The expert system is a software product, and its purpose is the automation of human activity. However, the fundamental difference between ES from other programs is that it does not play the role of an “assistant” performing for a person part of the work, and in the role of «competent partner» — an expert consultant in a particular subject area.
ES do not have intuition and general knowledge of the world, their course and method solving the problem can not go beyond the knowledge that they laid down. ES will also be powerless in solving problems in changing conditions, for example, when changing the solution methodology or the emergence of new equipment [1].
The permanent knowledge of an expert system is stored in a knowledge base. It contains the information that the expert system uses to make decisions. This information presents expertise gained from top experts in the field. This knowledge comes in the form of facts and rules. Facts are minimal elements of the knowledge which must be identified before anything else. Rules consist of ̳if....then‘ statements, where a given set of conditions will lead to a specified set of results. The inference engine is a computer program that controls the execution, and uses rules to respond to a query and determine whether a suitable match can be found in the fact list, through backward or forward chaining. It determines which rules will be applied to a given question and in what order by using information in the knowledge base [2].
Thus, the purpose of expert systems is to advise on specific issues when making decisions by a person. That is, the expert systems are used to enhance and expand the professional capabilities of their users.
Processing parts of application of expert systems are as follows:
– Interpretation of data. This is one of the traditional tasks for expert systems. Interpretation refers to the definition of the meaning of the data, the results of which must be consistent and correct. Multi-variable data analysis is usually provided
– Diagnostics. Diagnosis is the detection of a fault in a system. The fault is a deviation from the norm. This interpretation allows, from a single theoretical point of view, to consider and equipment malfunction in technical systems, and diseases of living organisms, and all sorts of natural anomalies. An important specificity is the need to understand the functional structure («anatomy») of the diagnostic system.
– Monitoring. The main task of monitoring is continuous data interpretation in real time and signaling that certain parameters are out of acceptable limits. The main problems are the “skipping” of the alarming situation and the inverse problem of the “false” operation. The complexity of these problems lies in the blurring of the symptoms of anxiety situations and the need to take into account the temporal context.
– Design. Design consists in the preparation of specifications for the creation of «objects» with predetermined properties. The specification refers to the entire set of necessary documents drawing, explanatory note, etc. The main problems here are the obtaining of a clear structural description of knowledge about the object and the problem of the “trace”. For the organization of effective design and, to an even greater extent, redesign, it is necessary to form not only the design decisions themselves, but also the motives for their adoption. Thus, in the design tasks, two main processes are closely connected, which are carried out within the framework of the corresponding ES: the solution derivation process and the explanation process.
– Prediction. Predictive systems logically derive probable consequences from given situations. In the predictive system, a parametric dynamic model is usually used, in which the values of the parameters are “tailored” to a given situation. Investigations derived from this model form the basis for predictions with probabilistic estimates.
– Planning. Under the planning refers to the finding of action plans related to the objects that can perform certain functions. In such ES models of behavior of real objects are used in order to logically derive the consequences of the planned activity.
– Training. Learning systems diagnose errors in the study of a discipline using a computer and suggest the right solutions. They accumulate knowledge about a hypothetical “student” and its characteristic mistakes, then, in their work, they are able to diagnose weaknesses in the knowledge of students and find appropriate means to eliminate them. In addition, they are able to plan the training of the student, depending on his success.
All ES have similar architecture. The basis of this architecture is the division of knowledge embedded in the system and the algorithms for their processing. For example, the program solving quadratic equation, undoubtedly, uses knowledge of how this type of equations should be solved. But this knowledge is “sewn up” in the text of the program and it cannot be not read, not changed, if the source code of the program is not available. Programs of this class are very convenient for those who solve quadratic equations in whole days. However, if the user wants to solve a different type of equation, he cannot do without a programmer who can write a new program to him. Now, suppose the task is set a little differently: the program must read the type of equation and the method of solving it from a text file when starting, and the user must be able to independently introduce new ways of solving equations, for example, to compare their efficiency, accuracy, etc.
The format of this file should be equally “understandable” to both the computer and the user. This way of organizing a program will allow changing its capabilities without the help of a programmer. Even if the user solves only one type of equations, the new approach is preferable to the former, if only because it is possible to understand the principle of solving equations, you can simply examine the input text file. This example, despite its simplicity and atypical nature of the subject area for applying ES technology (for solving mathematical equations, usually use specialized software packages, rather than expert systems), illustrates well the feature of ES architecture — the presence in its structure of the knowledge base that the user can view directly or using a special editor. The knowledge base can also be edited, which allows you to change the work of an ES without reprogramming it. [3]
If we analysis the above structure all part has its own functions. And every part does its functions step by step. For example, necessary data is input to the “Output machine” by the “User interface” and the machine searches this information from the DB. As soon as the information is found the machine sends it to the “User interface” by the “Generator”.
In this case the role of the “Editor data base” consists of editing the data. And editor only can contact and use the “DB”.
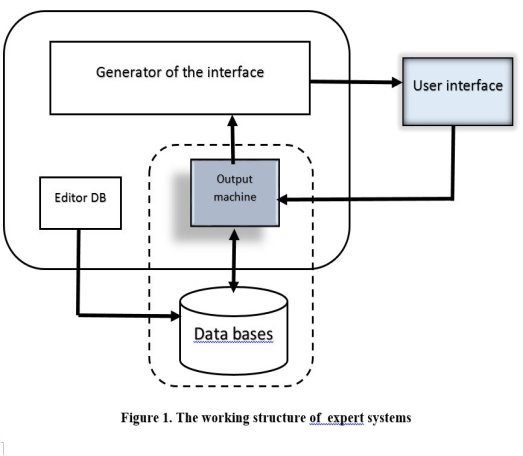
- DB — the knowledge base is the most valuable component of the ES kernel, a set of knowledge about the subject area and how to solve problems, written in a form that is understandable to non-specialists in programming: expert, user, etc. Usually knowledge in BR is recorded in a form close to natural language. The knowledge entry form is called the knowledge representation language (KRL). Different systems can be used in different systems. In parallel with this “human” representation, the BZ can exist in the internal “machine” representation. Conversion between different forms of representation of the BR must be carried out automatically, since editing the BR does not imply the participation of the programmer-developer.
- OM — output machine — a unit that simulates the course of the expert’s reasoning on the basis of knowledge embodied in the BR. The output machine is a constant part of the ES. However, the majority of real ES have built-in tools for controlling the course of logical inference using the so-called meta-rules recorded in the DB.
- E — Knowledge Base Editor — designed for ES developers. With this editor, new knowledge is added to the knowledge base or existing ones are edited.
- User interface — a unit designed for interaction of the ES with the user, through which the system requests the data necessary for its operation, and outputs the result. The system may have a “hard” interface oriented to a specific input and output method of information, or it may include design tools for specialized interfaces for more efficient user interaction.
References:
1. Talzina N. F. Upravlenie prosessom usvoniya znaniy. — M.:Izdatelstvo Moskovskogo universiteta, 1975.
2. Aderonke A. K. An Integrated Knowledge Base System: Information Technology and Computer Science, 2013, 01, 74–84.
3. Gaevskaya E. G. Texnologii setevogo distansionnogo obucheniya: Uchebnoe posobiye. — SBb.:F- t.filologii iskusstv SBbGU, 2007.

