Одна из проблем современной информации это разнообразие современных данных. Под разнообразием понимается не только различные форматы данных, от текстовых файлов до файлов мультимедиа, но и различие в структуре такой информации. Именно структура данных требует нового подхода к обработке для получения полезных знаний из огромного потока данных. Рассмотрим какие данные называются структурированными и неструктурированными и обозначим проблему перехода между этими данными.
Структурированные данные — это информация, упорядоченная определенным образом и организованные с целью обеспечения возможности применения к ним некоторых действий (например, визуального или автоматизированного анализа). Такие данные находятся в фиксированном формате записи, понятной для машины. Классической моделью хранения структурированных данных является таблица. В ней все данные упорядочиваются в двумерную структуру, состоящую из столбцов и строк. В ячейках такой таблицы содержатся элементы данных определенного формата: символы, числа, логические значения. [1]
Сделаем выводы о важных особенностях структурированных данных исходя из определения. Важнейшим является то, что структурированные данные — это информация, уже подготовленная к анализу и уже содержащая конкретные знания. Такая информация не требует обработки для получения из них каких-либо необходимых данных. Они отражают отдельные факты предметной области, основная форма представления данных в классических реляционных базах данных. Методов и средств хранения и обработки такой информации огромное множество и все они эффективно исполняют свою задачу.
Другим типом современных данных являются неструктурированные и слабоструктурированные данные. Дадим определение понятию неструктурированные данные, обозначим что относят к неструктурированным данным и изучим почему такие данные называются неструктурированными.
Неструктурированные данные — это информация, которая либо не имеет заранее определенной структуры данных, либо не организована в установленном порядке, понятного для машины. Неструктурированные данные непригодны для обработки напрямую методами анализа данных, поэтому такие данные подвергаются специальным приемам структуризации, причем сам характер данных в процессе структуризации может существенно измениться. [2]
Термин «неструктурированные данные» может считаться неточным по нескольким причинам:
– Структура, даже если она не определена формально, может подразумеваться.
– Данные, обладающие структурой некоторой формы, могут по-прежнему характеризоваться как неструктурированные, если их структура не предназначена для машинной обработки.
– Неструктурированная информация может иметь некоторую структуру или даже быть хорошо структурированной, но теми способами, которые являются неочевидными без предварительного согласования.
К неструктурированным данным относят данные на естественном языке, машинные, графовые, потоковые, аудио, видео и графические данные.
В качестве примера неструктурированных данных рассмотрим электронное письмо.
Электронное письмо обычно содержит дату отправления, имена отправителя и получателя, тело письма. То есть оно имеет структуру в привычном человеку понимании. Однако без структуризации и использования средств хранения и анализа с такими данными невозможно работать и получить какие-либо конкретные необходимые знания. Так же стоит заметить, что информация, содержащаяся в электронном письме в зависимости от контекста и задачи нужна разная, например, для одной задачи нам нужна дата, для другой содержание письма в отношении какого-либо слова. То есть такие данные нужно хранить в первоначальном виде и с помощью специальных средств извлекать из него нужное в понятный для машины формат, то есть привести неструктурированные данные к структурированному формату.
Теперь обозначим понятие слабоструктурированные данные. Оно детализирует термин «неструктурированные данные» и корректирует его неточности.
Слабоструктурированные данные — это данные, понятные для машинного распознавания, но все еще требующие неких преобразований для получения конкретной информации из неё. Если в примере с электронным письмом, пользователю этой информации сначала нужно понять какова структура письма и что в нем содержится, то слабоструктурированные данные имеют специальную строгую понятную машине структуру. Однако такие данные все еще не являются структурированными относительно термина, так как они не имеют привычный для использования формат таблицы.
В качестве примера рассмотрим файл формата JSON — текстовый формат обмена данными, основанный на JavaScript. На рисунке 1 представлен пример структуры JSON-массива данных:
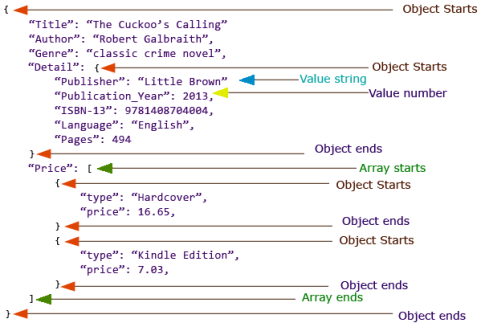
Рис. 1. JSON — массив
На рисунке видно, что у массива есть структура данных и он может быть легко прочитан как человеком, так и машиной. Однако, такой массив все еще не поддается анализу классическими методами реляционных баз данных и средств анализа. Поэтому прочтение слабоструктурированного массива и извлечение данных оттуда является основной задачей конечного перехода от неструктурированного к структурированному типу данных. Обычно в контексте обработки информации, слабоструктурированное состояние является неким промежутком между неструктурированными и неструктурированными данными.
Как вывод можно обозначить, что проблема разнообразия современной информации заключается в реализации перехода из неструктурированных и слабоструктурированных данных к структурированной информации для её дальнейшего использования. Если речь идет об неструктурированной информации, то необходимо определить содержимое неструктурированного массива данных. Понять, как извлечь такие данные. После извлечения необходимого содержимого нужно преобразовать необходимую часть неструктурированной информации из неструктурированного объекта в структурированный вид, и загрузить преобразованные данные в привычные средства хранения и анализа. Для дальнейшего использования. Для слабоструктурированных данных использования похожий, но обычно минуется этап извлечения данных, так как они имеет понятный машине вид.
Литература:
- Типы данных в data science [Электронный ресурс]. — Режим доступа: http://soc-research.info/blog/index_files/bdtd.html. — Заглавие с экрана. — (Дата обращения: 26.04.2019).
- Неструктурированные данные 2.0 [Электронный ресурс]. — Режим доступа: https://www.osp.ru/os/2012/04/13015772/– Заглавие с экрана. — (Дата обращения: 10.05.2019).

