1. Introduction
Information technology has become an integral part of people's daily lives. It is difficult to find an industry where there is no influence of information technology. On the contrary, it is easy to find industries that cannot exist without information technology. Organizations and companies produce huge amount of data daily. However, they do not cope with such amount of data because of many factors: lack of resources such as time, human and finance; an inefficient storage of data; not knowing how to consume such data and what to do with them. It is expected that the data will double every two years over the next decade and it will be exceedingly difficult for us to process such data with the current computing power of modern processors. For this reason, we need to find, develop, and implement other methods and techniques, which are capable to resolve issues with ever-growing data.
Today, data is getting a lot of attention. As many organizations and companies understood that they were handling data inappropriate, especially textual data. Thus, leading to the new methods, algorithms, principles of handling textual data. One of the methods to deal with textual data is Natural Language Processing. It has many applications such as sentiment extraction, topic extraction and word generating etc.
Goal of this work is to apply NLP techniques to extract sentiment from textual data. The source of textual data is song lyrics of 11 rappers. Songs in 11 classic rap albums were collected as a dataset for this research work. Song lyrics were collected from famous Genius’ song lyrics database. album, on which sentiment analysis was performed.
2. Data collection and cleaning
Before collecting any data, author had to choose which artists’ songs he was going to collect. Initially, He decided to make the list of top 10 rappers of all time, but it changed slightly. In fact, it was the hardest thing at the beginning. Worth to mention that the list of the top 10 greatest rappers is a subjective thing, but if many people consider one rapper a top ten then probably, he is in top ten. So, author searched for such lists in Internet and found few rankings and mixed it with his views. Eventually author made a list of artists whose work was interesting for him.
Rappers throughout their career produce ton of songs and usually each album has its own story to tell. It would not be wise decision to do analysis on all the songs produced by the rappers in my list. Therefore, author has chosen one album for each artist and used songs in their albums as a data for my analysis. So, author’s final list consists of 11 artists and their albums, see the table 1.
Table 1
Albums to be analyzed
|
Artists |
Albums |
|
The Notorious B. I. G. |
Ready to Die |
|
Eminem |
The Marshall Mathers LP |
|
Nas |
Illmatic |
|
Rakim |
Paid in Full |
|
Jay Z |
Reasonable Doubt |
|
Tupac |
Me Against the World |
|
Fugees |
The Score |
|
Kendrick Lamar |
Good Kid M. a.a.d City |
|
Kanye West |
Graduation |
|
J Cole |
2014 Forest Hills Drive |
|
Logic |
Under Pressure |
Song lyrics were collected from the Genius.com, who has large song lyrics database. Moreover, they have made APIs for developers to access their data. To work with their APIs, one must register and authorize to website to get access token. Access token allows developer to make requests to Genius API to collect data about songs. Additionally, author has used library “LyricsGenius” by John W. Miller which acts as a convenient interface to work with Genius API. For the collected song lyrics see the figure 1.

Fig. 1. Raw dataset
Machine leaning model does not understand raw text data as humans do. Text must be cleaned and provided in a form which can be understood and processed by the computer. Therefore, data must be prepared before fitting data to models.
There exist many text cleaning techniques. The question whether you need to apply text cleaning techniques or not depends on your data and goals. However, before applying any techniques developer needs to determine what type of noises are exist in dataset. There are a lot of commas and inverted commas and other special characters. Such special characters add up to the overall volume of the noise, therefore such characters must be removed from the dataset. Song lyrics dataset also contains numbers. Without knowing context of the sentence retrieving sentiment score from numbers in the sentence is not possible, therefore in author’s case numbers do not bring any meaning as a result author has removed numbers from the dataset. Another way to normalize dataset is to lowercase all the text. It is done to avoid duplicate words.
For now, author has discovered several ways which can be used to clean text from noise. Noise types in dataset:
– Words in square brackets such as ‘ [Intro]’, ‘ [Verse 1]’, ‘ [Chorus]’, ‘ [Outro]’. Those words act as annotation and has no meaning to the audience.
– Commas, inverted commas, and other special characters
– Numbers
– Make text lowercase
After applying text cleaning techniques described above, author has got clean song lyrics data frame, see the figure 2.
Fig. 2. Cleaned text data 2
How does computer read the song lyrics dataset? We cannot just pass the dataset as a large string. Therefore, the dataset must be transformed into a format which is easy to work with for computer and understandable. One of such formats is Document Term matrix (Term Document matrix). It is a mathematical matrix which represents the frequency of terms that are encountered in document. Here document means any dataset or collection of data in any form. In the document term matrix, rows represent the documents in the collection, and columns correspond to terms.
When text data is processed as text data no as number, we can retrieve hidden values from the text data. One of methods which allows us to value text as a text is Bag of Words (BOW). Basically, it is just a list where stored distinct words in document and words’ number of occurrences [1].
Below you can see the document term matrix (DTM) generated for song lyrics dataset. Eleven rows represent the rappers they are considered as a document in the DTM model. 5670 columns represent unique words in the model.
Fig.3. Document term matrix for song lyrics
Song lyrics dataset in the form of DTM is ready for further processing. With help of DTM model we treat text data as a text and at the same time machine can understand this model. Because text data in DTM is represented as numerical structure which can be used to various calculations and analysis. It is just a starting point to further analysis, namely Exploratory Data Analysis (EDA).
3. Exploratory Data Analysis
After cleaning data and organizing data into one format, it is recommended to do ExploratoryData Analysis (EDA) to understand the data. Because if you do not understand your data you do not know what insights you want get from the dataset [2]. In the EDA step, author has focused on the following things for each rappers’ album:
- Most common words
- Depth of vocabulary
- Amount of profanity
Top 30 common words for each rapper allows see some patterns in the data. Below author has included the figure 4 where top 30 most used words for each rapper are listed.
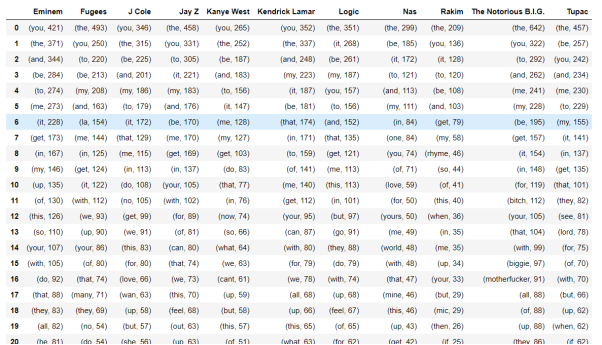
Fig. 4. Document term matrix for song lyrics
By looking at the figure 4, it is noticeable that many top used words are common for many rappers. As those words hide other interesting words by which albums can be differentiated. Therefore, such words will be removed from the dataset. Rule for deleting above words is ‘If more than half of the rappers have it as a top word, exclude it from the list’. After removing common words, author has created a word cloud for his dataset. Representing most used words in word cloud is good visualization. Word cloud gives opportunity to see and analyze findings.

Fig. 5. Word cloud of most used words
Vocabulary of rappers is one of the things which differentiates rappers. Comparing vocabulary among albums is relatively not fair as there is no standard on the number of songs in one album. Because of this comparing vocabulary is not accurate. Number of unique words can be used to analyze one rapper’s vocabulary. Often albums have into song, which is about 30 sec song. Also, there are some short audios, technically it would be wrong to call them song, with the length about 30 sec. For instance, Eminem’s The Marshall Mathers LP album has officially 18 songs. However, 2 of them short audios which are not full songs. So, there are 16 full-fledged songs. Author have created table where first column indicates rapper, second column indicates album name, third indicates officially listed songs and fourth is the actual number of full-fledged songs.
Table 2
Number of unique words
|
Rapper |
Album |
Unique words |
Actual songs |
|
Rakim |
Paid in Full |
810 |
9 |
|
Kanye West |
Graduation |
1099 |
15 |
|
Logic |
Under Pressure |
1249 |
13 |
|
J Cole |
2014 Forest Hills Drive |
1278 |
13 |
|
Nas |
Illmatic |
1424 |
10 |
|
Tupac |
Me Against the World |
1492 |
14 |
|
The Notorious B. I. G. |
Ready to die |
1828 |
18 |
|
Fugees |
The Score |
1850 |
18 |
|
Eminem |
The Marshall Mathers LP |
1945 |
16 |
|
Kendrick Lamar |
Good Kid M. a.a.d City |
1945 |
12 |
|
Jay Z |
Reasonable Doubt |
1949 |
16 |
To eliminate non-standard number of songs in the albums, author has calculated the number of unique words per song, it gives more accurate comparison.
Table 3
Number of unique words per song
|
Rapper |
Album |
Unique words per song |
|
Kendrick Lamar |
Good Kid M. a.a.d City |
162 |
|
Nas |
Illmatic |
142 |
|
Jay Z |
Reasonable Doubt |
121 |
|
Eminem |
The Marshall Mathers LP |
121 |
|
Tupac |
Me Against the World |
107 |
|
Fugees |
The Score |
103 |
|
The Notorious B. I. G. |
Ready to die |
102 |
|
J Cole |
2014 Forest Hills Drive |
98 |
|
Logic |
Under Pressure |
96 |
|
Rakim |
Paid in Full |
90 |
|
Kanye West |
Graduation |
73 |
Above table is identification of how album is lyrically deep. Look at how Kendrick’s album stands above other, 20 more words than the Nas’ Illmatics album. By looking at the table 6, we probably did not pay attention to the works of Nas and Tupac. But with the help of above table we can easily say whose album is lyrically richer.
One thing which catches attention is the curse words in the word cloud, figure 5. Many curse words were not collected to the word clouds. Some of them were removed from the dataset. To see which rapper uses curse words most analysis should be done on the untouched dataset. There probably lots of curse words, but author look for f-words, s-words, m-words, b-words, and sh*t words. Author has combined words whose base is same, but because of slangs ending differ, for instance f-words had two types and m-words had two types. Below in the figure 6, you can see the number of each curse words for each rapper. Biggie Smalls and Eminem have used f-words a lot in their albums. In fact, they have used f-words so much, that number of f-words used by third ranked rapper is about twice less. On the other hand, look at the Rakim’s album which has no f-words. Not only f-words, Rakim’s album ‘Paid In Full’ has no curse words only sh*t word occurred twice. This fact distinguishes Rakim’s album from others. Second in not using f-words is Kanye West with only 9 f-words, but he has used a lot of sh*t words.
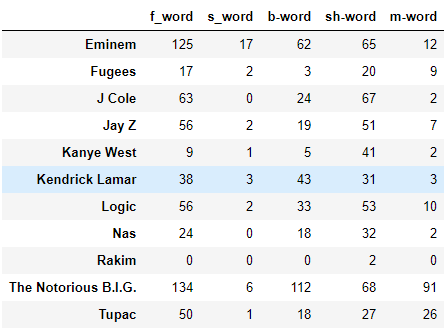
Fig. 6. Number of curse words
By analysing figure 6 one could say that there are a lot of curse words. However, more accurate number can be determined if we calculate curse word usage in the album. To calculate that divide total number of curse words on total number of words used in the album. As a result author illustrates the graph in the figure 7 below.
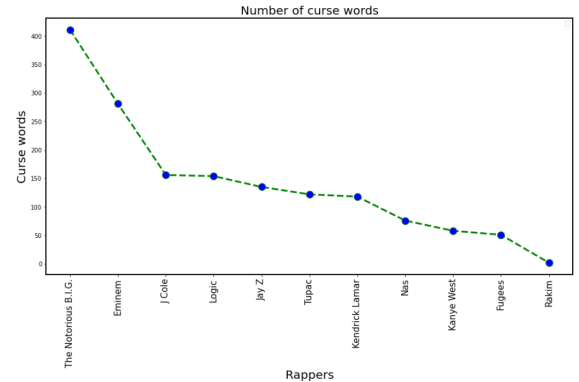
Fig. 7. Line graph of number of curse words used
From the figure 40 and 41 it is clear that Biggie Small have used a lot of bad words almost 8 % of his album consists of bad words. This is quit big number. While Rakim’s album does not even reach 0.2 %. The curse word percentage usage will definetely affect on the sentiment of the albums.
- Sentiment Analysis
Sentiment analysis is one of techniques in the NLP which determines emotion in the text. There are some terms which needs to be clarified before introducing practical results.
First term is polarity. Polarity describes emotions in the text. Emotions expressed in the text might be positive or negative. If the emotions expressed in the sentence is negative, then polarity for the sentence will be negative value. While positive sentence will have positive value for polarity.
Second term is subjectivity. It describes whether given sentence is someone’s opinion, belief, or personal view. If sentence is about facts, then sentence is closer to the objectivity.
Input data format for this stage is a corpus, not document term matrix. Because in document term matrix words are separated and order of words is lost. Order of words is crucial for sentiment analysis, because take for example sentence ‘Laptop’s battery is not good’. If you applied sentiment analysis for DTM model of the example sentence, then word ‘not’ would get separated from word ‘good’. Thus, leading to incorrect calculations. Therefore, to keep the order of words, input data will be in the format of whole text (corpus). In the figure 8 below, you can see the python dataframe with polarity and subjectivity columns for each artist.
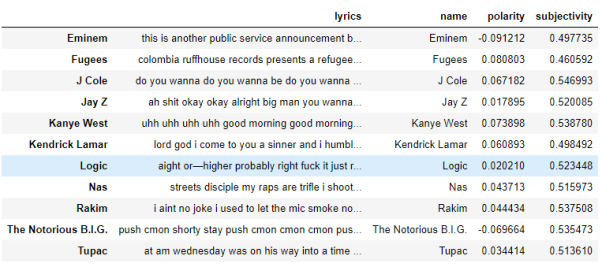
Fig. 8. Dataframe with sentiment for each artist
Song lyrics data in the sentiment dataframe was used to plot a graph. In which the y-axis describes subjectivity and the x-axis polarity. According to the graph, only Eminem and Biggie Smalls have negative polarity. This is not surprise to me, as those two artists had the most curse words usage percentage, see the figure 9.
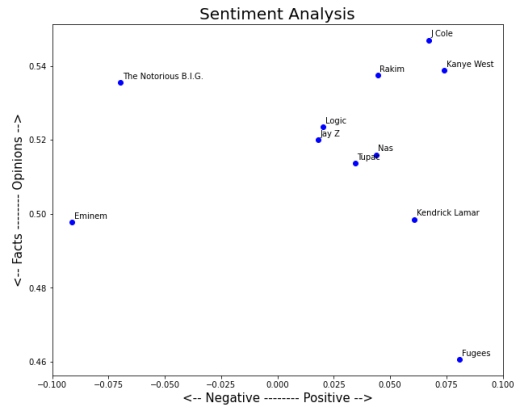
Fig. 9. Sentiment analysis graph
Rappers like Jay Z, Logic, Tupac, Nas are close to the zero in terms of polarity. This is probably because they had a lot of curse words. For those rappers mentioned above, there was a pattern. More curse words more negative is polarity. However, I cannot say that less curse words means less negative is polarity. Because, by comparing Rakim’s album polarity and curse words usage I understood that amount of curse words is not the only one parameter for polarity. Totally opposite situation of Rakim’s case happened with J Cole. J Cole has 3 rd most curse word usage percentage yet still his album is predicted as an overall positive album.
5. Conclusion
In general, 9 albums were predicted as positive. Where four of them had sentiment score more than 0.05 which are Fugees’ ‘The Score’, Kendrick Lamar’s ‘Good Kid M. a.a.d City’, J Cole’s ‘2014 Forest Hills Drive’ and Kanye. Polarity scores for albums were not as author expected them to be. Most of albums were labelled as positive, only 2 albums were negative. Those albums are Eminem’s ‘The Marshall Mathers LP’ and Biggie Small’s ‘Ready to Die’. Finding which were derived during the EDA analysis were useful especially number of curse words. Author have noticed that amount of curse words is not the main factor for sentiment being negative. Album with the least curse words is not guaranteed to have positive polarity score. It can be seen when you compare polarity score of Rakim’s and J Cole’s albums.
References:
- Darrin Bishop. Text Analytics — Bag of Words, 2017. Retrieved from http://www.darrinbishop.com/blog/2017/09/text-analytics-bag-of-words/
- Prasad Patil. What is Exploratory Data Analysis? 2018. Retrieved from https://towardsdatascience.com/exploratory-data-analysis-8fc1cb20fd15

