





На текущий момент у глобальных корпораций, компаний и других учреждений становится слишком много данных, которые необходимо обрабатывать и извлекать финансовый эффект. На IT-рынке возникла большая потребность на специалистов, которые могут анализировать большие данные, составлять математические модели с помощью цифровых технологий и извлекать прибыль для компаний. В данные технологии входят Data Mining, Machine Learning, Deep Learning, NLP, NLG и пр.
В данной статье будет производиться разбор методов для NLG, для извлечения информации из текстов и формирование данных в осмысленные вопросы и ответы, начнём с ключевых понятий:
NLG — natural language generation, в переводе генерация на естественном языке, является одной из задач обработки естественного языка (NLP — natural language processing), которая фокусируется на создании естественного языка из неструктурированных данных.
Интеллектуальная система — это техническая или программная система, способная решать задачи, традиционно считающиеся творческими, принадлежащие конкретной предметной области, знания о которой хранятся в памяти такой системы. Структура интеллектуальной системы включает три основных блока — базу знаний, механизм вывода решений и интеллектуальный интерфейс. [1].
Образовательный контент — вопросы по предметной области из первоначального материала в виде статьи, книги, рецензии и пр., а также осмысленные ответы к данным вопросам.
Формально, учитывая отрывок из текста, вопросно-ответная система извлекает понятную сущность S из предложения P. Затем система формирует пары вопрос-ответ {(![]() }, где каждый сгенерированный ответ
}, где каждый сгенерированный ответ ![]() может быть найден в сущности S и пара к этому ответу
может быть найден в сущности S и пара к этому ответу ![]() является вопросительной версией сущности S или частью предложения
является вопросительной версией сущности S или частью предложения ![]() из суммы частей предложения
из суммы частей предложения ![]() в этой сущности S. Архитектура данной системы:
в этой сущности S. Архитектура данной системы:
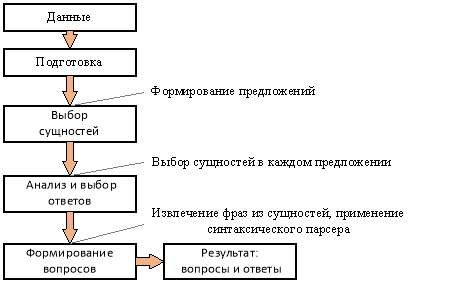
Рис. 1. Архитектура вопросно-ответной системы
Подготовка — происходит обработка предложений от ненужной информации из данных, формируются сущности.
Выбор сущностей — в этом пункте архитектуры извлекаются наиболее значимые из множества сущностей {![]() . Вычисление значимости происходит из методов текстовой суммаризации, к данным методам относятся MWPE, TextRank и LSA.
. Вычисление значимости происходит из методов текстовой суммаризации, к данным методам относятся MWPE, TextRank и LSA.
Анализ и выбор ответов — выбираются фразы из сущности S, они могут быть использованы как ответы {
Формирование вопросов — создается версия сущности S с вопросом или часть предложения ![]() ∈ {
∈ {![]() } в сущности S без
} в сущности S без ![]() , чтобы задать вопрос для каждого ответа в множестве {
, чтобы задать вопрос для каждого ответа в множестве {![]() }. Также в этом пункте формируются пары вопрос-ответ {(
}. Также в этом пункте формируются пары вопрос-ответ {(![]() }, которые подходят к предложению P.
}, которые подходят к предложению P.
Результат: вопросы-ответы. В этом конечном пункте архитектуры располагаются все сформированные вопросы и ответы по данным. Примерно так и работают существующие вопросно-ответные системы, основанные на датасетах (большого количество вопросов и ответов, в ключе данной задачи, для обучения математических моделей) англоязычной версии Stanford Question Answering Dataset (SQuAD) [3] и русскоязычной версии Сбербанка SDSJ task B [4].
Далее будут описаны модели для извлечения сущностей MWPE, TextRank и LSA.
TextRank — метод суммаризации текста, где располагается модель ранжирования для графов извлеченных из текстов с естественным языком. Модель делает предположение, что самые важным предложения являются те, которые наиболее похожи на любое другое предложение в корпусе естественного языка. Сходство может вычислено с использованием методов косинусного сходства [5] или коэффициента Жаккара [6]. Модель использует алгоритм PageRank [7] от поиска Google, чтобы оценить важность предложения в отрывке. TextRank выполняет следующие действия:
− Каждая сущность в предложении P в графике добавляется как вершина.
− Вычисляется сходство между каждой парой сущностей и используется как вершина в графе.
− Сортируются одинаковые значения.
− Запускается алгоритм PageRank до получения схожих значений.
− Отсортировываются сущности на основе их рейтинга.
− Производится выборка сущностей на основе рейтинга в качестве суммаризации текста.
MWPE — multi-word phrase extraction, в переводе это извлечение фразы из нескольких слов. По сути своей этот тот же TextRank, только извлекаются ключевые фразы вместо сущностей. Затем слова, которые были в этих ключевых фразах, учитываются в каждой сущности этого предложении отрывка из текста. Высокорейтинговые сущности были те, которые имели наибольшее количество случаев повторов в тексте. MWPE выполняет следующие действия:
− Каждое слово маркируется с пометкой части речи.
− Фильтруются слова, только те, которые являются в предложениях существительными или прилагательными.
− Добавляются слова в графы, в качестве вершин данного графа.
− Добавляется ребро в графе между словами, которые связаны по тексту между собой.
− Запускается алгоритм PageRank до получения схожих значений.
− Отсортировываются слова на основе их рейтинга.
− Производится выборка слов на основе рейтинга.
− Соединяются слова вместе в ключевые фразы, если они смежные в графе.
− Рассчитывается количество повторов ключевых фраз в каждом сущности.
− Производится выборка сущностей на основе рейтинга в качестве суммаризации текста.
LSA — latent semantic analysis, в переводе латентный семантический анализ. В LSA используется контекст предложения из отрывка и используются термины для идентификации семантической связи между предложениями. Модель не использует семантическую связь, порядок слов и морфологию. LSA принимает решение об использовании сущности на основе теории, если используется термин, то будет и использоваться сущность Тогда взаимосвязи между словами и сущностями были обнаружены в теореме о сингулярном разложении [8]. LSA выполняет следующие действия:
− Извлекаются термины из сущностей предложения.
− Создается входная матрица с подходом на терминах, например матрица TF-IDF или бинарное представление.
− Вычисляются по теореме сингулярного разложения числа для добавления в матрицу.
− Вычисляется рейтинг на основе теоремы.
− Выбираются сущности на основе рейтинга в качестве суммаризации текста.
Наглядное сравнение моделей будет показано по вычислению косинусного сходства. Для более точного измерения данных были использованы слова исключения, чтобы исключить незначительные слова из выборки.
Сравнение моделей методов извлечения сущностей сиспользованием косинусного сходства
|
Модели методов извлечения сущностей |
Косинусное сходство |
|
|
Без искл. |
С искл. |
|
|
LSA (бинарное представление) |
0.631 |
0.644 |
|
MWPE |
0.687 |
0.651 |
|
TextRank |
0.599 |
0.601 |
Как мы видим максимальную оценку показывает модель MWPE, даже несмотря на то использование слов исключений понижает точность исследования.
Литература:
- Интеллектуальная система // ru.wikipedia.org. URL: https://ru.wikipedia.org/wiki/Интеллектуальная_система (дата обращения: 19.05.2019).
- datefinder — extract dates from text // GitHub. URL: https://github.com/akoumjian/datefinder (дата обращения: 19.05.2019).
- SQuAD2.0 The Stanford Question Answering Dataset // GitHub. URL: https://rajpurkar.github.io/SQuAD-explorer/ (дата обращения: 19.05.2019).;
- Соревнование Sberbank Data Science Journey, задачи А и B. // sdsj.sberbank.ai. URL: https://sdsj.sberbank.ai/2017/ru/contest.html (дата обращения: 19.05.2019).
- Векторная модель, косинусное сходство // ru.wikipedia.org. URL: https://ru.wikipedia.org/wiki/Векторная_модель (дата обращения: 19.05.2019).
- Коэффициент Жаккара // ru.wikipedia.org. URL: https://ru.wikipedia.org/wiki/Коэффициент_Жаккара (дата обращения: 19.05.2019).
- PageRank // en.wikipedia.org. URL: https://en.wikipedia.org/wiki/PageRank (дата обращения: 19.05.2019).
- Голуб Дж., Ван Лоун Ч. Матричные вычисления. — М.: Мир, 1999. — 548 с.
