В последнее время термин Big Data очень часто встречается в жизни многих людей, но не все люди знают. что это такое. В этой статье рассматриваются технологии для работы с BigData. Также в статье рассматриваются свойства больших данных и сферы, где применяются технологии работы с BigData.
Ключевые слова: BigData, технологии, большие данные, NoSQL, Hadoop, MapReduce.
Большие данные (Big Data) — это обозначение структурированных и неструктурированных быстро поступающих данных огромных объёмов и значительного многообразия, а также методы их обработки, которые позволяют распределенно обрабатывать получаемую информацию.
Термин Big Data появился в 2008 году. Впервые его употребил редактор журнала Nature Клиффорд Линч. Он рассказывал про взрывной рост объемов мировой информации и отмечал, что освоить их помогут новые инструменты и более развитые технологии. Рост объема памяти в устройствах с течением времени показан на рисунке 1.
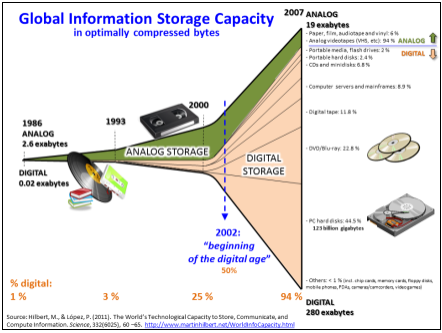
Рис. 1. Эволюция объема памяти в устройствах
Когда говорят о Big Data, упоминают правило 3V — это три свойства, которыми должны обладать большие данные:
- Объем (Volume) — данные измеряются по величине физического объема документов.
- Скорость (Velocity) — данные регулярно обновляются, что требует их постоянной обработки.
- Разнообразие (Variety) — разнообразные данные могут иметь неоднородные форматы, быть неструктурированными или структурированными частично.
Следуя из свойств, описывающих Big Data, программистам необходимо разрабатывать информационные системы для работы с большими данными обладающими следующими характеристиками [1]:
- Горизонтальной масштабируемостью — базовым принципом обработки больших данных. В основе этого принципа лежит необходимость в увеличении вычислительной мощности для распределения обрабатываемой информации без ухудшения производительности всей системы.
- Локальностью данных — принципом, который гарантирует, что данные будут обработаны на той же машине, на которой они и хранятся.
- Отказоустойчивостью — принципом, который гарантирует что при выходе из строя одного или нескольких вычислительных узлов вся система продолжит работать без сбоев и ухудшения производительности.
В современных системах также могут рассматриваться два дополнительных свойства, которыми могут обладать большие данные [2]:
− Изменчивость (Variability) — потоки данных могут иметь пики и спады, сезонности, периодичность. Всплески неструктурированной информации сложны в управлении, требует мощных технологий обработки.
− Значение данных (Value) — информация может иметь разную сложность для восприятия и переработки, что затрудняет работу интеллектуальным системам. Например, массив сообщений из соцсетей — это один уровень данных, а транзакционные операции — другой. Задача машин определить степень важности поступающей информации, чтобы быстро структурировать.
На сегодняшний день существует множество технологий для работы с Big Data.
MapReduce — это технология представлена компанией Google. Принцип данной технологии сводится к разделению приложения на большое количество простых заданий, которые выполняются на узлах вычислительной системы. После обработки выполнения простых заданий полученные данные сводятся в итоговый результат.
NoSQL — это общий термин обозначающий ряд подходов, направленных на реализацию систем управления базами данных. NoSQL хорошо подходит, когда требуются производительные, гибкие, масштабируемые базы данных с широкими функциональными возможностями.
Hadoop — это набор утилит, библиотек и фреймворков для разработки и выполнения распределённых программ.
Big Data внедряется и используется во многих различных областях, например, в ритейле Big Data используется для анализа действий клиентов, и построения на основе этих данных будущей стратегии компании. Или же в здравоохранении для аналитики истории болезней пациентов, планов лечений, клинических анализов, генетических исследований. Так же Big Data используется в банковском секторе для минимизации кредитных рисков.
На сегодняшний день работа с Big Data не очень распространена среди людей из-за дороговизны проектов. Средняя стоимость проекта составляет около 8 миллионов долларов. Поэтому не каждое предприятие может позволить себе использовать такие дорогостоящие инвестиции. Но технологии и вычислительные мощности необходимые для работы с BigData развиваются и дешевеют и это означает что в скором будущем человечество все больше будет опираться на работу с большими данными.
Литература:
- Uplab [Электронный ресурс]: — Режим доступа: https://www.uplab.ru/blog/big-data-technologies/, свободный (дата обращения: 28.1.2020). — Загл. с экрана.;
- Itenterprice [Электронный ресурс]: — Режим доступа: https://www.it.ua/ru/knowledge-base/technology-innovation/big-data-bolshie-dannye, свободный (дата обращения: 28.1.2020). — Загл. с экрана.

