





The given paper estimates a number of Twitter users posting their feedbacks on main daily news. In order to acquire statistic data, a unified algorithm developed specially for evaluating a level of interest, which Twitter communicants show towards central news topics, was applied in the context of this study. The experiment has involved a database comprising archive news texts from the RIA Novosti news website and text messages written by Twitter users obtained through Twitter API (which is a special interface that allows utilizing data from the social network).
Key words: statistic data, Twitter, news analytics, mass media, news, daily incidents
Communication is suggested one of the core human needs. As for virtual communication, there are numerous Internet resources, including Twitter, where registered users are provided with a technical possibility to interact, share news and emotions, and express their points of view concerning any matter.
Therefore, Twitter serves as a reliable resource of news topics that draw communicants' interest. Through this social networking website it can be estimated how exactly a certain piece of news has influenced the general public, and which incident has or has not triggered users' response. In this regard, examining feedbacks of communicants on media reports constitutes the main objective of the given scientific paper.
In addition, studies in this field are carried out regularly (for example, by Lenta.ru website or BrandAnalytics company). A core principle of conducted studies is estimating popularity of each mass media resource by counting a number of links included in communicants' messages. This paper aims to identifying correlation between Twitter user messages and relevant subjects highlighted by the media.
Search for news topics in user messages
In order to reach the assigned objective, the following steps are to be accomplished:
1) finding a way of extracting key words from relevant topics of each day;
2) developing an algorithm that would generate Twitter communicant's queries incorporating selected key words.
RIA Novosti website, comprising a substantive base of news topics, was utilized as a news resource in the described experiment. Evaluating importance of mentioned key words was carried out with the help of a tf*idf [TF-IDF] numeric statistic that is intended to reflect how important a word is to a reference document included in a certain group of documents.
TF is a rate of how frequently an analyzed word occurs to a total number of words in a document. In the context of the paper, its value has been calculated by comparing occurrence of specific words with an overall word length of an examined text. Such an approach has lead to greater accuracy in evaluating importance of each key word. IDF is an inverse document frequency diminishes the weight of terms that occur very frequently in the document set. The TF-IDF numerical statistic is the product of two mentioned statistics.
In the course of the experiment, all the daily news topics were downloaded, and stop words eliminated. Then, three key terms with the highest values of tf*idf were selected, while compiling a list of topics in which the chosen indicators had appeared. Resulting lists were also subject to further analysis, so that three new key words with the highest tf*idf could be identified.
If the second group of identifiers matched the first one, it was considered that only one significant incident described in several ways had happened during the day. Otherwise, a new topic had been created. Such a set of words then served as a search query when working with the Twitter database through Twitter Api. In addition, requests were made at equal time intervals. Only those messages were selected for further examination, which had been obtained at the very first step of the experiment. Unique messages then compiled a dataset intended for processing gathered information.
A level of interest in news highlighted by the media was estimated by calculating a number of unique messages acquired from queries in the context of a certain topic. Final results of the described experiment are enough to make credible conclusions. It should also be noted that those text messages posted though the media's Twitter accounts were not included in examined datasets, as they do not reflect credible responses from communicants.
Experimental part
The testing was conducted in two stages. The first period lasted for 38 days (began on 04.11.2014 and ended on 20.12.2014). During that time, the applied algorithm found 124268 messages, 56122 of which were published by the media, and the other 68146 — by Twitter communicants themselves. Acquired information is presented as a diagram (Figure 1):
1) red bar graph shows the number of messages published by news agencies;
2) blue bar graph shows the number of messages posted by Internet users;
3) line chart represents the number of users, messages of which had been included into a daily statistical sampling.
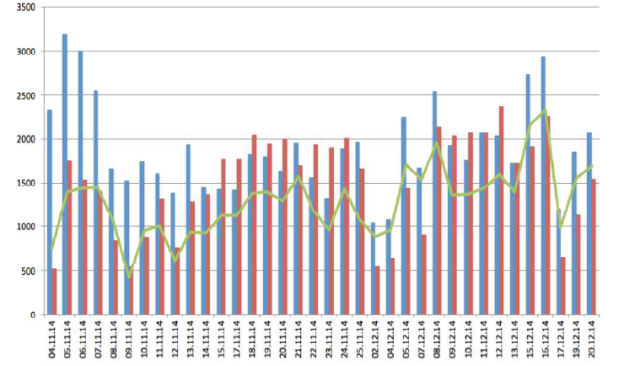
Fig. 1. Statistical data for the period 04.11.2014–20.12.2014
Figure 1 demonstrates sharp fluctuations. For example, on November 5th, 2014, daily news concentrated around Ukraine and Russia. That day, number of posted users’ messages increased up to 3200, which was roughly twice as much as publications of news agencies. However, the period from 06.11.2014 to 15.11.2014 shows certain reduction of Twitter communicants' interest, despite the fact that the core topic remained the same, which derived from a total number of messages.
Since 08.12.2014, increase in the currency exchange rate had been primarily discussed. By December 16th, 2014, a total number of users responded to that news had risen to 2300.
Next we shall consider the second time interval that lasted from 21.12.2014 to 18.02.2015. Over that period, the applied algorithm indicated 148175 messages, 48890 and 99285 of which were published by the media and by Twitter communicants accordingly. At that stage, a number of users' messages was almost twice the media publications. Acquired data is represented by Figure 2.
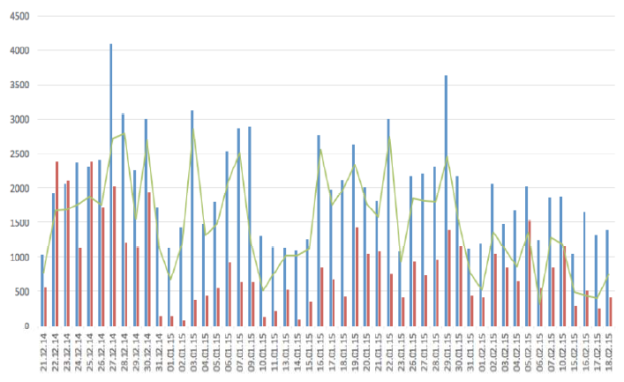
Fig. 2. Statistical data for the period 21.12.2014–18.02.2015
The diagram above reflects obvious rises in a number of messages. The period from 21.12.2014 to 31.12.2014 shows discussions concerning an increase in the cost of foreign currency. According to the reviewed dynamics, it may be concluded that the mentioned topic had rapidly grown in popularity, as on December 27th the number of tweets rose up to 4000, which was twice as much as the media publications. Consequently, we may assume that the general public had indeed been worried about that matter. Later on, the tendency decreased, which was most likely caused by the New Year celebrations.
The period from 03.01.2015 to 29.01.2015 showed that several topics were popular for discussion on the examined social network, namely, events in Ukraine and ruble depreciation, which gained the most attention according to the number of users’ messages. However, since 10.01.2015, user activity had declined. As for January 29th, another spike can be observed; the number of users’ messages reached 3600, after which overall popularity of the analyzed topics had gradually decreased.
It should also be noted that the given statistical sampling cannot be called large, as when compared with a total number of messages published on Twitter, figures obtained by the applied algorithm are negligible. Moreover, Twitter Api features some restrictions for search queries. Consequently, not all the possible tweets were analyzed in the course of the experiment, which may affect the findings.
Conclusion
As a result of the carried study, it can be concluded that the applied algorithm allows selecting some statistic data for further compiling of Twitter users activity patterns. In accordance with resulting diagrams it can be presumed, which news exactly draws the most user interest. However, the experiment is complicated by the fact that the media tend to duplicate news in their Twitter messages, while users opt for sharing links on websites. Such circumstances do not allow tracing response of concerned individuals, which makes it difficult to obtain their points of view.
References:
- TF-IDF — https://ru.wikipedia.org/wiki/TF-IDF
- Twitter Api — https://developer.twitter.com/en/docs.html
