Данная статья посвящена методу распознавания сарказма в тексте с целью повысить точность определения тональности. В качестве предметной области для эксперимента была выбрана задача определения уровня тональности текстов, содержащих описание внешнего вида человека. На первом этапе определялись упоминания личностей и элементы, содержащие описания внешнего вида человека, из текста при помощи метода латентно-семантического анализа. Фреймовая модель представления знаний была выбрана в качестве информационной модели внешнего вида человека. На следующем этапе вычислялось отношение к личности в тексте с использованием размеченного вручную словаря тональности. В качестве критерия оценки эффективности корректного определения уровня сарказма в тексте использовалась F-мера. В конце статьи описаны результаты проведенного эксперимента.
Ключевые слова: семантический анализ, распознавание личности в тексте, ЛСА, анализ тональности.
- Введение
Анализ тональности текста относится к задачам информационного поиска. Важность применения эффективного решения для данной проблемы с течением времени только увеличивается, так как объем информации, который необходимо обработать системой семантического анализа текста непрерывно растет. На текущий момент существуют довольно эффективные методы анализа тональности текста. Но также есть и ряд направлений, решение которых поможет достичь более высокой точности распознавания. Одним из таких направлений является определение сарказма. Сарказм можно определить как неявный подход к выражению противоречивых эмоций. Однако даже человеку не всегда удается достоверно определить является ли данная фраза сарказмом.
Задача автоматизации определения сарказма сама по себе имеет небольшое практическое значение. Как правило, данная задача применяется в контексте семантического анализа текста определенной предметной области. Одними из наиболее востребованных направлений являются:
‒ анализ тональности пользовательских обзоров
‒ анализ комментариев, размещенных на социальных медиа ресурсах [1].
Проблема распознавания саркастических предложений в тексте на естественном языке была рассмотрена в контексте поиска элементов внешнего вида человека и определения класса тональности. Данная именованная сущность была выбрана не случайно, так как распознавание личности в тексте с высокой точностью является довольно сложной задачей из-за большого числа возможностей кореференций через местоимения в третьем лице.
Целью данной работы являлось исследование современных методов определения отношения автора к лицу, описываемому в тексте на естественном языке, путем применения анализа тональности. Наиболее очевидной областью применения разработки, рассмотренной в данной статье, является анализ комментариев к фотографиям в социальных сетях. Используя методы машинного обучения, можно построить модель, способную распознать положительное или отрицательное отношение к внешнему виду человека, изображенного на фотографии. Основным вкладом автора статьи является адаптация существующих методов оценки тональности к области распознавания внешнего вида человека в тексте на естественном языке [2].
- Базовая модель информационного поиска
Прежде всего, требовалось разработать информационную модель внешнего вида человека. Эта модель должна отвечать следующим требованиям:
‒ расширяемость
‒ наглядность
‒ полнота описания.
Под перечисленные критерии отлично подходит модель знаний в виде фреймов. На рисунке 1 показана окончательная модель внешнего вида человека с использованием нотации FRL (frame representation language). Основные компоненты, на которых можно составить полное описание внешнего вида человека, являются слотами фрейма. На рисунке «M» — это набор допустимых значений для элементов описания внешнего вида каждого слота. Особенностью нотации FRL является то, что разрешено применять к ним специальные процедуры-демоны. Одна из таких процедур — определение уровня тональности с последующим распознаванием сарказма. Стоит отметить, что каждый непустой слот должен соответствовать предложениям, из которых были извлечены факты для фрейма. Это необходимо для дальнейшего определения наличия сарказма в тексте [3].
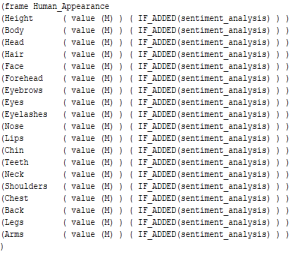
Рис. 1. Модель внешнего вида человека в нотации FRL
Чтобы заполнить фрейм, использовался метод латентно-семантического анализа (сокращенно LSA), так как он хорошо зарекомендовал себя в области машинного обучения. Методы, которые не используют предварительно размеченную обучающую выборку, показывают меньшую эффективность. Метод ЛСА можно охарактеризовать как установление взаимосвязи между векторами признаков анализируемых документов со словами, которые являются ключевыми в заданной предметной области. Таким образом, для использования метода семантического анализа текста на естественном языке слоты фрейма следует использовать в качестве ключей поиска [3].
Алгоритм латентно-семантического анализа:
‒ создать список всех ключевых слов, по которым будет производиться поиск в тексте
‒ создать частотную матрицу A, ячейки которой состоят из вхождения ключевых слов доменной области в анализируемые документы
‒ применить метод TF-IDF над частотной матрицей для обеспечения более релевантных результатов [4]
‒ применение сингулярного разложения матрицы: алгоритм делит преобразованную частотную матрицу А на три составные матрицы U, Vt и S в соответствии с формулой 1
![]() . (1)
. (1)
‒ матрица U содержит координаты ключевых слов и Vt — координаты документов.
Сингулярная декомпозиция матрицы позволяет избавиться от ненужного шума, что значительно повышает эффективность метода. Экспериментально можно выбрать количество строк и столбцов, которые можно отбросить для последующего анализа. Теперь можно получить ближайшие документы, которые имеют то же семантическое значение, что и указанное ключевое слово, и затем заполнить слоты фреймов.
- Анализ тональности на основе словаря
Все подходы к определению класса тональности делятся на три основные группы:
‒ создание словаря тональности
‒ использование различных классификаторов
‒ использование составленных контекстных правил.
Подход на основе контекстных правил показывает наиболее точные результаты, но требует колоссальных работ по лингвистике. Основным недостатком этого подхода является то, что чрезвычайно сложно составить универсальные правила, подходящие для всех доменных областей. Для достижения наиболее эффективной оценки тональности правила составляются для конкретной области применения.
В этом эксперименте был применен подход, основанный на словаре валентности, поскольку он показывает довольно высокий процент правильного распознавания. Задача значительно упрощается, если есть источник для составления словаря валентностей, принадлежащих изучаемой области. Такой словарь был составлен на основе корпуса русского языка OpenCorpora. Из этого словаря были выбраны все фразы, отмеченные граммемой «Qual». Кроме того, были отфильтрованы только те формы слов, которые могут быть использованы для описания внешнего вида человека. Чтобы упростить задачу анализа тональности, было решено, что валентность будет соответствовать определенному уровню тональности. В таблице 1 показан пример такого словаря.
Таблица 1
Пример составления словаря валентностей
|
Ключевое слово |
Валентность |
|
Дружелюбный |
2 |
|
Недружественный |
-2 |
|
Застенчивый |
0 |
Для исследования были составлены основные пять классов тональности:
‒ отрицательный
‒ сильно отрицательный
‒ положительный
‒ сильно положительный
‒ нейтральный.
Для определения тональности использовался метод наивного Байеса. Этот метод зарекомендовал себя в области машинного обучения. Наивный байесовский алгоритм — это алгоритм классификации, основанный на теореме Байеса с условием независимости признаков. Классификатор предполагает, что наличие какой-либо особенности в классе не связано с наличием какого-либо другого атрибута. Пусть P (d | c) — вероятность нахождения документа во всех документах данного класса. Основой наивного байесовского классификатора является соответствующая теорема (2). В формуле (2) P (c) — вероятность того, что некоторый документ можно найти среди всех наборов данных, а P (d) — вероятность того, что документ встречается во всем корпусе.
![]() (2)
(2)
Таким образом, метод наивного Байеса основан на проблеме нахождения максимальной вероятности принадлежности документа к определенному классу. Исходя из этого, уровень тональности для каждого ключевого элемента внешнего вида человека может быть определен в (3) [5].
![]() (3)
(3)
Классификация с использованием метода Байеса работает довольно быстро и требует сравнительного небольшого объема обучающей выборки. Кроме того, он лучше подходит для классификации по категориям (анализ тональности с определенными классами относится к таким случаям). Однако если в наборе данных есть какое-либо значение категории, которое не было найдено в обучающих образцах, тогда модель определит нулевую вероятность. Класс настроений для каждого ключевого элемента внешнего вида человека может быть определен в (3), где P (w | c) — вероятность вхождения определенного термина в документе.
- Подход к определению сарказма в предложении
Проблема определения сарказма в предложении требует обучения другого классификатора. Для решения этой проблемы используется метод k-ближайших соседей [6]. Чтобы классифицировать каждый из объектов тестового образца, нужно выполнить следующие шаги:
‒ рассчитать расстояние до каждого из объектов обучающей выборки
‒ выбрать k образцов из обучающих данных, расстояние до которых минимально
‒ класс классифицируемого объекта — это класс, наиболее часто встречающийся среди k ближайших соседей.
Был составлен следующий набор параметров для вектора особенностей:
‒ наличие форм слов, которые являются специфическими для сарказма
‒ наличие кавычек в тексте (если есть кавычки, то скорее всего текст содержит определенную степень иронии)
‒ высокая частота пунктуации
‒ наличие в тексте слов, которые чаще всего используются в сочетании с сарказмом для конкретного языка, которые взяты из учебных образцов [7].
Для этого случая вес задается как функция расстояния до ближайших соседей. В формуле (4) d (x, x (i)) — функция, определяющая расстояние между элементами в векторном пространстве. Уравнение (5) определяет, содержит ли анализируемый текст сарказм, где Zi — сумма весов для всех доступных классов. Если это так, то уровень тональности должен быть изменен на противоположное значение.
Эмпирически было выявлено, что классификатор дает лучшую эффективность с точки зрения точности, если анализирует число ближайших соседей K, равное количеству классов тональности.
Чтобы получить более правдоподобные результаты, нужно отфильтровать наиболее часто используемые слова в модели. Этот шаг устраняет ненужный шум, который может повлиять на окончательный результат исследования. Кроме того, перед использованием метода K ближайших соседей следует учитывать объем агрегированной информации о тональности. В этом исследовании представлены результаты для униграмм и триграмм [8].
![]() (4)
(4)
![]() (5)
(5)
- Проведение эксперимента и анализ результатов
Чтобы определить повыситься ли точность распознавания тональности, используя метод определения сарказма, требуется числовая метрика. Для большинства современных алгоритмов, основанных на машинном обучении, используются метрики точности и полноты поиска. Точность поиска определяет долю документов, которые действительно принадлежат определенной тональности по всем документам этого класса. Полнота поиска определяет отношение найденных классификатором документов, принадлежащих этому классу, ко всем документам в выборке. Поскольку в реальной практике машинного обучения максимальная точность и полнота поиска недостижимы одновременно, анализ результатов с использованием F-меры будет наиболее приемлемым. F-меру рассчитывают следующим образом (6):
![]() (6)
(6)
Был составлен учебный набор из 500 образцов: 150 из них были отмечены как «содержащие сарказм», а 350 отмечены как «не содержащие сарказма». Это соотношение между классами выбиралось не случайным образом, так как вероятность оценки класса тональности текста как положительного или отрицательного намного выше, чем саркастического. Эксперимент проводился на образце из 100 текстов, которые содержат описание для разных фотографий длиной не более 200 слов и содержат только информацию о внешности человека.
Как видно из полученных результатов (таблица 2), метод распознавания сарказма в тексте снижает точность из-за относительно большого количества ложных срабатываний. Можно сделать вывод, что лексических признаков и знаков препинания недостаточно для обучения классификатора на достаточном уровне. Чаще всего предложения имеют сложную структуру, которая не может рассматриваться как «мешок слов» и требует использования контекстных синтаксических правил [9].
Таблица 2
Результаты эксперимента
|
|
Полнота |
Точность |
F |
|
Униграммы, без сарказма |
0.80 |
0.82 |
0.810 |
|
Триграмы, без сарказма |
0.85 |
0.84 |
0.844 |
|
Униграммы, сарказм |
0.86 |
0.68 |
0.760 |
|
Триграммы, сарказм |
0.87 |
0.77 |
0.820 |
- Заключение
В результате эксперимента можно сделать вывод, что разрешение задачи распознавания сарказма в тексте, содержащем описание внешнего вида человека, не может быть эффективно разрешено только с использованием методов машинного обучения с учителем. В качестве дополнительного исследования требуется разработка контекстных правил, основанных на синтаксической структуре текста. На текущем этапе оценка F-меры показала, что метод немного снижает эффективность из-за относительно большого количества ложных срабатываний.
Литература:
1. A. Ritter, S. Clark, Mausam and O. Etzioni, “Named entity recognition in tweets: an experimental study,” Proceeding of the conference on empirical methods in natural language processing, Association for Computational Linguistics, pp. 1524–1534, July 2011.
2. A. Dmitriev, A. Zaboleeva-Zotova, Y. Orlova and V. Rozaliev, “Automatic identification of time and space categories in the natural language text,” Proceedings of the IADIS Internation Conference, pp. 23–25, October 2013.
3. A. Dolbin, V. Rozaliev, Y. Orlova, “Recognition of a person named entity from the text written in a natural language,” Journal of Physics: Conference Series, vol. 803, 5 p., 2017.
4. B. Gebre, M Zampieri, P. Wittenburg and T. Heskes, “Improving native language identification with tf-idf weighting,” 8th NAACL Workshop on Innovative Use of NLP for Building Educational Applications, pp. 216–223, 2013.
5. H. Shimodaira, “Text classification using naïve bayes,” Learning and Data Note, vol. 7, pp. 1–9, 2014.
6. D. Davidov, O. Tsur, A. Rappoport, “Semi-supervised recognition of sarcastic sentences in Twitter and Amazon,” CoNLL 10 Proceedings of the Fourteenth Conference on Computational Natural Language Learning, pp. 107–116, July 2010.
7. P. Carvalho, L. Sarmento, M. J. Silva, E. Oliveira, “Clues for detectingirony in user-generated contents: oh...!! it's so easy” Proceedings of the 1st international CIKM workshop on Topic-sentiment analysis for mass opinion, pp. 53–56, November 2009.
8. A. Reyes, P. Rosso, “Mining subjective knowledge from customer reviews: a specific case of irony detection,” Proceedings of the 2nd workshop on computational approaches to subjectivity and sentiment analysis, pp. 118–124, June 2011.
9. R. Gonzalez-Ibanez, S. Muresan, N. Wacholder, “Identifying sarcasm in Twitter: a closer look,” Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, vol. 2, pp. 581–586, June 2011.

