





В современном мире, особенно в России, наблюдается ряд проблем в государственном и муниципальном управлении.
Российская Федерация занимает первое место в мире по территории и включает в себя 85 различных субъектов, со своими особенностями и единой конституцией. Целью моей работы стала оценка регионального управления, развития каждого из регионов. Проблема данной задачи в том, что количество данных о каждом субъекте крайне велико, достаточно трудно определить нужную для оценки характеристику. Для решения данной задачи необходимо составить базу данных по всем субъектам Российской Федерации и всем характеристикам за 15 лет, и выявить «главные» с помощью метода главных компонент (PCA).
Для решения этой задачи был собран объем информации за 15 лет (с 2002 по 2016) из основных государственных ресурсов Российской Федерации таких, как: «федеральная служба государственной статистики», «Росстат».
База данных осуществлена в приложении Excel. Была разработана программа на языке Python для выборки и заполнении нужных данных и представлении в правильном виде. По итогу было получено 57385 характеристик различных субъектов Российской федерации. Рассмотрены основные макроэкономические показатели, собираемые Росстатом.
Метод главных компонент (PCA) — это статистическая метод, который использует ортогональное преобразование для преобразования набора наблюдений возможных коррелированных переменных в набор значений линейно некоррелированных переменных, называемых главными компонентами.
Сущность метода:
Матрица числовых признаков:
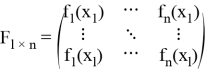
Матрица новых числовых признаков:
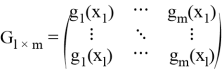
Матрица линейного преобразования новых признаков в старые:
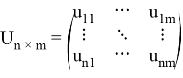 ;
; ![]()
Необходимо найти: Новые признаки G и преобразования U,чтоб минимизировать функционал:
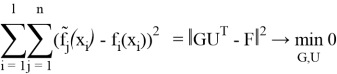
В результате применения метода к полученной мной базе данных 45 используемых нами характеристики оказались «свернутыми» в четыре главных компоненты. Эти компоненты устанавливают наибольший процент сходств и различий между субъектами в рамках определенных сочетаний индексов. Первая компонента объясняет от 75 до 99 % дисперсии значений индексов, вторая — от 1 до 15 %, третья — от 1 до 5 %, четвертая — 1 до 3 % в зависимости от субъекта. Столь высокий объяснительный потенциал первой компоненты косвенно подтверждает правильность выбора сгруппированных в индексы показателей. Сочетание первой и второй компонент дает объяснение почти 92 % сходств и различий между субъектами, добавление третьей повышает эту долю до 97 %, а четвертой — до 100 % по каждому региону.
Первая компонента отвечает за уровень жизни, да составления индекса уровня жизни использовались такие характеристики, как:
− ВВП на душу населения;
− Индекс физического объема инвестиций в основной капитал;
− средняя продолжительность жизни;
− расходы на здравоохранение на душу населения
Вторая компонента отражает уровень безработицы, для составления индекса использованы:
− Объем платных услуг на душу населения
− Численность безработных
− Средний размер назначенных месячных пенсий
Третья компонента отражает уровень правонарушений. Использованы такие характеристики, как:
− Число преступлений, совершенных несовершеннолетними и при их соучастии
− Коэффициенты миграционного прироста
− Число зарегистрированных убийств и покушений
Четвертая компонента описывает развитие сельскохозяйственных структур в различных регионах. При составлении индекса сельскохозяйственных структур мы использовали параметры такие, как:
− Продукция сельского хозяйства
− Посевные площади всех сельскохозяйственных культур
− Посевные площади овощей
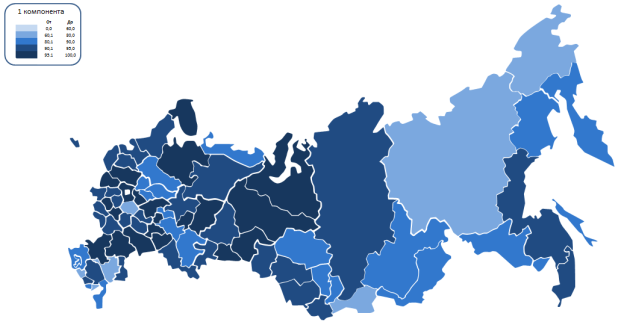
Для наглядности полученных мной результатов была составлена цветовая карта, отражающая изменение определенной компоненты. Таким образом, мы можем увидеть, в каком регионе администрация уделяет больше или меньше внимания какому-либо параметру. На следующем рисунке отображена первая компонента, отвечающая за уровень жизни населения. Легко заметить, что в центральной России преобладает высокий уровень жизни и экономического развития, в отличие от северной части. Это означает, что государство и региональные органы власти вкладывают значительно большее количество сил и средств в данные субъекты. Но результат исследования получен в ходе статистического анализа, который осуществлен на основе статистических государственных данных, поэтому результат может отличаться от реальности.
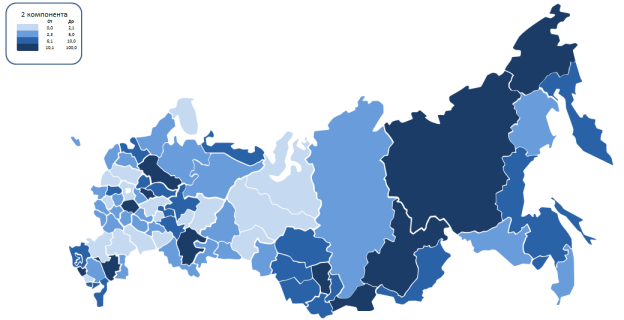
На рисунке ниже отображена вторая компонента, отвечающая максимальную безработицу и минимальную заработную плату. Значение этой компоненты преобладает в северной части Российской Федерации, в отличие от центральной.
Российская Федерация очень велика, количество особенностей каждого субъекта так же крайне велико, в моем случае метод особо оптимален, из 45 характеристик получилось выделить 4 «главные». Благодаря этим компонентам можно делать выводы о развитии и качестве регионального управления какого-либо субъекта Российской Федерации.
Литература:
- Сайт Федеральной службы статистики http://www.gks.ru
- Jolliffe, I. T. Principal Component Analysis, second edition (Springer). (2002)
- Воронцов К.В курс лекций «Машинное обучение». 2009
- А. Ю. Мельвиль, М. В. Ильин, Е. Ю. Мелешкина, М. Г. Миронюк, Ю. А. Полунин, И. Н. Тимофеев «ПОЛИТИЧЕСКИЙ АТЛАС СОВРЕМЕННОСТИ». (2008)
- Husson François, Lê Sébastien & Pagès Jérôme. Exploratory Multivariate Analysis by Example Using R. Chapman & Hall/CRC The R Series, London. 224p. (2009)
