





В данной работе решается задача подготовки исходных данных (обучающей выборки) для использования в обучении искусственной нейронной сети, распознающей образы в видео. Анализируется тенденции популярности тем «Большие данные» и «Глубокое обучение», а также методы обработки и использования цифровой информации. Описаны основные характеристики видео и принципы подготовки исходных данных из видео материалов. Описана работа и анализ работы созданной прикладной программы, использующей набор библиотек ffmpeg, для декодирования видео в отдельные кадры.
1 BigData
Сегодня наблюдается большой интерес к теме «Big Data» [1]. Это обусловлено переходом к массовому использованию цифровой техники для хранения, обработки, созданию и анализу информации. Согласно статистике сервиса Google Trends, популярность темы «Большие данные» в поисковой системе Google начинает расти с 2011 года и не прекращает по текущее время (рис. 1).
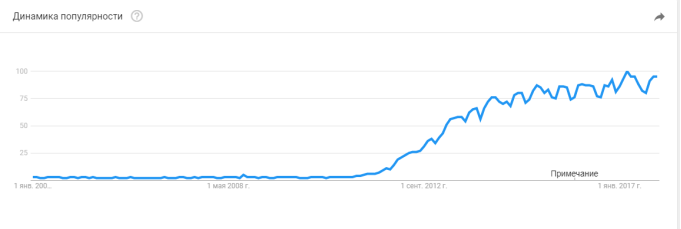
Рис. 1. Динамика популярности темы «Большие данные» от Google с 2004 года
Первое появление этого термина датируется 2008 годом в выпуске журнала Nature, редактором которого является Клиффорд Линч [2]. В настоящее время в основном используется определение «Больших данных», как совокупность методов, средств и технологий для анализа и структурирования информации [3].
Для характеристики «Больших данных» ввели упрощенные критерии, которые назвали «три V» [4]:
1) Объём (volume). Это означает, что большие данные появляются при наличие большого объема, который является проблемным для средств обработки.
2) Скорость (velocity). Это означает, что большие данные появляются при требовании быстрой обработки или высокой скорости обработки, которую не могут обеспечить средства обработки.
3) Многообразие (variety). Это означает, что большие данные появляются при высоком разнообразии, которую не могут исследовать методы анализа и обработать средства обработки.
С созданием интернета и цифровых баз данных многократно увеличились объемы хранимой цифровой информации, а также открылись почти неограниченные возможности доступа к огромным объемам информации. По большей части приходится работать с неструктурированной и разнообразной информацией.
Согласно отчету «McKinsey Global Institute» за 2011 год [5] основными методами и техниками анализа, для работы с большими данными являются:
- Классификация — методы категоризации новых данных на основе принципов, ранее применённых к уже наличествующим данным.
- Краудсорсинг — категоризация и обогащение данных силами широкого, неопределённого круга лиц, привлечённых на основании публичной оферты, без вступления в трудовые отношения.
- Смешение и интеграция данных — набор техник, позволяющих интегрировать разнородные данные из разнообразных источников для возможности глубинного анализа, в качестве примеров таких техник, составляющих этот класс методов, приводятся цифровая обработка сигналов и обработка естественного языка.
- Машинное обучение — использование моделей, построенных на базе статистического анализа или машинного обучения для получения комплексных прогнозов на основе базовых моделей.
- Статистический анализ.
Как средство работы с «Большими данными» наиболее популярным является машинное обучение. Одним из видов машинного обучения являются искусственные нейронные сети (ИНС).
2 Большие вычислительные мощности и нейросети
За точку отсчета начала информационной эры обычно принимают создание первых электронно-вычислительных машин в двадцатом веке, таких как Z3, ENIAC, МЭСМ. С тех пор прогресс шагнул далеко вперед и на текущий момент мы имеем информационные комплексы, мощностью в миллиарды раз превосходящие самые первым ЭВМ.
Первые попытки работы с искусственными нейронными сетями впервые были предприняты Уорреном Мак-Каллоком и Уолтером Питтсом в 1943 году и описаны в статье «Логическое исчисление идей, относящихся к нервной активности» [6]. В то время это вызвало большой интерес ученых, но из-за малых вычислительных мощностей для работы с ИНС большинство исследований прекратилось.
Увеличение вычислительных мощностей и накопление опыта работы с ними позволили вновь вернуть интерес к изучению методов глубокого обучения, которые являются набором алгоритмов для работы с ИНС. Возрастающий интерес к теме «Глубокое обучение» наблюдается в статистике сервиса Google Trends (рис. 2). Вновь начавшиеся исследования позволили создать алгоритмы для работы с нейросетями, которые позволяют решать ряд определенных задач, таких как классификация, кластеризация, распознавание образов, анализ и др.
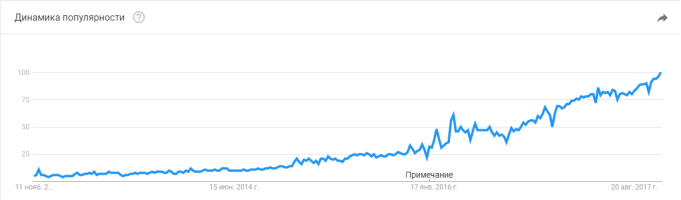
Рис. 2. Динамика популярности темы «Глубокое обучение» от Google с 2004 года
3 Подготовка исходных данных для машинного обучения
Для получения решения определенной задачи искусственной нейронной сетью ее необходимо правильно обучить [7]. Поиск выборки для обучения — один из важнейших этапов решения задачи. Для уменьшения ошибки решения при определении обучающей выборки стоит обращать внимания на такие факторы, как:
1) Репрезентативность (разнообразие) — данные должны представлять наиболее полную информацию и различные ситуации при обучении.
2) Нормализация — данные должны быть представлены в понятном для нейросети виде. Обычно это числовые значения, преобразованные с помощью различных методов, а также функций активации.
3) Регуляризация — проверка весов на переобучение, когда вес имеет значение больше сотни или тысячи.
4) Противоречивость — выборка не должна содержать противоречивые данные, так как нейронная сеть однозначно сопоставляет входные значения.
Основным фактором можно считать нормализацию, так как входные данные могут быть абсолютно любого типа и размера, которые нужно привести к единому виду.
4 Свойства видео
Для решения задачи распознавания образов на видео необходимо подготовить обучающую выборку. В данном случае выборкой являются кадры из видео. Для получения кадров необходимо декодировать его с помощью кодеков, в основном основывающихся на международном стандарте сжатия цифрового аудио и видео MPEG-4.
На рис. 3 изображены основные свойства видео. Особо важными для решения задачи являются характеристики видео и методы сжатия.
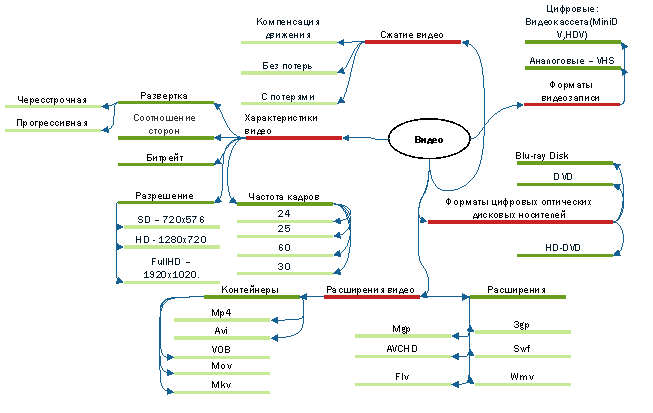 Рис. 3. Основные свойства видео
Рис. 3. Основные свойства видео
Видеоинформация является одной из значимых областей в сфере «Больших данных». На текущий момент для видео, как в интернете, так и в компаниях (камеры слежения и т. п.), особо остро стоит проблема объема. Объем в основном складывается из суммы объемов всех кадров и зависит от их количества в видео (частота кадров). Для решения этой проблемы используются специальные методы сжатия:
1) Без потерь — сжатие изображений может осуществляться без потерь качества лишь в том случае, если в процессе сжатия не было потерь данных. В результате полученное после декомпрессии изображение будет в точности (побитно) совпадать с оригиналом.
2) С потерями — Сжатие может происходить с потерями качества, если в процессе сжатия информация была потеряна. Однако с точки зрения человеческого восприятия сжатием с потерями следует считать лишь такое сжатие, при котором возможно на глаз отличить результат сжатия от оригинала. Таким образом, несмотря на то что два изображения — оригинал и результат сжатия с использованием того или иного компрессора — побитно могут не совпадать, тем не менее разница между ними может быть совсем незаметной.
Оба метода включают в себя разнообразные алгоритмы сжатия изображений, аудио и видео, например, популярный метод сжатия видео — компенсация движений.
5 Работа с кодеками
Кодеки — набор средств для кодирования и декодирования данных (аудио, видео, титры). Самые популярные кодеки и их описание приведены в таблице 1.
Таблица 1
Самые популярные кодеки
|
H.264 |
DivX |
Xvid |
|
Второе название — MPEG-4 Part 10. Сжимает с сохранением высокого качества. Необходима лицензия для использования. |
Создан на основе MPEG-4 ASP. С 7 версии соответствует Н.264, с 10 — Н.265. Необходима лицензия для использования. |
Создан на основе MPEG-4 ASP. Xvid является основным конкурентом кодека DivX. Открытый и сходный код и бесплатное распространение. Нелегален в некоторых странах так как использует некоторые методы MPEG-4. |
Кодек использует различные алгоритмы для сжатия видео. Как рассказывалось выше, видео состоит из кадров. Каждый кодируемый кадр видеопотока представляет собой массив пикселей (ширина и высота кадра) с разными атрибутами (цвет, яркость). Обычно выбираются массивы пикселей меньших размеров (4х4, 8х8, 16х16) и сравниваются кодеком на схожесть. Вместо того, чтобы запоминать каждый массив пикселей постоянно для каждого кадра, используется ключевой массив и счетчик его повторений до момента изменения атрибутов. Для регулирования степени сжатия используется «коэффициент схожести». При построении видеоряда, кодеком используются различные типы кадров: I — ключевые кадры и P — разностные кадры. Ключевыми кадрами являются минимально сжатые, а разностные кадры –полученные определенными продвинутыми алгоритмами сжатия, такими как компенсация движения, и содержат как независимо сжатые массивы пикселей, так и массивы с ссылкой на другой кадр.
С точки зрения программирования кодек — библиотека. Одной из популярных библиотек для декодирования видео является FFmpeg — набор свободных библиотек с открытым исходным кодом, которые позволяют записывать, конвертировать и передавать цифровые аудиозаписи и видеозаписи в различных форматах. Содержит библиотеки: с утилитами для работы с командной строкой; с медиаплеером; со всеми алгоритмами кодирования и декодирования; с методами обработки видео и т. д.
6 Прикладная программа и анализ характеристик
Для получения кадров была написана прикладная программа в среде MS Visual Studio 2017 на языке c# с использованием графического интерфейса (рис. 4,5).
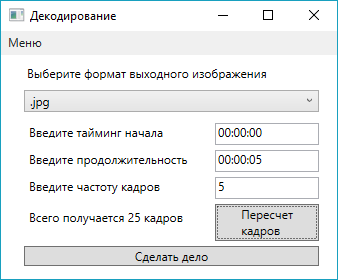
Рис. 4. Главный экран программы
Рис. 5. Меню программы
При включении программы пользователь попадает на главный экран (рис. 4), где можно настроить такие параметры как: формат полученных кадров; промежуток декодирования, частоту кадров в секунду; время в видео, с которого начинается промежуток декодирования; Так же на экран, после нажатия на кнопку «пересчет кадров», выводится количество кадров, которое будет получено в результате выполнения программы. На рис. 2 представлено меню, где можно выбрать видео для декодирования и каталог, куда будут сохраняться полученные кадры. Если не был выбрано видео или каталог, то выводится соответствующее уведомление. После завершения декодирования выводится уведомление о завершении декодирования. Из меню (рис. 5) можно попасть в окно просмотра полученных кадров, на котором можно просмотреть полученные кадры.
В таблице 2 представлен количество полученных кадров при различных параметрах.
Таблица 2
Таблица количества полученных кадров
|
Промежуток времени, сек. Кол-во Кадров/сек., шт. |
5 |
10 |
20 |
30 |
9720 |
|
5 |
25 |
50 |
100 |
150 |
48600 |
|
30 |
150 |
300 |
600 |
900 |
291600 |
|
48 |
240 |
480 |
960 |
1440 |
466560 |
|
60 |
300 |
600 |
1200 |
1800 |
583200 |
Для наглядности был выбран хронометраж фильма «Аватар», равный 162 минутам, и стандартные 48 кадров в секунду для формата «IMAX 3D». Получается, что 466560 кадров просмотрит человек за один киносеанс данного фильма.
В таблице 3 представлены характеристики скорости выполнения программы и объема полученных кадров в зависимости от времени промежутка декодирования при 23 кадрах в секунду. Для работы было использовано видео в формате «mkv» с разрешением 1920х1080 пикселей, объемом 1985мб. и битрейтом 5237кб/с. Формат сохраненных кадров — Jpg.
Таблица 3
Расчет объема кадров ивремени работы программы
|
Время промежутка, сек. |
Скорость выполнения программы, сек. |
Количество полученных кадров, шт. |
Объем полученных кадров, мб. |
Средний объем одного кадра, кб. |
|
5 |
2.12 |
115 |
2.69 |
23.95 |
|
10 |
4.31 |
230 |
4.68 |
20.83 |
|
20 |
8.47 |
460 |
11.5 |
25.6 |
|
60 |
26.13 |
1380 |
39.6 |
29.38 |
|
300 |
128.44 |
6900 |
212 |
31.46 |
|
600 |
266.38 |
13800 |
498 |
36.95 |
|
2649 |
1176.06 |
60927 |
2007 |
33.7 |
Проанализировав таблицу 3, можно сделать вывод, что время промежутка и скорость выполнения программы имеют прямо пропорциональную зависимость с средней погрешностью 0.142.
Средний объем одного кадра, при условии длительности промежутка более одной минуты включительно, составляет 32.87кб. Для получения более точного результата нужно провести больше экспериментов. Таким образом, фильм «Аватар», с указанными выше характеристиками, имеет примерный объем в 14976.39мб.
Объем кадра сильно зависит от то, что происходит в видео. Как пример можно привести 5 кадров между сменой сцен, когда экран становится черным, 5 кадров предыдущей сцены и последующей сцены. Кадрами смены сцен будем считать кадры, на которых нет объектов (черные).
Таблица 4
Вес кадров
|
Номер кадра Сцена |
1 |
2 |
3 |
4 |
5 |
|
Конец предыдущей сцены, кб. |
22.2 |
20.4 |
19 |
17.5 |
13.4 |
|
Смена сцен, кб. |
12.3 |
12.3 |
- |
- |
- |
|
Начало следующей сцены, кб. |
12.5 |
13.9 |
15.9 |
20 |
25.4 |
Из таблицы 3 следует, что на смену сцен уходит всего 2 кадра. Конец сцены идет к затемнению, а начало, наоборот, соответственно объем кадров уменьшается и увеличивается. Из этого можно сделать вывод, что кадры, где преобладает черный цвет, занимают соответственно меньший объем.
Описанная программа позволяет пользователю декодировать видео и использовать полученные кадры для обучения ИНС. Изменяя параметры можно добиться разных наборов обучающих выборок, что позволит анализировать изменение ошибки при обучении ИНС и подобрать параметры, при которых ошибка будет минимальна.
Данную программу можно при необходимости дополнять, добавляя новые параметры декодирования, в рамках возможностей библиотеки FFmpeg, что открывает большие возможности получения более разнообразных обучающих выборок.
Литература:
- Черняк Л. Большие данные–новая теория и практика //Открытые системы. СУБД — 2011. — № 10. — С.18–25.
- Lynch C. Bigdata: Howdoyourdatagrow? // Nature. 2008. Vol. 455. Iss. 7209. Р. 28–29.
- Медетов А. А. термин big data и способы его применения // Молодой ученый. — 216. — № 11. -С. 207–210.
- Канаракус, Крис. Машина Больших Данных. // Сети, № 04, 2011. Открытые системы (1 ноября 2011).
- James Manyika et al. Big data: The next frontier for innovation, competition, and productivity. // McKinsey Global Institute, June, 2011. McKinsey (9 August 2011).
- Мак-Каллок У. С., Питтс В. Логическое исчисление идей, относящихся к нервной активности // Автоматы. Под ред. К. Э. Шеннона и Дж. Маккарти. — М.: Изд-во иностр. лит., 1956. — С. 363–384.
- Горбань А. Н. Обучение нейронных сетей. // -М.: изд. СССР-США СП «Параграф», 1990. -160 с.
