





Рассмотрим общий подход к автоматическому выделению ключевых слов из текстов. Современные алгоритмы извлечения ключевых слов обычно включают в себя 3 последовательных этапа [1]:
1) нахождение кандидатов в ключевые слова;
2) выделение признаков;
3) ранжирование и отсечение.
На этапе нахождения кандидатов в ключевые слова решаются две задачи.
Первая из них — предварительная обработка слов, включающая в себя такие процедуры, как стемминг, лемматизация, выделение коллокаций, устранение неоднозначностей. Стеммингом называется усечение слова до его образующей основы путем отбрасывания суффиксов, приставок и т. д., а лемматизацией — приведение слова к его нормальной форме. Отличие этих двух процедур может проиллюстрировать следующий пример. Словосочетание «ключевые слова извлеклись» после процедуры стемминга будут преобразованы в словосочетание «ключев слов извле». Аналогичное сочетание после процедуры лемматизации будет преобразовано к «ключевое слово извлекаться». Обе эти операции над словами являются языкозависимыми, поскольку требуют знаний о морфологических особенностях языка.
Выделение коллокаций необходимо для того, чтобы алгоритм поиска ключевых слов не разделял семантически связанные устойчивые словосочетания на отдельные составляющие. Задача поиска коллокаций в тексте может быть как языкозависимой (при использовании различных словарей), так и языконезависимой (при использовании статистических методов). Вариант использования различных лингвистических ресурсов исключает возможность неправильного распознавания коллокаций, но обладает следующими проблемами. Составление словарей коллокаций является трудоемкой задачей, требующей найма профессиональных лингвистов. Кроме того, подобные сборники необходимо регулярно обновлять в связи с появлением новых устойчивых словосочетаний. Довольно часто для поиска коллокаций применяют статистические методы, которые в общем случае требуют следующие входные данные:
1) большой неразмеченный корпус текста на требуемом языке;
2) максимальная длина возможной коллокации;
3) минимальная частота совместного появления слов в корпусе при которой их можно считать устойчивым словосочетанием.
Устранение неоднозначностей необходимо в том случае, когда задача подразумевает возможность появления омонимов и необходимость их различия.
Второй частью этапа нахождения кандидатов в ключевые слова является непосредственное разделение текста на отдельные слова и словосочетания для их последующей проверки. Для решения этой подзадачи используют несколько основных подходов. Самый простой из них — процедура токенизации, с помощью которой весь текст разбивается на отдельные слова (в общем случае без выделения словосочетаний). Более сложный способ, который зачастую используется алгоритмами, учитывающими лексический контекст встречающихся рядом слов, называется «скользящим окном». В нем словосочетания образовываются из стоящих рядом слов, попадающих в окно заданной ширины (например, 3 слова). Такой способ порождает большое количество кандидатов в ключевые слова, на что необходимо обращать внимание при выборе алгоритма извлечения ключевых слов. Еще один метод генерации словосочетаний связан с разделением предложений по стоп-словам (малозначащим словам, которые часто являются союзами, предлогами и пр.) и пунктуации. Такой способ позволяет наиболее быстро выделить кандидатов в ключевые словосочетания, но без предварительного этапа объединения коллокаций может срабатывать неправильно. Например, словосочетание «Маша и медведь» будет разбито по стоп-слову «и» на отдельные слова. Кроме того, этот способ является языкозависимым.
На втором этапе для каждого найденного кандидата в ключевые слова выделяются признаки, по которым можно будет оценить степень его важности. Выделяемые признаки можно разбить на 3 категории [2]: синтаксические признаки, статистические признаки, структурные признаки. К синтаксическим признакам относят признак части речи, получаемый с помощью POS-разметки (part-of-speech tagging) и признаки, полученные с помощью различных онтологий и словарей. Извлечение этих признаков является языкозависимым.
К статистическим признакам относят вычисление частоты встречаемости слова в документе и в корпусе документов, длину слова или словосочетания, их схожесть с другими кандидатами. Очевидно, что чем чаще встречается слово внутри документа, тем оно более важно для его описания. С другой стороны, чем чаще слово встречается в других документах, тем менее оно важно для текущего документа. Метрика, учитывающая оба эти условия, называется TF-IDF (Term Frequency — Inverse Document Frequency) и вычисляется следующим образом [3]:
![]()
где ![]() – количество вхождений термина
– количество вхождений термина ![]() в документ
в документ ![]() ,
, ![]() – общее количество слов в документе
– общее количество слов в документе ![]() .
.
![]()
где ![]() – корпус документов,
– корпус документов, ![]() - количество документов в корпусе,
- количество документов в корпусе, ![]() - количество документов, в которые входит термин
- количество документов, в которые входит термин ![]() .
.
![]()
Основание логарифма при вычислении ![]() не имеет значения, потому что метрика TF-IDF является относительной. Кроме того, вычисление
не имеет значения, потому что метрика TF-IDF является относительной. Кроме того, вычисление ![]() можно осуществлять заранее в offline-режиме, так как эта метрика не зависит от конкретного документа, а является характеристикой термина. Часто для больших корпусов используют распределенное вычисление TF-IDF.
можно осуществлять заранее в offline-режиме, так как эта метрика не зависит от конкретного документа, а является характеристикой термина. Часто для больших корпусов используют распределенное вычисление TF-IDF.
Применение структурных признаков обусловлено тем, что важность термина для данного документа зависит от его местоположения. Отмечают, что чаще всего ключевые слова находятся в заголовке и первом параграфе тела документа. В качестве численного структурного признака можно использовать нормализованное расстояние между словом и началом документа (отношение длины цепочки слов от начала документа до текущего слова, деленное на количество слов в документе).
Третьим этапом извлечения ключевых слов является ранжирование и отсечение. На данном этапе с помощью полученных признаков кандидатов в ключевые слова осуществляется их отбор. Обычно применяют один из двух подходов — или использование каких-либо эвристических формул, которые позволяют определить, является ли слово ключевым, или использование методов машинного обучения. Стоит отметить, что для машинного обучения с учителем необходим предварительно размеченный корпус документов с выделенными ключевыми словами. Изначально применение машинного обучения для выделения ключевых слов сводилось к решению задачи бинарной классификации путем различных подходов к обучению классификатора [2]. Использовались наивные байесовские классификаторы, деревья принятия решений, бустинг. Однако такой подход не позволял сравнивать найденные ключевые слова друг с другом и выбирать лучшие из них. Поэтому, впоследствии стали применяться алгоритмы, позволяющие ранжировать ключевые слова попарно (например, алгоритм KEA).
Позднее методы извлечения ключевых слов стали разрабатываться на базе алгоритмов ранжирования из других областей. В качестве примера можно привести графовый алгоритм извлечения ключевых слов TextRank, разработанный как продолжение алгоритма PageRank для ранжирования веб-страниц [5].
Описанные выше этапы работы алгоритмов выделения ключевых слов приведены на рисунке.
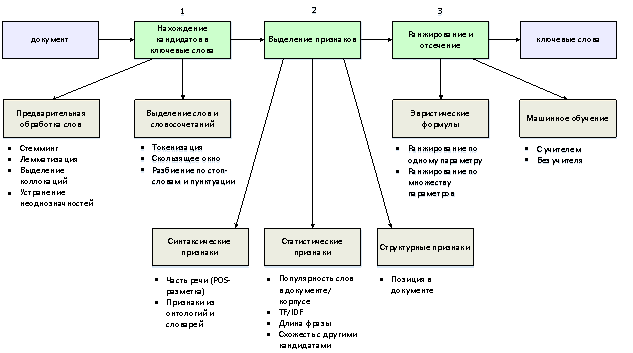 Рис. 1. Этапы извлечения ключевых слов
Рис. 1. Этапы извлечения ключевых слов
Качество работы алгоритмов извлечения ключевых слов часто оценивается с помощью F-меры (F1). На эту метрику влияют два параметра — точность и полнота. В контексте задачи извлечения ключевых слов точность (precision) является отношением правильно найденных ключевых слов ко всем найденным ключевым словам. Полнота (recall) является отношением правильно найденных ключевых слов ко всем ключевым словам, которые должны были быть найдены. F-мера объединяет эти две метрики в одну:
![]()
![]()
![]()
где ![]() – точность,
– точность, ![]() – полнота,
– полнота, ![]() – F-мера,
– F-мера, ![]() – количество верно распознанных ключевых слов (True Positive),
– количество верно распознанных ключевых слов (True Positive), ![]() – количество неверно распознанных ключевых слов (False Positive),
– количество неверно распознанных ключевых слов (False Positive), ![]() – количество нераспознанных ключевых слов (False Negative),
– количество нераспознанных ключевых слов (False Negative), ![]() – параметр приоритета точности или полноты.
– параметр приоритета точности или полноты.
Если параметр ![]() находится в диапазоне
находится в диапазоне ![]() , то приоритет при вычислении F-меры отдается точности, при
, то приоритет при вычислении F-меры отдается точности, при ![]() приоритет отдается полноте. Таким образом, F-мера позволяет избегать проблем с оценкой качества, когда какая-то одна метрика является очень высокой, а вторая очень низкой. Например, если алгоритм нашел лишь одно слово, которое действительно является ключевым, то точность алгоритма будет составлять 100 %, тогда как полнота будет весьма низкой. В этом случае F-мера так же будет низкой.
приоритет отдается полноте. Таким образом, F-мера позволяет избегать проблем с оценкой качества, когда какая-то одна метрика является очень высокой, а вторая очень низкой. Например, если алгоритм нашел лишь одно слово, которое действительно является ключевым, то точность алгоритма будет составлять 100 %, тогда как полнота будет весьма низкой. В этом случае F-мера так же будет низкой.
Таким образом, большинство алгоритмов извлечения ключевых слов состоят из трех последовательных этапов, включающих в себя предварительную обработку данных и выявление кандидатов в ключевые слова, выделение признаков и ранжирование найденных ключевых слов. На выбор алгоритма извлечения ключевых слов должны влиять следующие параметры: доступность размеченных корпусов данных, словарей и онтологий, объемы данных и требующиеся вычислительные ресурсы, наличие специфических особенностей языка. При этом, алгоритм извлечения ключевых слов необходимо оценивать как со стороны точности, так и со стороны полноты, в чем может помочь использование метрики F1.
Литература:
- NLP keyword extraction tutorial with RAKE and Maui // Airpair. URL: https://www.airpair.com/nlp/keyword-extraction-tutorial (дата обращения: 30.05.2017).
- Kazi Saidul Hasan, Vincent Ng. Automatic Keyphrase Extraction: A Survey of the State of the Art. University of Texas at Dallas, Human Language Technology Research Institute. URL: http://acl2014.org/acl2014/P14–1/pdf/P14–1119.pdf (дата обращения 30.05.2017).
- Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze. Introduction to Information Retrieval, Cambridge University Press. 2008.
- Ванюшкин А. С., Гращенко Л. А. Методы и алгоритмы извлечения ключевых слов. URL: http://cyberleninka.ru/article/n/metody-i-algoritmy-izvlecheniya-klyuchevyh-slov (дата обращения 30.05.2017).
- Rada Mihalcea, Paul Tarau. TextRank: Bringing Order into Texts, University of North Texas, 2004. URL: http://www.aclweb.org/anthology/W04–3252 (дата обращения 30.05.2017).
