В статье авторы исследуют возможную структуру хранения данных датчиков в нереляционной распределенной базе данных Apache Cassandra.
Ключевые слова: данные, Cassandra, Apache Cassandra, noSql, датчик, телеметрия, база данных, модель.
- Концептуальная модель данных.
Концептуальная модель данных разрабатывается с целью понимания данных в конкретной области. Данную модель можно представить в виде диаграммы сущностей-отношений (ERD). Она показывает типы сущностей, типы связей и ограничения ключей в проекте. (Рис. 1)
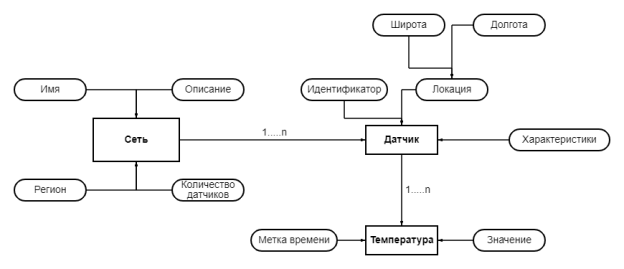
Рис. 1. Диаграмма сущностей-отношений
Концептуальная модель данных для телеметрии включает в себя сети датчиков, датчики и измерения температуры. Каждая сеть имеет уникальное имя, описание, регион и количество датчиков. Датчик описывается уникальным идентификатором, местоположением, которое состоит из широты и долготы, а также нескольких характеристик датчика. Измерение температуры имеет временную метку и значение и однозначно идентифицируется идентификатором датчика и временной меткой измерения. В то время как сеть может иметь много датчиков, каждый датчик может принадлежать только одной сети. Точно так же датчик может записывать множество измерений температуры в разные временные метки, и каждое измерение температуры сообщается только одним датчиком.
- Разработка приложения
Приложение должно быть разработано посредством шаблонов доступа к данным, каждый из которых указывает, какие атрибуты следует искать, группировать, упорядочивать и т. д.
Созданный интерфейс должен иметь систему авторизации, точку входа в приложение и прямую обработку запросов от пользователей. Точкой входа будет являться набор всех сетей телеметрии с привязкой к региону. Далее приложение должно по запросу выводить либо все датчики в какой-либо выбранной сети, либо средние значения температуры для сети, либо значение температуры для конкретной модели датчика.
Еще одним немаловажным пунктом при проектировании приложения является задание уровня согласованности. Уровень согласованности задает количество ответов от узлов-реплик кластера, необходимых для получения ответа на запрос. Всего их существует 9 видов. При чтении и записи значений телеметрии рекомендуется использовать QUORUM уровень. Это означает, что большая часть узлов-реплик (n/2 +1, где n — число узлов-реплик) должна давать ответ.
- Логическая модель данных
Логическая модель данных строится на основе концептуальной модели и требований приложения. Cassandra является не реляционной базой данных, поэтому все значения записываются, читаются и хранятся в отдельных таблицах, не связанных между собой явно. Структуру данных необходимо продумать заранее, потому что в последствии будет невозможно изменить некоторые её элементы. Неграмотное хранение значений может приводить нарушению согласованности, доступности или распределенности системы. Для построения зависимостей данных телеметрии в Cassandra лучше всего пользоваться диаграммой Чеботко. (Рис. 2)
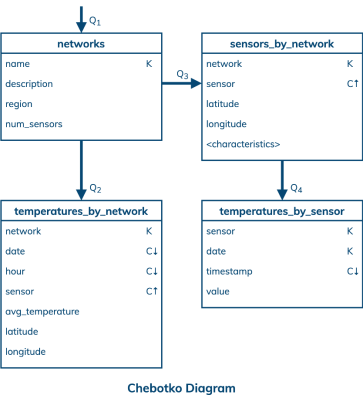
Рис. 2. Диграмма Чеботко
Существует четыре таблицы, а именно networks, temperatures_by_network, sensors_by_network и temperatures_by_sensor, которые предназначены специально для поддержки шаблонов доступа через приложение к данным Q1, Q2, Q3 и Q4 соответственно. Параметры с флагом “K” являются ключом патриции (Partition key), согласно которому данные распределяются в узлах кластера, а параметры с флагом “C” являются ключевыми столбцами кластеризации с нисходящим или восходящим порядком, представленным стрелкой вниз или вверх. Существует одна важная особенность: после формирования таблицы partition key уже нельзя будет изменить, то есть при изначально неудачной конфигурации базы данных существует высокая вероятность получения перегрузки одного или нескольких узлов кластера. И исправить данную проблему после процесса интегрирования системы будет достаточно проблематично.
Следующим важным параметром является стратегия репликации. Она позволяет выбрать количество узлов-реплик, в которых будут дублироваться строки данных. Для любого реального проекта стоит выбирать NetworkTopologyStrategy, поскольку она имеет гибкие настройки распределения значений между дата-центрами и стойками.
- Ресурсоемкость
Apache Cassandra крайне не ресурсоемкая система. Цена за быструю обработку большого количества данных — это высокая загруженность сервера. Поэтому необходимо конфигурировать дата-центр максимально мощными комплектующими. Так выглядят минимальные системные требования к каждому узлу кластера:
— 2 CPU Cores
— 4GB RAM
— 32 GB SSD
— RAID 1
Стоит понимать, что данные системные требования подойдут исключительно для тестового варианта работы с базой данных, при развертывании реального приложения понадобится намного больше дискового пространства и процессор с большим количеством ядер.
- Заключение
Apache Cassandra идеально подходит для получения, хранения и обработки значений телеметрии, однако подходит только для тех проектов, которые располагают достаточными вычислительными мощностями и грамотными специалистами, которые знают как ее правильно настроить.
Литература:
- Джефф, Карпентер Cassandra. Полное руководство / Карпентер Джефф, Хьюитт Эбен. — 2-е изд. — Москва: O’Reilly, 2017. — 400 c. — Текст: непосредственный.
- Data Modeling. — Текст: электронный // cassandra apache: [сайт]. — URL: https://cassandra.apache.org/doc/latest/data_modeling/index.html (дата обращения: 11.04.2021).
- Basic rules of Cassandra data modeling. — Текст: электронный // datastax: [сайт]. — URL: https://www.datastax.com/blog/basic-rules-cassandra-data-modeling (дата обращения: 11.04.2021).
- Nishant, Neeraj Mastering Apache Cassandra / Neeraj Nishant. — 2-ое. — Мумбаи: Packt Publishing, 2013. — 318 c. — Текст: непосредственный.

