассоциативную интеграцию. Для описанного соотношения рационально подобрать термин «релевантность информационных компонентов». [5]
Если предусмотрено исследование весомых объёмов документации, следует брать в расчёт её тематику для получения наиболее достоверного перечня понятий, относящихся к той или иной сфере. В целях реализации аналогичных операций применяются семантические механизмы, основанные на соответствующих метриках.
На сегодняшний день онтологический подход является наиболее рациональным с точки зрения обнаружения информационных компонентов в рамках одной отрасли, а также выявления профессиональных данных касаемо семантической трактовки. По данной причине формирование и применение семантических метрик на базе онтологической модели является наиболее продуктивным способом решения проблемы, связанной с обнаружением понятийного аппарата в большом документационном объёме. [4]
Формальная система онтологии конкретной отрасли.
Концепция онтологического подхода заключается в том, что исследуемая отрасль развёртывается в качестве перечня терминов, их особенностей и функций.
Язык OWL является наиболее оптимальной демонстрацией онтологии с позиции машинной корректировки, наглядности трактования конкретной отрасли.
Далее целесообразно отметить ключевые обязательства к онтологии OWL, применяемой в качестве инструменты выявления понятий:
Основная онтологическая функция заключается в полноценном отображении объектных признаков в той или иной отрасли.
Не допускается онтологического избытка.
Обязательна внешняя демонстрация онтологии.
Онтологический метод информационного хранения предусматривает её демонстрацию в следующем формате:
O = <Т, R, F>(1)
Учитывая данную модель, следует выделить онтологические компоненты:
Т — понятия прикладной сферы, описанной посредством онтологии.
R — взаимодействия между понятиями объектной отрасли, при условии, что R:
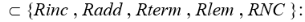
Rinc — совокупность встроенных взаимодействий, к примеру, «sameAs» и «SubClassOf».
Radd — совокупность взаимодействий, которые дают возможность расширить объектное множество посредством взаимодействия лемм взаимодействующих компонентов.
Rterm — взаимодействие представляет собой понятие, представляющее логический вид трактовки. Данный признак носит дополняющий характер, обнаруживается специалистом на основе показателя того, как объект взаимодействует с рассматриваемой отраслью.
Rlem — взаимодействие предполагает лемму, обладающую строковыми особенностями, извлекаемыми из леммирования объектного имени посредством ПО «Mystem» компании Яндекс согласно соответствующим морфологическим особенностям понятия.
Rnc — совокупность объектных взаимодействий, в том числе и особенностей информационных единиц, дающих полноценную трактовку объектному взаимодействию исследуемой отрасли.
F — совокупность интерпретирующих функций, закреплённых за понятиями или онтологическими взаимодействиями. [2]
Применение семантической метрики понятие/непонятие в рамках совокупности слов одного текстового отрывка с применением онтологии OWL предусматривает трактовку для каждого направленного слова или словосочетания уровня интеграции к понятиям исследуемой сферы.
Интеграционный уровень входных слов и словосочетаний к понятиям рассматриваемой отрасли демонстрирует показатели от нуля до единицы. Если полученный показатель находится в пределах единицы, вполне вероятно, что он обладает статусом понятия. [3]
В данном случае следует отметить два семантических показателя:
- Тезаурусный показатель.
- Показатель вложенных взаимодействий.
Тезаурусом является контролируемый понятийный аппарат, сформированный на естественном языке, отражающий взаимодействие между понятиями и выполняющий функцию информационного поиска. Каждая онтологическая единица представляет собой наиболее сложный тип тезауруса. [4]
Тезаурусный метод обнаружения понятийного аппарата предусматривает прямой поиск леммных входов и их словосочетаний, трактуемых онтологическим путём. В данном разрезе каждый онтологический класс предполагает признак наличия Леммы, выраженной в строковом формате, сформированного посредством леммирования объектного наименования не без поддержки ПО «Mystem» от компании Яндекс.
Механизм определения уровня интеграции слов и словосочетаний с понятиями исследуемой отрасли в соответствии с таурусным методом включает:
Оценку интеграционного уровня входящего словесного механизма каждому онтологическому компоненту без расчёта онтологического оценочного показателя.
Формирование опорного онтологического компонента, сопряжённого с понятием проблемной отрасли.
Онтологическое устройство предусматривает у каждого компонента признак наличия термина, обладающего логическим типом трактовки. Данный признак носит дополняющий характер и выявляются специалистов на основе сопряжённости понятия с исследуемой отраслью. Несмотря на оценку интеграционного уровня, сформированная метрика даёт возможность обнаружить понятия из текстового отрывка с помощью их сравнения с уже выявленными онтологическими компонентами и леммными взаимодействиями посредством соотношения Radd, рассчитанных онтологическим путём.
Получается, что в процессе соотнесения входных словесных единиц и объектов исследуемой сферы, интегрированных посредством соотношения Radd, понятием следует называть сочетание слов, лемма которых имеет полноценное соотношение с совокупностью лемм аналогичных онтологических компонентов.
Для применения обнаруженного понятия целесообразно использовать соотношение Radd, объектное взаимодействие которого позволяет складывать сочетания слов в натуральном формате.
Для оценки полученных результатов, происходит группировка данных по следующим критериям:
– Истинно-положительные (true positives, tp) — ожидаемые результаты.
– Ложно-положительные (false positives, fp) — ошибочные результаты в выдаче.
– Ложно-отрицательные (false negatives, fn) — ожидаемые результаты, но не попавшие в выдачу.
– Истинно-отрицательные (true negatives, tn) — результаты, которые не попали и не должны были попасть в выдачу.
Следовательно, точность (P, precision), которая указывает на то, сколько точных результатов получено в выдаче, определяется по формуле:
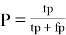
Однако, этого недостаточно для оценки того, все ли ожидаемые результаты попали в выдачу, поэтому используется еще одна формуала для оценки полноты выдачи (R, recall):
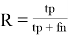
Кроме того, для более корректного анализа данных, получаемых по семантической метрике, рекомендуется использовать унифицированную метрику F 1, для расчета которой используется формула:
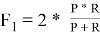
Данная метрика позволяет оценить пороговое качество семантической метрики.
С позиции рассматриваемых показателей осуществляются процессы:
Специалист в исследуемой сфере формирует соответствующую онтологию OWL.
Формируется онтологически-направленный механизм обнаружения понятийного аппарата, предполагающего указанные раннее метрики для реализации задачи выявления степени понятийности слова или словосочетания внутри большого документационного объёма.
Онтология OWL предусматривает системное построение в формате иерархии и составляет категории взаимодействия между классовыми объектами. Включает несколько иерархических ступеней для максимальной трактовки понятий исследуемой сферы, применяемой для решений установленной проблемы.
Принцип механизма обнаружения понятий заключается в выполнении следующих операций:
Вычисление статистических и лингвистических признаков полученного текстового отрывка, предусматривающего морфологическую разметку. Расчёт ведётся с помощью системного модуля.
Вычисление семантических словесных признаков, а также особенностей сочетаний слов в тексте, подверженном обработке. Расчёт основан на указанных раннее подходах и онтологии формата OWL.
Учитывая вышеизложенное, можно сделать вывод, что семантическая метрика понятия/непонятия, разработанная на базе онтологии проблемной отрасли позволяет обнаружить только те слова и словосочетания, которые являются официальными понятиями рассматриваемой сферы. Для каждого входного словесного компонента устанавливается числовой показатель, обозначающий уровень их интеграции.
Рассматриваемая метрика может применяться как автономная или как дополнение к лингвистической/статистической метрике, применяемых для обнаружения понятийного аппарата в аналитических целях.
Литература:
1. Андреев И. А., Башаев В. А., Клейн В. В. Разработка программного средства для извлечения терминологии из текста на основании морфологических признаков, определяемых программой Mystem // Интегрированные модели и мягкие вычисления в искусственном интеллекте. — М.: Физматлит, 2013. — С. 1227–1236.
2. Добров Б. В., Лукашевич Н. В., Сыромятников С. В. Формирование базы терминологических словосочетаний по текстам предметной области // Тр. 5-й Всеросс. науч. конф. «Электронные библиотеки: перспективные методы и технологии, электронные коллекции» (RCDL-2003). — СПб., 2003. — С. 201–210.
3. Усталов Д. А. Семантические сети и обработка естественного языка // Открытые системы. СУБД. 2017. № 2. C. 51–53.
4. Hryhorovych V., «Construction of Normalized Metric for Hierarchical Data Structures based on Harmonic Functions», 2021 IEEE 16th International Conference on Computer Sciences and Information Technologies (CSIT) , 2021, pp. 146–149 .
5. Lourdusamy R. and John A., «A review on metrics for ontology evaluation», 2018 2nd International Conference on Inventive Systems and Control (ICISC) , 2018, pp. 1415–1421.

