





В данной статье рассматриваются некоторые особенности написания XPath-запросов.
Ключевые слова: XPath, XML.
XPath (XML Path Language) — язык запросов к элементам XML-документа. Его применение довольно широко: от парсинга документов XML формата (в том числе web страниц html) до автоматизации тестирование сайтов и мобильных приложений.
Строка XPath описывает способ выбора нужных элементов из массива элементов, которые могут содержать вложенные элементы [1].
XPath имеет два принципиально разных способа адресации: относительный и абсолютный (рисунок 1).

Рис. 1. Способы адресации
Запросы с относительным путем разрабатываются быстрее, и как правило, выходят более компакты чем запросы с абсолютным путем, особенно это заметно при работе со сложными и большими XML-документами, где абсолютные пути могут достигать несколько сотен символов.
Рассматривая эти две стратегии написания запросов, важно понимать, каким образом, при каждом из подходов ищутся искомые элементы.
XML имеет древовидную структуру, и при использовании запроса с относительным путем, в поиске нужного паттерна придется исследовать ветки дерева, в которых искомого элемента может и не быть. Такой подход имеет риск в определенных ситуациях оказаться ресурсоемким. При использовании запросов с абсолютным путем, на каждом уровне вложенности будет отбрасываться определенное количество веток, что положительно скажется на производительности данного подхода.
Рассмотрим это на конкретном примере (рисунок 2).
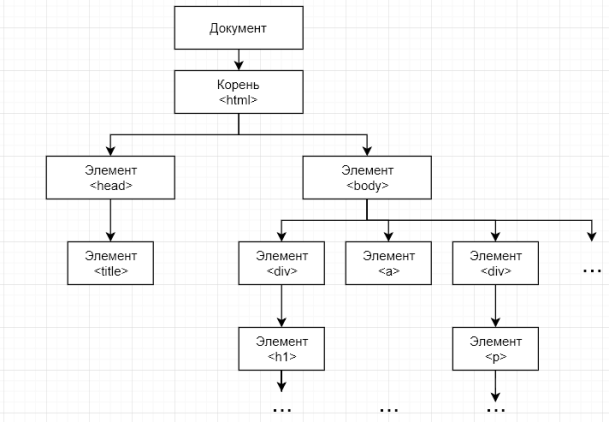
Рис. 2. Структура html документа
Предположим, у нас есть совокупность html документов с одной и той же структурой, и нам необходимо из каждого документа спарсить элемент «title» (заголовок документа). Рассмотрим два возможных запроса: //title и /html/head/title. В первом случае, элемент «title» будет искаться на всех уровнях вложенности, когда как при втором запросе, уже на втором шаге элемент «body» отбросится и в дальнейшем анализе учувствовать не будет. Очевидно, что в данной ситуации второй запрос будет более корректный, даже, если мы точно знаем, что элемент «title» в документе у нас всего один и результат запросов будет одинаковый.
Отметим, что запросы могут быть и следующего вида: /html/body//p. В этом случае, элемент «p» будет искаться на всех уровнях вложенности элемента «body», а «head» при этом рассматриваться не будет. Важно понимать, когда целесообразно использовать один подход, а когда другой.
При использовании «/» (так называемая ось child::), можно достичь максимальной производительности и экономии ресурсов, кроме того иногда точный путь даже с точки зрения логики выглядит более верным (как в примере выше, так как «title» является постоянным вложенным элементом «head»). Если необходимо единожды спарсить информацию из неизменяемых документов, почти всегда написание запросов с осями child:: («/») имеет смысл, за исключением тех случаев, когда подобные запросы оказываются очень сложные и длинные (рисунок 3), в этом случае необходимо делать выбор, что важнее: удобство разработки или производительность, скорость разработки или скорость работы программы.
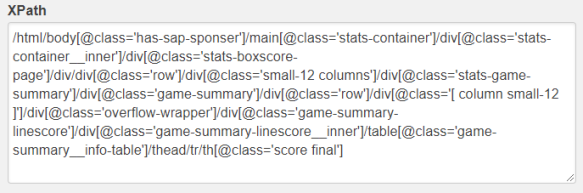
Рис. 3. Запрос XPath
Однако не всегда, имеет смысл писать запросы с большим количеством осей child:: («/»), даже, если при этом будет достигаться максимальная производительность, а сам запрос будет выглядеть вполне читаемо.
Часто с помощью XPath приходится обрабатывать динамические документы, которые с течением времени могут измениться, вследствие чего абсолютный путь искомых элементов поменяется, и каждая ось child:: может являться потенциальным узким местом в запросе.
Поэтому при работе с web страницами (web scraping, QA automation website), очень часто рационально использовать «//» (ось descendant-or-self::), в этом случае запрос будет более устойчив и при незначительном изменении структуры страницы, результат выполнения запроса не изменится.
Таким образом, каждая из осей имеет свое предназначение, а стратегия подхода написания XPath запросов должна зависеть от конкретной ситуации, а не от стиля разработчика.
Литература:
1. Википедия: XPath [Электронный ресурс] — URL: https://ru.wikipedia.org/wiki/XPath (дата обращения: 26.01.2019).
