





Современный этап развития интернет-технологий связан с всё большим охватом потребителей услугами электронных сервисов, основанных на реализации распределённых технологий, обеспечивающих возможность сократить затраты предприятий предоставляющих услуги различного рода, в частности услуги по обслуживанию компьютерной техники, как на сопровождение программного продукта, так и на потребляемые вычислительные мощности. При этом развитие конкуренции требует всё более развитых методов привлечения клиентов, что в свою очередь приводит к необходимости внедрения новых сервисов, обеспечивающих клиентов дополнительными услугами в зависимости от их интересов.
Актуальность выбранной темы обосновывается тем, что на современном этапе развития мира все большую необходимость приобретает автоматизация управления действиями, в том числе исполнение, управление и контроль задач. С помощью технологий разработки автоматизации таких действий можно создать по-настоящему сложные системы, которые очень сильно облегчат жизнь и упростят планирование и анализ времени. Необходимость разработки таких систем увеличивает развитие машинного обучения, с помощью которого можно сделать поистине.
Распределенная информационная система в узком смысле, с позиции программного обеспечения (ПО) это совокупность взаимодействующих друг с другом программных компонентов. Каждый из таких компонентов может рассматриваться как программный модуль (приложение), исполняемый в рамках отдельного процесса.
При рассмотрении архитектуры системы есть несколько вопросов, которые необходимо осветить, например: какие компоненты стоит использовать, как они совмещаются друг с другом, и на какие компромиссы можно пойти. Вложение денег в масштабирование без очевидной необходимости в ней не может считаться разумным деловым решением. Однако, некоторая предусмотрительность в планировании, может существенно сэкономить время и ресурсы в будущем.
В данной работе необходимо спроектировать и создать распределенную информационную систему исполнения, управления и контроля задачами на примере сервиса для контроля тренировок спортсменов.
Важной частью работы будет создание алгоритма контроля тренировочного процесса, так как данный метод отсутствует практически во всех современных системах.
Разработка алгоритма анализа и контроля тренировочного процесса на основе машинного обучения
Цель проекта — предсказать, каким образом спортсмены выполняли упражнение и на основании результата дать совет как выполнять его правильнее. В итоге должен получиться алгоритм рекомендации пользователю правильности выполнения упражнения для более детального контроля тренинга.
Всего есть 5 разных классов для представления результатов и рекомендаций:
– класс А — точно по спецификации;
– класс B — бросание локтей вперед;
– класс C — поднимать гантели только наполовину;
– класс D — опускание гантели только наполовину;
– класс E — бросание бедер вперед.
Изначальные данные были взяты с открытого ресурса, которые сформированы благодаря спортивному браслету и предполагаются для обучения системы. Все упражнения в этом наборе выполнял профессиональный спортсмен в точном соответствии со всеми стандартами. Очень малая часть данных представлена в таблице 1.
Таблица 1
Данные для обучения
|
user_name |
roll_belt |
pitch_belt |
total_accel_belt |
raw_timestamp_part_2 |
raw_timestamp_part_2 |
|
carlitos |
1,41 |
8,07 |
-94,4 |
NA |
NA |
|
carlitos |
1,41 |
8,07 |
-94,4 |
NA |
NA |
|
carlitos |
1,42 |
8,07 |
-94,4 |
NA |
NA |
|
carlitos |
1,48 |
8,05 |
-94,4 |
NA |
NA |
Тестовые данные, которые впоследствии будет необходимо анализировать представлены с некоторым набором анализируемых данных и соответствуют тем же параметрам что и в обучающем наборе, но уже для 20 различных тестовых случаев, в которых люди выполняли упражнения точно в соответствии с классами ошибок. Эта часть работы нужно для проверки правильно обучения. В таблице 2 представлены пять тестовых случаев.
Таблица 2
Данные для анализа тестовых случаев
|
user_name |
roll_belt |
pitch_belt |
total_accel_belt |
raw_timestamp_part_2 |
raw_timestamp_part_2 |
|
Jeremy |
1,02 |
4,87 |
-88,9 |
NA |
NA |
|
Adelmo |
0,87 |
1,82 |
-88,5 |
NA |
NA |
|
Eurico |
1,35 |
3,33 |
-88,6 |
NA |
NA |
|
Pedro |
1,02 |
1,59 |
-87,3 |
NA |
NA |
Для расшифровки переменных и понимания их значений можно обратиться к приложению А1.
Это довольно малая часть столбцов, также есть множество имеющих численные переменные и множество имеющих пустые значения или значения NA. Пустые значения, значения NA и значения, мало влияющие на точность прогноза, будут очищены. Узнать, какие переменные имеют наибольший вес, можно будет увидеть далее, когда будет построена корреляционная матрица.
Перед составлением самой программы, необходимо загрузить и обучить данные. Далее необходимо очистить данные от множества ненужных для анализа столбцов. После удаления можно будет посмотреть сколько полезных переменных остается в фрейме данных. Эти процессы выполняются на обучающем наборе, проверочном наборе и тестовом наборе, поскольку предполагается, что все три набора происходят из одного и того же распределения.
Анализ показывает, что наивная байесовская модель работает плохо (точность = 23,94 %) по сравнению со случайным лесом (точность = 99,95 %). Это говорит о том, что случайный лес более предпочтительная модель.
Для прогнозирования было необходимо рассмотреть подробнее точность прогнозирования с частотой ошибки, в таблице 3 можно увидеть результат прогнозов. Приведенная ниже матрица показывает, какие прогнозы в тестируемом подмножестве были правильными, а какие — нет. Прогнозы основаны на столбцах, а строки — на фактических значениях. Недиагональные элементы — это ошибки.
Таблица 3
Матрица точности прогнозирования тестового набора
|
|
A |
B |
C |
D |
E |
|
A |
2225 |
14 |
0 |
0 |
0 |
|
B |
5 |
1497 |
15 |
0 |
1 |
|
C |
1 |
6 |
1345 |
22 |
0 |
|
D |
0 |
1 |
8 |
1263 |
1 |
|
E |
1 |
0 |
0 |
1 |
1440 |
Связи между количественными переменными можно представить в виде корреляционной матрицы. Корреляционная матрица всегда симметрична (коэффициент корреляции между переменными X и Y равен коэффициенту корреляции между переменными Y и X).
Корреляционная матрица переменных показана на рисунке 1. Данная матрица показывает то, какие переменные влияют на точность прогноза, а также эти что переменные имеют строгую и прямую связь.
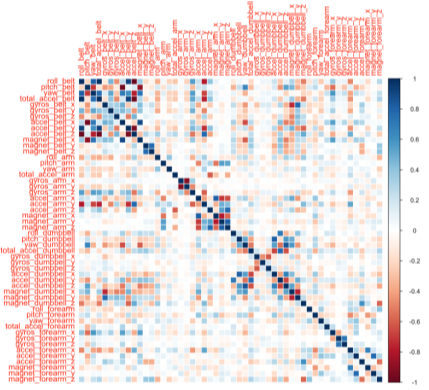
Рис. 1. Корреляционная матрица переменных
Необходимо визуализировать дерево решений, которое поможет понять, как та или иная переменная влияет на выбор ошибки выполнения. Визуализация дерева решений продемонстрирована на рисунке 2.

Рис. 2. Визуализация дерева решений
Теперь, на основе дерева решений, можно попробовать сделать прогноз и после этого посмотреть, как точно программа определить класс ошибки выполнения. Были взяты значения 2 претендентов под порядковыми номерами 6,7.
Определим класс для участника с именем Jeremy в таблице 4, следуя строго по дереву решений. Мы видим, что последнее значение — 0,13, что является классом E.
Таблица 4
Значения для участника сименем Jeremy
|
roll_belt |
pitch_forearm |
magnet_dumbbell_y |
roll_forearm |
accel_forearm_x |
magnet_dumbbell_z |
gyros_belt_z |
|
-5,92 |
1,46 |
262 |
150 |
230 |
96 |
0,13 |
Определим класс для участника с именем Jeremy в таблице 6, следуя строго по дереву решений. Мы видим, что последнее значение — 15, что является классом D.
Таблица 5
Значения для участника сименем Eurico
|
roll_belt |
pitch_forearm |
magnet_dumbbell_y |
roll_forearm |
accel_forearm_x |
magnet_arm_y |
|
1,2 |
34,5 |
354 |
155 |
-192 |
15 |
Далее, необходимо перейти к результатам прогнозирование тестового набора. Для каждого тестового набора получены рекомендации и теперь каждый спортсмен может контролировать процесс выполнения. Результат прогнозирования можно увидеть на рисунке 3.
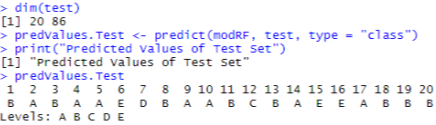
Рис. 3. Результат прогнозирования
Сравнивая результаты участников 6 и 7 из анализа по дереву решений самостоятельно и анализа с помощью программы можно сделать вывод, что модель делает точный прогноз и программа работает хорошо.
Для интеграции с задачами проекта необходимо модифицировать программу, чтобы при использовании одним человеком она не только давала класс ошибки, но и давала рекомендации по ошибкам выполнения и их влиянию на человека, а также правильному выполнению упражнению. Для этого, нужно дополнить классы тестовым описанием ошибок и рекомендаций по выполнению.
После выполненных действий, нужно провести прогнозирование одного набора данных для одного участника и дать ему рекомендации. Прогнозирование для одного участника можно увидеть на рисунке 4.

Рис. 4. Прогнозирование результата выполнения упражнения для участника под именем Jacki
Таким образом, программу можно использовать для прогнозирования результата выполнения упражнения. Пользователи смогут точно знать, что и как они неправильно делали и в итоге, контролировать тренировочный процесс.
За основу разработки была взят алгоритм на основе машинного обучения, который будет учиться советовать спортсмену правильность выполнения упражнений и рекомендации на основе сделанных ошибок. Важным аспектом разработки являлся выбор языка, в итоге выбор пал на язык R, так как он может работать с большими массивами данных и обладает рядом встроенных библиотек. Методами анализа данных было решено использовать случайный лес и наивный байесовский классификатор, чтобы понять какой из них будет наиболее эффективен. Алгоритм основывается на 2 массивах данных: тестового и прогнозируемого. На тестовых данных происходило обучение системы, чтобы в итоге спрогнозировать ошибки выполнения из 2 набора данных. В итоге, была разработана программа, которая просчитывает то, как человек выполнял упражнение и дает совет по правильному выполнению, а также то, чем может обернуться такое неправильное выполнение упражнение.
Литература:
1 Домингос, П. Верховный алгоритм. Как машинное обучение изменит наш мир [Текст] / П. Домингос. — М.: Манн, Иванов и Фербер, 2016. — 656 c.
2 Breiman, L. Random forests [Текст] / L. Breiman. — Berkeley: Statistics Department, 2019. — 32 p.
3 Qualitative Activity Recognition of Weight Lifting Exercises [Электронный ресурс] // Groupware@LES: свободный ресурс. — Электрон. дан. — [Б. м.], 2020. — URL: http://groupware.les.inf.puc-rio.br/public/papers/2013.Velloso.QAR-WLE.pdf (дата обращения: 06.05.2020).
4 Commonly used Machine Learning Algorithms (with Python and R Codes) [Электронный ресурс] // Analytics Vidhya: свободный ресурс. — Электрон. дан. — [Б. м.], 2017. — URL: https://www.analyticsvidhya.com/blog/2017/09/common-machine-learning-algorithms/ (дата обращения: 26.04.2020).
