Қазіргі таңда сөйлеуді тану моделін қолдану маңызды көрсеткіштердің бірі болып табылады. Сөйлеуді тану өнімдері нарықта бүгінгі күннің өзінде қол жетімді болғанына қарамастан, қазіргі уақытта олардың дамуы өте нақты болжамдармен жұмыс істейтін статистикалық әдістерге негізделген. Бұл жұмыста терең нейрондық желілер (DNN) негізінде жұмыс істейтін сөйлеуді танудың интегралды (end-to-end) жүйелері қарастырылады. Зерттеу жұмысы барысында әртүрлі нейрондық желілер, мысалы, коннекционистердің уақытша классификациясының моделі (CTC) және назар аудару механизміне негізделген шифр-декодтау модельдері (attention-based models) қолданылды. Зерттеу нәтижесінде уақытша классификациялық модель (CTC) тікелей агглютинативті тілдер үшін тілдік модельдерсіз жұмыс істейтіні дәлелденді, бірақ ең жақсы көрсеткішті- ResNet жасанды нейрондық желі (CER) таңбалар қатесінің жиілігін қолдана отырып 11,52 % және (WER) сөздер қатесінің жиілігі 19,57 % болатын тілдік модельдімен көрсеткіштерді көрсетті. Назар аудару механизміне (attention-based models) негізделген модельдік шифратор-дешифратордың көмегімен BLSTM нейрондық желісімен жүргізілген эксперимент 8,01 % тең CER және 17,91 % тең WER нәтижесін көрсетті. Эксперимент арқылы тілдік модельдерді интеграцияламай жақсы нәтижелерге қол жеткізуге болатындығы дәлелденді. Ең жақсы нәтижені ResNet моделі көрсетті.
Кілтті сөздер: сөйлеуді тану, агглютинативті тілдер, модельдер арқылы,терең оқыту, CTC.
На сегодняшний день использование модели распознавания речи является крайне важным. Хотя, продукты для распознавания речи уже доступны на рынке, в настоящее время их развитие в большой степени основано на статистических методах, которые работают при очень ясных предположениях. В данной работе рассматриваются интегральные (еnd-to-end) системы распознавания речи, работающие на основе глубоких нейронных сетей (DNN). В исследованиях применялись разного вида нейронные сети, такие как, модель временной классификаций коннекционистов (CTC) и модели шифратор-дешифратор, основанные на механизме внимания (attention-based models). В результате проведенного исследования было доказано, что модель CTC работает без языковых моделей непосредственно для агглютинативных языков, но наилучшим является остаточная нейронная сеть (ResNet) с результатом CER, равным 11,52 % и WER, равным 19,57 %, с использованием языковой модели. Осуществленный эксперимент с нейронной сетью ВLSTM с помощью шифратора-дешифратора модели, основанные на механизме внимания (attention-based models), показал результат CER, равный 8,01 % и WER, равный 17,91 %. С помощью проведенного эксперимента было доказано, что без интегрирования языковых моделей можно достичь хороших результатов. Лучший результат показал модель ResNet.
Ключевые слова : распознавание речи, агглютинативные языки, сквозные модели, глубокое обучение,СТС.
Сөйлеу дегеніміз-ақпаратты ұсыну, өңдеу, сақтау және беру үшін адам қолданатын дыбыстық сигналдар, жазбаша белгілер мен таңбалар жүйесі. Бұл сонымен қатар адам мен машинаның өзара әрекеттесу құралы [1]. Дауыстық интерфейсті жүзеге асыру үшін көптеген мамандардың қатысуы қажет, атап айтқанда компьютерлік лингвист, DNN бағдарламашысы және т. б. сөйлеуді танудың дәстүрлі жүйесін акустикалық модельдер, тілдік модельдер және декодтау сияқты бірнеше модульдерге бөлуге болады [2]. Модульдік дизайн көптеген тәуелсіз болжамдарға негізделген, тіпті дәстүрлі акустикалық модель Марков моделіне тәуелді кадрлар бойынша оқытылады. Сөйлеуді танудың автоматтандырылған жүйелерінде танымал модельдер сөйлеу сигналдарының уақытша динамикасын және гаусс ықтималдық тығыздығының таралуын (GMM) білдіретін жасырын Марков модельдері (HMM) болды, олар әдетте айтылу бірлігіне сәйкес келетін стационарлық қысқа уақыт аралығында сигналдардың таралуын ұсынды. Бүгінгі таңда нейрондық желі сөйлеуді тану саласында кеңінен қолданылады. Сөйлеуді автоматты түрде танудың ең танымал тәсілі — HMM-DNN гибридті архитектурасы, онда HMM құрылымы сақталады және GMM сөйлеу сигналдарының динамикалық сипаттамаларын модельдеу үшін терең нейрондық желімен (DNN) ауыстырылады. Мысалы, зерттеулерде [3] тілдік модельдер RNN-мен оқытылды, жұмыста [4] сөздік LSTM желілері арқылы алынды, [5] терең нейрондық желілер акустикалық модельдерді құру үшін жоғары нәтижелер көрсетті, [6] Больцман шектеулі машиналарын қолдана отырып белгілерді оқшаулау әдісі енгізілді. Демек, сөйлеуді танудың барлық кезеңдерінде жасанды нейрондық желілерді қолдану идеясы пайда болды.
Сөйлеуді танудағы жоғары өнімді GPU көмегімен терең оқыту әдістері сәтті жүзеге асырылды және бұл тәсіл интегралды әдіс деп аталды. Интегралды тәсілде нейрондық желіні оқытуда тек бір модель басқа компоненттерді пайдаланбай қажетті нәтиже бере алады және мұндай модель интегралды деп аталады (end-to-end).
Интеграцияланған желілерді акустикалық және тілдік модель ретінде әрекет ететін және кірістегі сөйлеу деректерін транскрипциямен тікелей салыстыратын бірнеше ультра дәл (CNN) және қайталанатын (RNN) қабаттарды қосу арқылы жасауға болады. Қазіргі уақытта интегралды модельдерді жүзеге асырудың бірнеше әдістері бар, атап айтқанда коннекциялық уақыт классификациясы (CTC) және назар аудару механизміне негізделген модель шифраторы (attention-based model), шартты кездейсоқ өрістер (CRF). Көптеген жарияланған еңбектерде интегралдық тәсіл нәтижелерінің сәттілігі нейрондық желіні оқыту үшін мәліметтер көлемінің ұлғаюына байланысты екендігі дәлелденді. Әлемде интегралдық тәсіл негізінде жұмыс істейтін қосымшалар бар: Google Listen, Baidu Deep Speech, Spell, Attend, voice to Text Messenger, Speech to Translator TTS. Бұл тұжырымның басты себебі-қазіргі интегралды модельдер мәліметтер негізінде оқытылады. Агглютинативті тілдер үшін оқыту деректерінің үлкен корпустары жоқ. Басқа тілдерде WSJ, TIMIT, LibriSpeech, AMI және Switchboard бар, оларда мыңдаған сағаттық оқу деректері бар.
CTC модельдерінде интегралдық тәсілді жақсарту үшін және назар аудару механизміне негізделген Шифр-декодтау (attention-based model) желінің әртүрлі нұсқалары енгізілді. Сөйлеу сигналдарында жергілікті корреляцияны қолдану үшін конволюциялық нейрондық желілерден (CNN) тұратын күрделі кодерлер енгізілді. Бұл модельдер әр ішкі модельдің артықшылықтарын пайдаланады және бүкіл модельге нақты және қатаң шектеулер енгізеді. Осы бағыттағы жоғарыда келтірілген зерттеулер сөйлеуді танудың интегралды жүйелерінің жұмысын едәуір жақсартады. Модельге күрделі есептеу қабаттарын енгізу уақыт пен жиілік аймағында жақсы корреляцияларды қолдана алады, бірақ көптеген параметрлері бар модельді оқыту қиынырақ. Алдыңғы зерттеулерде әртүрлі тілдердегі терең оқыту модельдері сәтті екендігі анықталды, ал көп мақсатты оқыту (MTL) интегралды оқыту үшін қолайлы [7, 8].
Сөйлеуді танудың интегралды тәсілінде сигналдың барлық параметрлері нейрондық желілердің құрылымына оңай әсер ететін градиенттерді есептеу арқылы анықталады. Алайда, агглютинативті тілдерді танудың интегралды жүйелері әлі де қазіргі зерттеу деңгейіне жетпеген және оқытылмаған.
Бұл жұмыста біз интегралды сәулет аясында шектеулі сөйлеу ресурсы бар мәселені шешуге бағытталған агглютинативті тілдерді тану ұсынылады.
Материалдар мен әдістер
Сөйлеуді тану үшін коннекциялық уақытты жіктеуге (CTC) негізделген модельдер кіріс және шығыс тізбегін бастапқы туралаусыз жұмыс істейді. CTC тілді декодтау үшін жасалған.
Жұмыста [9] CTC-мен бірге терең қайталанатын конвульсиялық желілерді және терең қалдық желілерді пайдалану ұсынылды. Ең жақсы нәтиже batch қалыпқа келтіруімен қалдық желілерді қолдану арқылы алынды. Осылайша, TIMIT сөйлеу корпусында 17,33 % тең PER нәтижесі алынды.
Сөйлеуді интегралдық тану үшін CTC баламасы — (attention) негізінде sequence to sequence (Sec2Sec) модельдері қолданылады [10]. Мұндай модельдер кодтаушыдан және декодердан тұрады. Кодтаушы дыбыстық кадр ақпаратын қабаттан қабатқа дейін азайту арқылы ықшам векторлық көрініске қысады, ал декодтау осы сығылған көрініс пен қайталанатын нейрондық желі негізінде таңбалар, фонемалар немесе тіпті сөздер тізбегін қалпына келтіреді.
Қарастырылған жұмыста [11] — қайталанатын желілердің орнына терең конвульсиялық желілерді қолданатын CTC моделі ұсынылды. Конвульсиялық желілерге негізделген ең жақсы модельде 10 конвульсиялық қабат және 3 толық байланысқан қабат болды. Ең жақсы PER 18,2 % болды, ал екі бағытты LSTM желілері үшін ең жақсы PER 18,3 % болды. Сондай-ақ, конволюциялық желілер оқу жылдамдығын арттыруға мүмкіндік береді және фонема тізбегінде оқуға қолайлы болады деген қорытынды жасалды.
CTC желісінде нейрондық желінің шығыс мәндері ауысу ықтималдығын білдіреді. Нейрондық желі архитектурасы ретінде екі бағытты LSTM желілері таңдалды. Үш модель салыстырылды: RNN-CTC моделі, RNN-CTC моделі (RNNWER), минималды WER-мен қайта оқытылған және Kaldi құралдарымен жазылған негізгі гибридті модель [12].
Soltau және т. б. [13] YouTube бейнесіне қол қою тапсырмасында CTC негізіндегі модельді оқыту арқылы контекстке байланысты фонеманы тануды аяқтады. Sequence-to-sequence модельдері негізгі жүйелермен салыстырғанда 13–35 % — ға танылмайды.
Graves және оның әріптестері [14] кадр деңгейіндегі туралауды қолданбай, интегралды модель CTC критерийі бойынша қарастырды. Sequence-to-sequence моделі акустикалық модель, айтылым моделі және тілдік модель үшін нейрондық желіні оқыту және оңтайландыру арқылы сөйлеуді автоматты түрде тану мәселесін жеңілдетті. Бұл модельдер сонымен қатар көп диалектикалық жүйелер ретінде жұмыс істейді, өйткені олар әртүрлі диалектілерде бірге модельденеді.
CTC модельдерінің «жалпылауы» бар — RNN түрлендіргіші (RNN Transducer), ол екі RNN-ді сериялық түрлендіру жүйесіне біріктіреді [15]. Желілердің бірі CTC желісіне ұқсас және кіріс тізбегімен бірдей уақытты өңдейді, ал екінші RNN алдыңғы белгілерге сәйкес келесі белгілердің ықтималдығын модельдейді. CTC желілеріндегідей, есептеу үшін динамикалық бағдарламалау және тікелей-кері алгоритмі қолданылады, бірақ RNN екеуінің де шектеулерін ескере отырып. CTC желілерінен айырмашылығы, RNN түрлендіргіші кіріс тізбегінен ұзағырақ шығыс тізбегін құруға мүмкіндік береді. RNN түрлендіргіштері TIMIT корпусында 17,7 % тең PER-мен фонемаларды тануда жақсы нәтижелер көрсетті.
Біздің жұмысымыздың әдістемесі келесідей орындалды:
CTC нейрондық желіні оқыту үшін CTC функциясы жоғалту функциясы ретінде қолданылды. Нейрондық желінің шығу тізбегін келесідей сипаттауға болады:
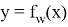
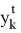
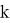
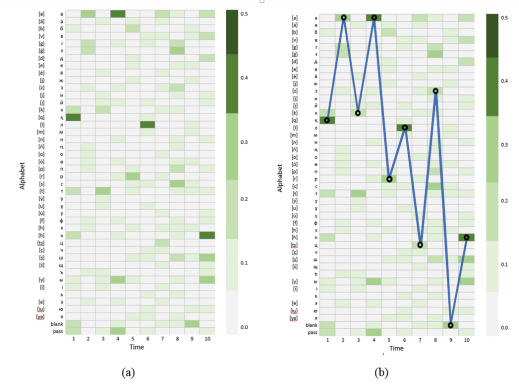
Сур. 1. Акустикалық модель болжаған матрица
X сәйкес blanks индекстері мен
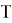
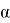
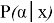
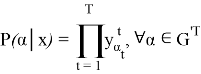
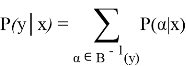
Жоғарыда келтірілген формула динамикалық бағдарламалау арқылы есептеледі, ал нейрондық желі STS функциясын азайтуға үйретіледі:
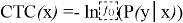
Декодтау келесі болжамға негізделген:
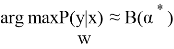
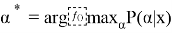
Attention-бұл сөйлеуді тану кезінде RNN жұмысын жақсартуға арналған Encoder-Decoder механизмі. Шифратор (Encoder) — нейрондық желі, мысалы: DNN, BLSTM, CNN;
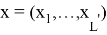
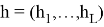
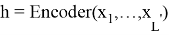
Декодер (Decoder) — бұл әдеттегі RNN, ол шығыс тізбегін құру үшін аралық көріністі қолданады:
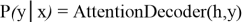
Декодер ретінде біз назар аудару механизміне негізделген қайталанатын тізбекті генераторды қолданылды (attention-based Recurrent sequence Generator).
Деректерді талдау үшін «зияткерлік жүйелердің компьютерлік инженериясы» зертханасы ұсынылды. Ол үшін компанияның шу оқшаулау, кәсіби дыбыс жазу студиясы Vocalbooth.com қолданылды.
Дикторлар ретінде сөйлеуде ешқандай кемшіліктері жоқ тұлғалар таңдалды. Жазу үшін әр жыныстағы және түрлі жастағы (18 жастан 50 жасқа дейін) 380 диктордың сөздері қолданылды. Бір диктордың дауысы мен жазбасы орташа есеппен 40–50 минутты алды. Әр диктор үшін жеке файлдарға жазылған 100 сөйлемнен тұратын мәтін дайындалды. Әр сөйлем орта есеппен 6–8 сөзден тұрады. Сөйлемдер сөздердің ең бай фонемасымен таңдалды. Мәтіндік деректер қазақ тіліндегі жаңалықтар сайттарынан жиналды, сондай-ақ электрондық түрдегі басқа да материалдар пайдаланылды. Барлығы 123 сағат аудио деректер жазылды. Жазу кезінде мәтіндік файлдағы әр аудио файлдың сипаттамасы бар транскрипциялар жасалды. Құрылған корпус, біріншіден, үлкен көлемдегі мәліметтер базасымен жұмыс істеуге, жүйенің ұсынылған сипаттамаларын тексеруге, екіншіден, дерекқордың кеңеюінің тану жылдамдығының әсерін зерттеуге мүмкіндік береді.
Барлық аудио материалдар бірдей сипаттамаларға ие:
– кеңейту файлы wav;
– сандық түрге түрлендіру әдісі: РСМ;
– дискретті жиілік: 44,1 кГц;
– сыйымдылығы: 16 бит;
– аудио арналардың саны: бір (моно).
Агглютинативті тілдерді танудың интегралды жүйесін оқыту үшін біз қосымша 2 корпусты таңдадық:
– Түрік корпусы (50 миллион сөз және аудио): http://www.tnc.org.tr/
– Татар тілі корпусы (75 миллион сөз және аудио): http://www.corpus.antat.ru.
Нәтижелер және талқылау
Аталмыш белгілерді алу үшін эксперименттерде біз алғашқы 13 есептелген коэффициенттері бар мел-жиілікті кепстралды коэффициенттері (MFCC) қолданылды. Барлық оқыту деректері оқыту (90 %) және кросс-тексеру (cross-validation 10 %) болып бөлінді.
Эксперименттің екінші кезеңінде CTC жоғалту функциясы негізінде модельдің нәтижелері сипатталды. Тиісті CTC модельдерінің нәтижелері 1-кестеде келтірілген. Зерттеулерде нейрондық желілердің бірнеше түрі қолданылды: ResNet, MLP, LSTM, Bidirectional LSTM. Нейрондық желілерді тілдік модельсіз алдын-ала орнату жақсы нәтижелерді берді:
MLP моделі: ReLU активтендіру функциясын қолдана отырып, бастапқы оқу жылдамдығы 0,007-ге тең және 1,5-ке тең болатын 6 жасырын қабат болды.
LSTM мәні: әрқайсысында 1024 бірлік бар 6 қабат болды, 0,5 с-қа тең, бастапқы оқу жылдамдығы 0,001-ге тең және 1,5-ке тең.
ConvLSTM: 8 сүзгісі бар бір екі өлшемді конвульсиялық қабат, ReLU активтендіру функциясы. Содан кейін ол 0,5-ке тең ұстау ықтималдығымен түседі.
LSTM: 1024 бірлігі бар 6 қабатты қолданды және 0,5-ке тең ұстау ықтималдығымен құлады.
Resnet қалыпқа келтірумен 9 қалдық блок болды (batch-normalization).
Кесте 1
CTC модельдерінің нәтижелері
|
Модель |
CER % |
WER % |
Decode |
Train |
|
Тілдік модельдерді қолданбайтын модельдер. | ||||
|
MLP |
48.11 |
59.26 |
0.2032 |
131.2 |
|
LSTM |
36.43 |
46.51 |
0.2152 |
421.3 |
|
Conv+LSTM |
34.92 |
39.31 |
0.2688 |
465.2 |
|
BLSTM |
33.61 |
37.66 |
0.2722 |
491.7 |
|
ResNet |
32.52 |
36.57 |
0.2657 |
192.6 |
|
Тілдік модельдер мен MFCC қолданатын модельдер. | ||||
|
MLP |
39.11 |
63.26 |
0.0192 |
146.2 |
|
LSTM |
24.43 |
46.51 |
0.0152 |
521.3 |
|
Conv+LSTM |
22.92 |
39.31 |
0.0088 |
465.2 |
|
BLSTM |
13.61 |
20.66 |
0.0022 |
591.7 |
|
ResNet |
11.52 |
19.57 |
0.0051 |
242.6 |
Бірінші экспериментте модельдер үшін назар аудару механизміне негізделген шифр-декодтау (attention-based models), белгілерді алу үшін MFCC алгоритмін қолданылды, нейрондық желіні оқыту үшін CTC функциясын қолданылды. Екінші экспериментте MFCC және тілдік модельдерді қолданылды. Эксперимент нәтижелерін 2, 3-суретте көруге болады.
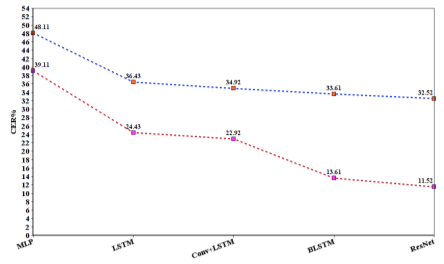
Сур. 2. CER бойынша СТС моделінің нәтижелері
Көк сызық-тілдік модельдерді қолданбайтын модельдің нәтижесі, сондай-ақ қызыл сызық тілдік модельдер мен MFCC-ті қолданатын модель.
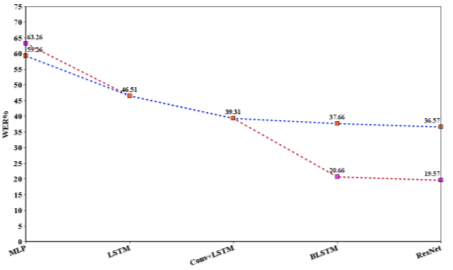
Сур. 3. WER бойынша СТС моделінің нәтижелері
Көк сызық-тілдік модельдерді қолданбайтын модельдің нәтижесі, сондай-ақ қызыл сызық тілдік модельдер мен MFCC-ті қолданатын модель.
Келесі экспериментте LSTM және BLSTM нейрондық желілері қолданылды. Бұл модельде 256 бірліктен тұратын 6 қабат қолданылды, кодерде сақтау ықтималдығы 0,7 болған кезде бастапқы тастау азаяды. Декодер ретінде LSTM және назар аудару механизміне негізделген модельдік Шифр-декодерді қолданылды (attention-based models). Нәтижелерді 2-кестеде көруге болады.
Кесте 2
Нәтижелер шифратор - назар аудару механизміне негізделген модель декодері (attention-based models)
|
Модель |
CER % |
WER % |
Decode |
Train |
|
LSTM |
8,61 |
17,58 |
0,468 |
476,7 |
|
BLSTM |
8,01 |
17,91 |
0,496 |
544,3 |
Қорытынды
Жүргізілген тәжірибелер CTC моделінің тікелей агглютинативті тілдер үшін тілдік модельдерсіз жұмыс істейтіні дәлелденді, бірақ ең жақсы нәтиже-CER нәтижесі 11,52 % және WER 19,57 %, тілдік модельді қолдана отырып алынды. Осылайша, тілдік модель сөйлеуді танудың маңызды бөлігі екенін көруге болады.
CTC моделі танылған таңбалардан сөздер мен сөйлемдерді құруда қателіктер жібереді, бірақ алынған фонемалық транскрипция түпнұсқаға өте ұқсас. Бірақ тәжірибеден кейін тілдік модельдерді біріктірместен агглютинативті тілдерге назар аудару механизміне негізделген (attention-based models) модельді шифраторды қолдану жақсы нәтижелерге қол жеткізуге мүмкіндік беретіні анықталды. LST-тегі нейрондық желі назар аудару механизміне негізделген модель шифраторы (attention-based models) CER нәтижесін 8,01 % және WER 17,91 % көрсетті.
Әдебиет:
- Perera F.P, Tang D, Rauh V, Lester K, Tsai W.Y, Tu Y.H, et al. Relationship between polycyclic aromatic hydrocarbon–DNA adducts and proximity to the World Trade Center and effects on fetal growth. Environ Health Perspect. — 2005. — Р1062–1067.
- O.Mamyrbayev, M.Turdalyuly, N.Mekebayev, K.Alimhan, A.Kydyrbekova, T.Turdalykyzy. Automatic Recognition of Kazakh Speech Using Deep Neural Networks. ACIIDS 2019. — Р. 465–474.
- Mikolov T. et al. Recurrent neural network based language model. Interspeech. — 2010. — Vol. 2. — P. 1045–1048.
- Rao K., Peng F., Sak H., Beaufays F. Grapheme-to-phoneme conversion using long short-term memory recurrent neural networks. IEEE International Conference on Acoustics, Speech and Signal Processing. — 2015. — Р. 4225–4229.
- Jaitly N., Hinton G. Learning a better representation of speech soundwaves using restricted boltzmann machines. IEEE International Conference on Acoustics, Speech and Signal Processing. –2011. –Р. 5884–5887.
- Smolensky P. Information processing in dynamical systems: Foundations of harmony theory. Colorado University at Boulder Dept of Computer Science. — 1986. — P. 194–281.
- Kim, S., Hori, T., & Watanabe, S. Joint CTC-attention based end-to-end speech recognition using multi-task learning. In IEEE International Conference on Acoustics, Speech and Signal Processing. –2017.
- K.Aida-Zade, S.Rustamov, E.Mustafayev, Principles of Construction of Speech Recognition System by the Example of Azerbaijan Language. Int. Symposium on Innovations in Intelligent Systems and Applications, 2009. — P. 378–382.
- Zhang Z. et al. Deep Recurrent Convolutional Neural Network: Improving Performance For Speech Recognition. — 2016.
- D. Bahdanau et al. End-to-end attention-based large vocabulary speech recognition. Acoustics, Speech and Signal Processing. IEEE International Conference. — 2016. — P. 4945–4949.
- Zhang Y. et al. Towards end-to-end speech recognition with deep convolutional neural networks. –2017.
- Povey D. et al. The Kaldi speech recognition toolkit. IEEE 2011 workshop on automatic speech recognition and understanding. IEEE Signal Processing Society. –2011. — P.4.
- H. Soltau, H. Liao, H. Sak, Neural speech recognizer: acoustic-to-word LSTM model for large vocabulary speech recognition, 2016.
- A. Graves, S. Ferna´ndez, F. Gomez, J. Schmidhuber, Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks, in: Proceedings of the 23rd International Conference on Machine Learning, 2006. — P.369–376.
- Boulanger-Lewandowski N., Bengio Y., Vincent P. High-dimensional sequence transduction. 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, 2013. — P. 3178–3182.

